







一、简介
public class HashMap<K,V>
extends
AbstractMap<K,V>
implements
Map<K,V>,
Cloneable,
Serializable
基于哈希表的 Map 接口的实现。此实现提供所有可选的映射操作,并允许使用null 值和 null 键。(除了非同步和允许使用 null 之外,HashMap 类与 Hashtable 大致相同。)此类不保证映射的顺序,特别是它不保证该顺序恒久不变。
此实现假定哈希函数将元素适当地分布在各桶之间,可为基本操作(get 和 put)提供稳定的性能。迭代 collection 视图所需的时间与HashMap 实例的“容量”(桶的数量)及其大小(键-值映射关系数)成比例。所以,如果迭代性能很重要,则不要将初始容量设置得太高(或将加载因子设置得太低)。
HashMap 的实例有两个参数影响其性能:初始容量 和加载因子。容量 是哈希表中桶的数量,初始容量只是哈希表在创建时的容量。加载因子 是哈希表在其容量自动增加之前可以达到多满的一种尺度。当哈希表中的条目数超出了加载因子与当前容量的乘积时,则要对该哈希表进行rehash 操作(即重建内部数据结构),从而哈希表将具有大约两倍的桶数。
通常,默认加载因子 (.75) 在时间和空间成本上寻求一种折衷。加载因子过高虽然减少了空间开销,但同时也增加了查询成本(在大多数 HashMap 类的操作中,包括get 和 put 操作,都反映了这一点)。在设置初始容量时应该考虑到映射中所需的条目数及其加载因子,以便最大限度地减少 rehash 操作次数。如果初始容量大于最大条目数除以加载因子,则不会发生 rehash 操作。
如果很多映射关系要存储在 HashMap 实例中,则相对于按需执行自动的 rehash 操作以增大表的容量来说,使用足够大的初始容量创建它将使得映射关系能更有效地存储。
注意,此实现不是同步的。
二、构造方法摘要
HashMap() 构造一个具有默认初始容量 (16) 和默认加载因子 (0.75) 的空HashMap。 |
HashMap(int initialCapacity) 构造一个带指定初始容量和默认加载因子 (0.75) 的空HashMap。 |
HashMap(int initialCapacity, float loadFactor) 构造一个带指定初始容量和加载因子的空HashMap。 |
HashMap(Map<? extendsK,? extends V> m) 构造一个映射关系与指定 Map 相同的新 HashMap。 |
三、方法摘要
void | clear() 从此映射中移除所有映射关系。 |
Object | clone() 返回此HashMap 实例的浅表副本:并不复制键和值本身。 |
boolean | containsKey(Object key) 如果此映射包含对于指定键的映射关系,则返回true。 |
boolean | containsValue(Object value) 如果此映射将一个或多个键映射到指定值,则返回true。 |
Set<Map.Entry<K,V>> | entrySet() 返回此映射所包含的映射关系的Set 视图。 |
V | get(Object key) 返回指定键所映射的值;如果对于该键来说,此映射不包含任何映射关系,则返回null。 |
boolean | isEmpty() 如果此映射不包含键-值映射关系,则返回true。 |
Set<K> | keySet() 返回此映射中所包含的键的Set 视图。 |
V | put(K key,V value) 在此映射中关联指定值与指定键。 |
void | putAll(Map<? extendsK,? extends V> m) 将指定映射的所有映射关系复制到此映射中,这些映射关系将替换此映射目前针对指定映射中所有键的所有映射关系。 |
V | remove(Object key) 从此映射中移除指定键的映射关系(如果存在)。 |
int | size() 返回此映射中的键-值映射关系数。 |
Collection<V> | values() 返回此映射所包含的值的Collection 视图。 |
四、部分的代码
package com.jlz;
import java.util.*;
import java.util.Map.Entry;
/**
*
* @author Jlzlight hashmap的遍历
*/
public class TestHashMap {
/**
* @param args
*/
public static void main(String[] args) {
// TODO Auto-generated method stub
HashMap<String, Integer> hm = new HashMap<String, Integer>();
hm.put("one", 1);
hm.put("one", 2);//覆盖one key的值1
hm.put("two", 3);
// EntrySet效率高相比KeySet
Iterator<Entry<String, Integer>> it = hm.entrySet().iterator();
while (it.hasNext()) {
//方法一
Object str = it.next().getKey();
if(str.equals("two"))
System.out.println("通过Key来获取值"+hm.get(str));
//方法二
Entry<String, Integer> e = it.next();
System.out.println("Entry获取Key:"+e.getKey()+"和Value:"+e.getValue());
}
System.out.println("hm.toString"+hm.toString());
System.out.println("Size = "+hm.size());
}
}
五、图文讲解Put方法(盗用)
Put方法的整个处理流程是:计算key的hash值,根据hash值获得key在table数组中的索引位置,然后迭代该key处的Entry链表(我们暂且理解为链表),若该链表中存在一个这个的key对象,那么就直接替换其value值即可,否则在将改key-value节点插入该index索引位置处。如下:
首先我们假设一个容量为5的table,存在8、10、13、16、17、21。他们在table中位置如下:
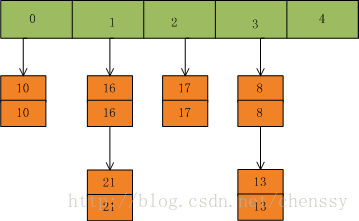
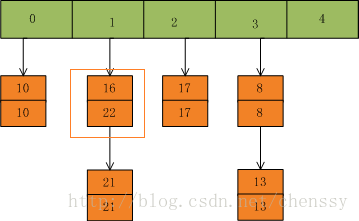
然后我们插入一个数:put(16,22),key=16在table的索引位置为1,同时在1索引位置有两个数,程序对该“链表”进行迭代,发现存在一个key=16,这时要做的工作就是用newValue=22替换oldValue16,并将oldValue=16返回。
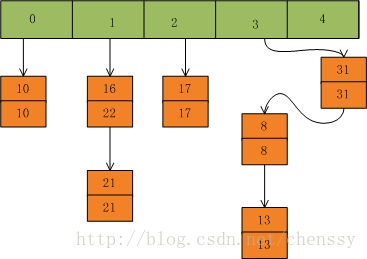
在put(31,31),key=31所在的索引位置为3,并且在该链表中也没有存在某个key=33的节点,所以就将该节点插入该链表的第一个位置。














 3477
3477











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









