








使用Gson实现树型Json数据 非多重List,Map嵌套
这里写代码片最近前端需要json数据,格式比较复杂,里面数组和对象多重嵌套,最初是想构造一个list,map的多重集合,然后通过@ResponseBody直接写到页面的json格式,后来想想就觉得头疼,嵌套太多貌似很傻的写法,然后搜搜json工具,有Jackson,Gson啥的,觉得Gson高大上吧,然后看了看官方文档,喏,就是这个地址,您瞧瞧:http://tool.oschina.net/apidocs/apidoc?api=gson2.2.2 选择JsonWriter即可
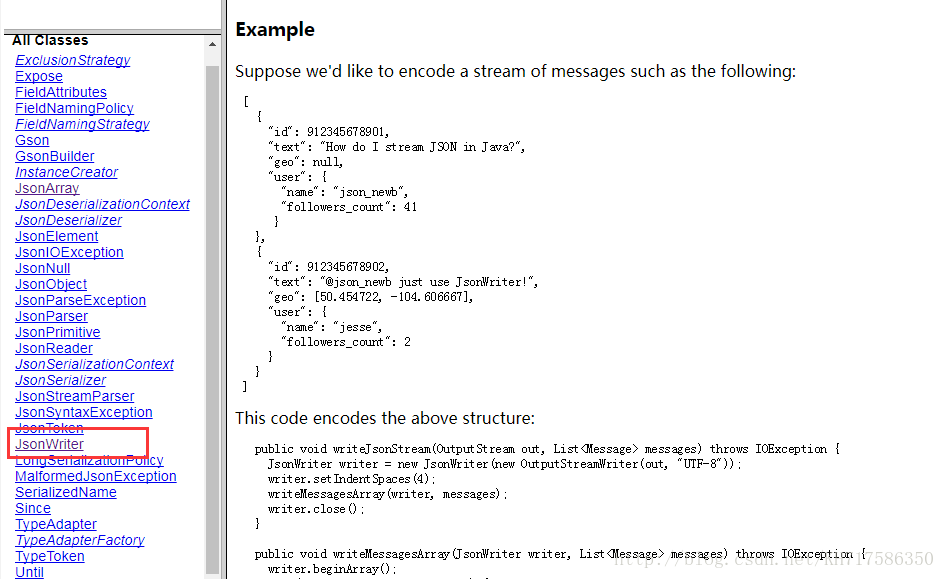
里面有个例子,照着写就好了,这里就几个注意点:
- 必须使用{ }开始,所以必须是writer.beginObject()开始
- 如果begin和end没有对应上,可能读取的数据就不全了
- 对于if else 这种互斥的,需要在每个分支里面end(建议每个分支里面都从begin开始,而不是begin写在分支外面)
下面是例子
需要生成这种类型的json格式
如果是生成这种根据是否有子节点的Json格式的话
{
"conType":[
{
"code":1,
"name":"个人",
"hasChild":0
},
{
"code":2,
"name":"公司",
"hasChild":0
}
],
"dcCity":[
{
"code":244,
"name":"湖北",
"hasChild":[
{
"code":245,
"name":"武汉",
"hasChild":0
},
{
"code":246,
"name":"黄石",
"hasChild":0
},
{
"code":247,
"name":"十堰",
"hasChild":0
},
{
"code":248,
"name":"宜昌",
"hasChild":0
},
{
"code":249,
"name":"襄阳",
"hasChild":0
},
{
"code":250,
"name":"鄂州",
"hasChild":0
},
{
"code":251,
"name":"荆门",
"hasChild":0
},
{
"code":252,
"name":"孝感",
"hasChild":0
},
{
"code":253,
"name":"荆州",
"hasChild":0
},
{
"code":254,
"name":"黄冈",
"hasChild":0
},
{
"code":255,
"name":"咸宁",
"hasChild":0
},
{
"code":256,
"name":"随州",
"hasChild":0
},
{
"code":257,
"name":"恩施",
"hasChild":0
}
]
},
{
"code":426,
"name":"台湾",
"hasChild":0
},
{
"code":427,
"name":"香港",
"hasChild":0
},
{
"code":428,
"name":"澳门",
"hasChild":0
}
]
}Java代码如下
@Test
//将dic_type和dic_data两张表中的数据拼接成为树状目录的json字符串
public void showDic6() {
//数据库查询条件,循环初始时需要clear所有键值,也可以放下面循环中每次新建
Map<String, Object> conditions = new HashMap<>();
//初始化spring容器
ApplicationContext ac = new ClassPathXmlApplicationContext("classpath:spring/applicationContext-dao.xml");
//从容器中获得mapper代理对象
DicTypeMapper typeMapper = ac.getBean(DicTypeMapper.class);
DicDataMapper dataMapper = ac.getBean(DicDataMapper.class);
try {
//创建JsonWriter写入组合的json字符串到io流中
OutputStream out = new ByteArrayOutputStream();
JsonWriter writer = new JsonWriter(new OutputStreamWriter(out , "UTF-8"));
//获的type列表和data列表
List<DicType> dicTypeList = typeMapper.getAllDicType();
List<DicData> dicDataList = dataMapper.getAllDicData();
//开始写入对象,不同类别键名
writer.beginObject();
//遍历type列表,根据id在data列表中查找,在每个[]中存放该类型对应的多条数据
for (DicType type : dicTypeList) {
writer.name(type.getTypeCode()); //写入类别键名
conditions.clear(); //循环初始时,对于多个键值对需要clear之前的值
conditions.put("dtId", type.getId());
List<DicData> dataList = dataMapper.getMultiConditionsDataList(conditions);
//开始写入数组,该类别下的多条数据
writer.beginArray();
//查询数据库该类别的数据
for (DicData dicData : dataList) {
//如果该条数据是子节点,那么就不能写入这个处于父节点的位置
if(dicData.getParentId() != 0) {
continue;
}
//如果该条数据是父节点,找到其下所有子节点写入数组
if(dicData.getHasChild() == 1) {
writer.beginObject(); //开始写入具体数据
writer.name("code").value(dicData.getCode());
writer.name("name").value(dicData.getName());
writer.name("hasChild");
conditions.put("parentId", dicData.getCode());
List<DicData> childList = dataMapper.getMultiConditionsDataList(conditions);
writer.beginArray();
for (DicData child : childList) {
writer.beginObject();
writer.name("code").value(child.getCode());
writer.name("name").value(child.getName());
writer.name("hasChild").value(child.getHasChild());
writer.endObject();
}
writer.endArray();
writer.endObject();
}else {
writer.beginObject();
writer.name("code").value(dicData.getCode());
writer.name("name").value(dicData.getName());
writer.name("hasChild").value(dicData.getHasChild());
writer.endObject();
}
}
writer.endArray();
}
writer.endObject();
writer.flush(); //刷新缓冲到流
System.out.println(out.toString());
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}总结:
- 首先需要分析目标Json数据的格式,对象和数组到底如何嵌套,先整个简单的样本数据分析清楚其结构组织
- 然后就简单了,在{ }地方调用beginObject,[ ]地方调用beginArray,建议和成对写括号一样,同时写出begin和end,避免漏掉end不对应情况
- 最后取出流里面的数据就可以看到生成的Json字符串了
下面这种废弃了,可以参考下如何写这种格式
如果是生成这种Json格式的话
{
"conType":[
{
"name":"个人",
"code":1
},
{
"name":"公司",
"code":2
}
],
"dcCity":[
{
"湖北":[
{
"name":"武汉",
"code":245
},
{
"name":"黄石",
"code":246
},
{
"name":"十堰",
"code":247
},
{
"name":"宜昌",
"code":248
},
{
"name":"襄阳",
"code":249
},
{
"name":"鄂州",
"code":250
},
{
"name":"荆门",
"code":251
},
{
"name":"孝感",
"code":252
},
{
"name":"荆州",
"code":253
},
{
"name":"黄冈",
"code":254
},
{
"name":"咸宁",
"code":255
},
{
"name":"随州",
"code":256
},
{
"name":"恩施",
"code":257
}
]
},
{
"name":"台湾",
"code":426
},
{
"name":"香港",
"code":427
},
{
"name":"澳门",
"code":428
}
]
} @Test
//将dic_type和dic_data两张表中的数据拼接成为树状目录的json字符串
public void showDic5() {
//数据库查询条件,循环初始时需要clear所有键值,也可以放下面循环中每次新建
Map<String, Object> conditions = new HashMap<>();
//初始化spring容器
ApplicationContext ac = new ClassPathXmlApplicationContext("classpath:spring/applicationContext-dao.xml");
//从容器中获得mapper代理对象
DicTypeMapper typeMapper = ac.getBean(DicTypeMapper.class);
DicDataMapper dataMapper = ac.getBean(DicDataMapper.class);
try {
//创建JsonWriter写入组合的json字符串到io流中
OutputStream out = new ByteArrayOutputStream();
JsonWriter writer = new JsonWriter(new OutputStreamWriter(out , "UTF-8"));
//获的type列表和data列表
List<DicType> dicTypeList = typeMapper.getAllDicType();
List<DicData> dicDataList = dataMapper.getAllDicData();
//开始写入对象,不同类别键名
writer.beginObject();
//遍历type列表,根据id在data列表中查找,在每个[]中存放该类型对应的多条数据
for (DicType type : dicTypeList) {
writer.name(type.getTypeCode()); //写入类别键名
conditions.clear(); //循环初始时,对于多个键值对需要clear之前的值
conditions.put("dtId", type.getId());
List<DicData> dataList = dataMapper.getMultiConditionsDataList(conditions);
//开始写入数组,该类别下的多条数据
writer.beginArray();
//查询数据库该类别的数据
for (DicData dicData : dataList) {
//如果该条数据是子节点,那么就不能写入这个处于父节点的位置
if(dicData.getParentId() != 0) {
continue;
}
//如果该条数据是父节点,找到其下所有子节点写入数组
if(dicData.getHasChild() == 1) {
writer.beginObject(); //开始写入具体数据
writer.name(dicData.getName());
conditions.put("parentId", dicData.getCode());
List<DicData> childList = dataMapper.getMultiConditionsDataList(conditions);
writer.beginArray();
for (DicData child : childList) {
writer.beginObject();
writer.name("name").value(child.getName());
writer.name("code").value(child.getCode());
writer.endObject();
}
writer.endArray();
writer.endObject();
}else {
writer.beginObject();
writer.name("name").value(dicData.getName());
writer.name("code").value(dicData.getCode());
writer.endObject();
}
}
writer.endArray();
}
writer.endObject();
writer.flush(); //刷新缓冲到流
System.out.println(out.toString());
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}













 6785
6785











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









