







Python 2,文件开头:# -*- coding: utf-8 -*-,则里面所标注的‘中文’ 为UTF8编码。但u'中文' 为Unicode编码
# 字符串和编码 - 廖雪峰的官方网站
# http://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000/001431664106267f12e9bef7ee14cf6a8776a479bdec9b9000
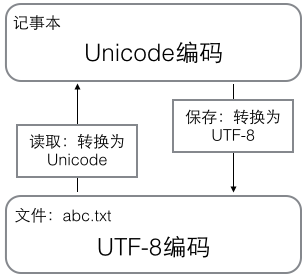
在最新的Python 3版本中,字符串都是以Unicode编码的。ASCII编码是1个字节,而Unicode编码通常是2个字节。(如果要用到非常偏僻的字符,就需要4个字节)
本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节。
| 字符 | ASCII | Unicode | UTF-8 |
|---|---|---|---|
| A | 01000001 | 00000000 01000001 | 01000001 |
| 中 | x | 01001110 00101101 | 11100100 10111000 10101101 |
中
已经超出了ASCII编码的范围,用Unicode编码是十进制的
20013
,二进制的
01001110 00101101
。
#python中文转换url编码(转) - 51CTO技术博客
# http://xiaosu.blog.51cto.com/2914416/1560797网站可接受的编码,在Header-ContentType里指定,一般是utf8,但百度的是gbk
url的地址编码是类似'%E4%B8%BD%E6%B1%9F',是UTF-8的一种变形(\x -> %)
>>> data = '中文' # '\xe6\x9d\xad\xe5\xb7\x9e' # utf-8编码
>>> urllib.quote(data) # '%E6%9D%AD%E5%B7%9E'
>>> data = u'中文' # u'\u4e2d\u6587'
>>> urllib.quote(data.encode('utf8')) # quote函数只接收 UTF8 编码
>>> ord(u'中') # 20013 # Unicode, -> Bin(01001110 00101101) -> Hex(4E2D)
>>> u'中' # u'\u4e2d' Unicode
>>> chr(66) # 'B'ASCII
>>> unichr(25991) # u'\u6587'
print '\xe4\xb8\xad\xe6\x96\x87'.decode('utf-8') # '中文'
那我们想转回去呢?
>>> urllib.unquote('%E6%9D%AD%E5%B7%9E') # '\xe6\x9d\xad\xe5\xb7\x9e' UTF-8
>>> print urllib.unquote('%E6%9D%AD%E5%B7%9E') # '杭州'
如果网站接受的是非utf-8编码,比如GBK,则用:
urllib.quote('中文'.decode('utf-8').encode('gbk')) #'%D6%D0%CE%C4'
urllib.quote(u'中文'.encode('gbk')) #'%D6%D0%CE%C4'
统一转换函数:
print unicode('\xe4\xb8\xad\xe6\x96\x87', 'utf8') # ‘中文’
print unicode('\xd6\xd0\xce\xc4', 'gbk') #‘中文’
print unicode(u'\u4e2d\u6587')














 2353
2353

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









