









对于CSDN博客,我们比较关注的就是文章的访问量和评论量。但是当文章多了之后,我们想看每篇文章的访问量变得很费劲。通过爬虫,我们可以把每篇博客的基本信息都能得到。之后,可以再进行进一步的统计分析。脚本如下:
#!usr/bin/python
# -*- coding: utf-8 -*-
import urllib2
import re
from bs4 import BeautifulSoup
account = "Kevin_zhai"
baseUrl = 'http://blog.csdn.net'
'''
抓取页面信息
'''
def getPage(url):
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = {'User-Agent':user_agent} #伪装成浏览器访问
req = urllib2.Request(url,headers=headers)
myResponse = urllib2.urlopen(req)
myPage = myResponse.read()
return myPage
'''
得到文章分页数目
'''
def getNumber(url):
myPage = getPage(url)
soup = BeautifulSoup(myPage,'html.parser',from_encoding='utf-8') #利用BeautifulSoup解析XML
papeList = soup.find(id="papelist")
numberList = papeList.contents[1].string.strip()
#得到的string “ 97条 共7页”
#用re.split可以匹配多个空格分隔
numberStr = re.split(r'\s+', numberList)[1]
number = numberStr[1:-1]
return number
'''
得到所有文章的阅读量和评论数
'''
def getArticleDetails():
myUrl = baseUrl + '/' +account
number = getNumber(myUrl)
page_num = 1
linkList = []
nameList = []
dateList = []
viewList = []
commentList = []
while page_num <= int(number):
url = myUrl+'/article/list/'+str(page_num) #博客文章列表链接
myPage = getPage(url)
soup = BeautifulSoup(myPage,'html.parser',from_encoding='utf-8')
for h1 in soup.find_all('h1'):
span = h1.contents[1]
link = span.contents[0]['href'].strip() #博客文章链接
name = span.contents[0].string.strip() #博客文章名称
linkList.append(baseUrl+link)
nameList.append(name)
for postdate in soup.find_all(class_="link_postdate"):
publishDate = postdate.get_text() #博客发表日期: 2016-08-22 10:36
dateList.append(publishDate)
for linkview in soup.find_all(class_="link_view"):
view = linkview.get_text() #博客阅读量:42人阅读
viewList.append(view)
for linkcomments in soup.find_all(class_="link_comments"):
comment = linkcomments.get_text() #博客评论量
commentList.append(comment)
page_num = page_num + 1
f = open("E:\ip.txt","w")
for i in range(0,len(nameList)):
string = nameList[i]+'\t'+linkList[i]+'\t'+dateList[i]+'\t'+viewList[i]+'\t'+commentList[i]+'\n'
f.write(code(string))
f.close()
def code(string):
return string.encode("gb18030") #写入文件时转化编码
if __name__ == "__main__":
getArticleDetails()运行后的结果如下:
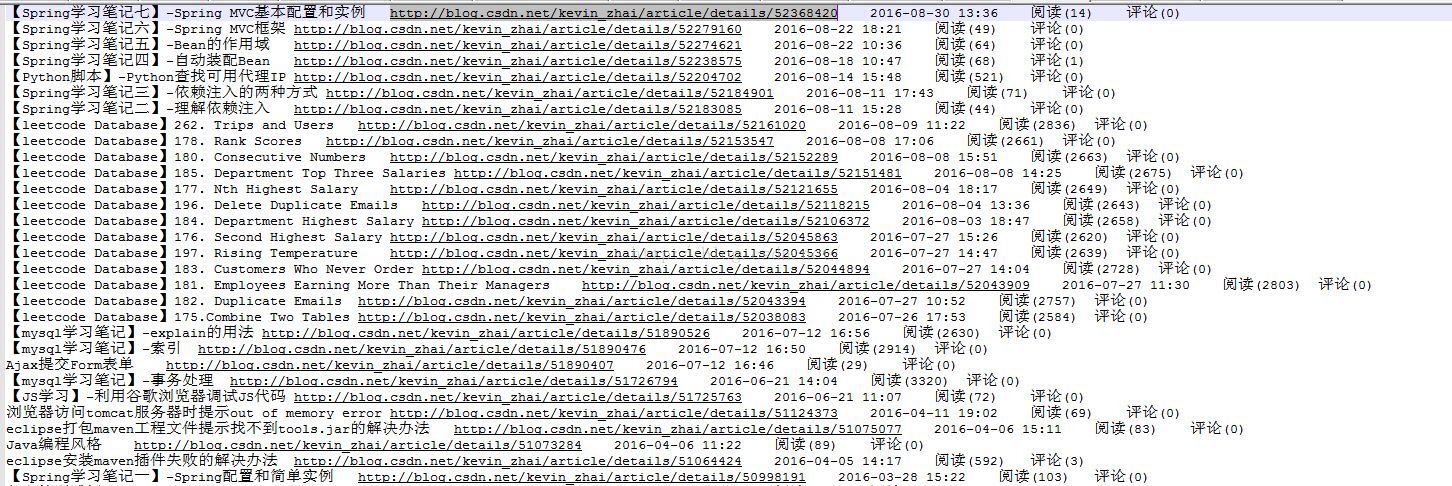














 9507
9507











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









