







本文记录 Kali Linux 2018.1 学习使用和渗透测试的详细过程,教程为安全牛课堂里的《Kali Linux 渗透测试》课程
- Skipfish 简介
- Skipfish 基本操作
- 身份认证
- 提交用户名密码表单
1. Skipfish 简介
-
简介:
Skipfish是一款主动的Web应用程序安全侦察工具。它通过执行递归爬取和基于字典的探测来为目标站点准备交互式站点地图。最终的地图然后用来自许多活动(但希望是不中断的)安全检查的输出来注释。该工具生成的最终报告旨在作为专业Web应用程序安全评估的基础。 -
主要特征:
高速:纯C代码,高度优化的HTTP处理,最小的CPU占用空间 - 轻松实现响应目标的每秒2000个请求。
易于使用:启发式支持各种古怪的Web框架和混合技术站点,具有自动学习功能,动态词汇表创建和表单自动完成功能。
尖端的安全逻辑:高质量,低误报率,差分安全检查,能够发现一系列细微的缺陷,包括盲注入矢量。
2. Skipfish 基本操作
-
帮助信息
• skipfish -o test http://1.1.1.1 • skipfish -o test @url.txt #指定目标IP列表文件 • skipfish -o test -S complet.wl -W abc.wl http://1.1.1.1 #字典 • -I 只检查包含´string´的 URL • -X 不检查包含´string´的URL #例如:logout • -K 不对指定参数进行 Fuzz 测试 • -D 跨站点爬另外一个域 • -l 每秒最大请求数 • -m 每IP最大并发连接数 • --config 指定配置文件 root@kali:~# skipfish --help skipfish web application scanner - version 2.10b Usage: skipfish [ options ... ] -W wordlist -o output_dir start_url [ start_url2 ... ] Authentication and access options: -A user:pass - use specified HTTP authentication credentials -F host=IP - pretend that 'host' resolves to 'IP' -C name=val - append a custom cookie to all requests -H name=val - append a custom HTTP header to all requests -b (i|f|p) - use headers consistent with MSIE / Firefox / iPhone -N - do not accept any new cookies --auth-form url - form authentication URL --auth-user user - form authentication user --auth-pass pass - form authentication password --auth-verify-url - URL for in-session detection Crawl scope options: -d max_depth - maximum crawl tree depth (16) -c max_child - maximum children to index per node (512) -x max_desc - maximum descendants to index per branch (8192) -r r_limit - max total number of requests to send (100000000) -p crawl% - node and link crawl probability (100%) -q hex - repeat probabilistic scan with given seed -I string - only follow URLs matching 'string' -X string - exclude URLs matching 'string' -K string - do not fuzz parameters named 'string' -D domain - crawl cross-site links to another domain -B domain - trust, but do not crawl, another domain -Z - do not descend into 5xx locations -O - do not submit any forms -P - do not parse HTML, etc, to find new links Reporting options: -o dir - write output to specified directory (required) -M - log warnings about mixed content / non-SSL passwords -E - log all HTTP/1.0 / HTTP/1.1 caching intent mismatches -U - log all external URLs and e-mails seen -Q - completely suppress duplicate nodes in reports -u - be quiet, disable realtime progress stats -v - enable runtime logging (to stderr) Dictionary management options: -W wordlist - use a specified read-write wordlist (required) -S wordlist - load a supplemental read-only wordlist -L - do not auto-learn new keywords for the site -Y - do not fuzz extensions in directory brute-force -R age - purge words hit more than 'age' scans ago -T name=val - add new form auto-fill rule -G max_guess - maximum number of keyword guesses to keep (256) -z sigfile - load signatures from this file Performance settings: -g max_conn - max simultaneous TCP connections, global (40) -m host_conn - max simultaneous connections, per target IP (10) -f max_fail - max number of consecutive HTTP errors (100) -t req_tmout - total request response timeout (20 s) -w rw_tmout - individual network I/O timeout (10 s) -i idle_tmout - timeout on idle HTTP connections (10 s) -s s_limit - response size limit (400000 B) -e - do not keep binary responses for reporting Other settings: -l max_req - max requests per second (0.000000) -k duration - stop scanning after the given duration h:m:s --config file - load the specified configuration file Send comments and complaints to <heinenn@google.com>. -
指定输出目录
root@kali:~# skipfish -o test2 http://172.16.10.133/dvwa/ skipfish web application scanner - version 2.10b [!] WARNING: Wordlist '/dev/null' contained no valid entries. Welcome to skipfish. Here are some useful tips: 1) To abort the scan at any time, press Ctrl-C. A partial report will be written to the specified location. To view a list of currently scanned URLs, you can press space at any time during the scan. 2) Watch the number requests per second shown on the main screen. If this figure drops below 100-200, the scan will likely take a very long time. 3) The scanner does not auto-limit the scope of the scan; on complex sites, you may need to specify locations to exclude, or limit brute-force steps. 4) There are several new releases of the scanner every month. If you run into trouble, check for a newer version first, let the author know next. More info: http://code.google.com/p/skipfish/wiki/KnownIssues Press any key to continue (or wait 60 seconds)... skipfish version 2.10b by lcamtuf@google.com - 172.16.10.133 - Scan statistics: Scan time : 0:05:25.024 HTTP requests : 6954 (22.3/s), 162897 kB in, 4840 kB out (516.1 kB/s) Compression : 0 kB in, 0 kB out (0.0% gain) HTTP faults : 2 net errors, 0 proto errors, 0 retried, 0 drops TCP handshakes : 79 total (115.6 req/conn) TCP faults : 0 failures, 2 timeouts, 1 purged External links : 136747 skipped Reqs pending : 2181 Database statistics: Pivots : 315 total, 7 done (2.22%) In progress : 169 pending, 56 init, 77 attacks, 6 dict Missing nodes : 6 spotted Node types : 1 serv, 80 dir, 12 file, 3 pinfo, 107 unkn, 112 par, 0 val Issues found : 33 info, 1 warn, 80 low, 12 medium, 0 high impact Dict size : 219 words (219 new), 14 extensions, 256 candidates Signatures : 77 total [!] Scan aborted by user, bailing out! [+] Copying static resources... [+] Sorting and annotating crawl nodes: 315 [+] Looking for duplicate entries: 315 [+] Counting unique nodes: 314 [+] Saving pivot data for third-party tools... [+] Writing scan description... [+] Writing crawl tree: 315^[[A [+] Generating summary views... [+] Report saved to 'test1/index.html' [0x1d859466]. [+] This was a great day for science! -
浏览器打开此页面
- 扫描了整个站点
- 结果保存在 test1/index.html 中
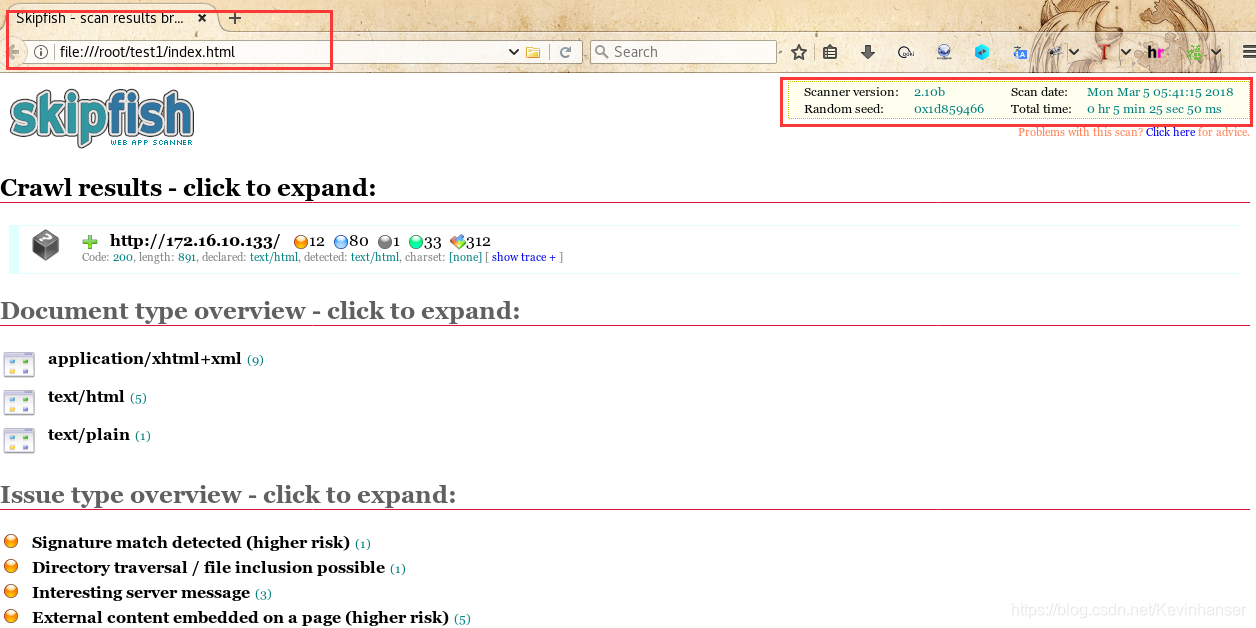
-
只扫描包含 ‘字符串’ 的URL
root@kali:~# skipfish -o test1 -I /dvwa/ http://172.16.10.133/dvwa/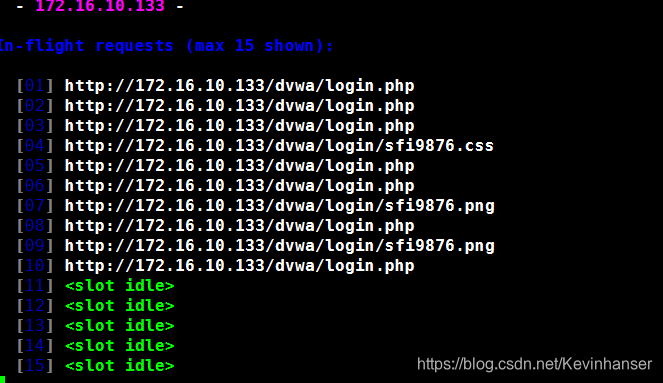
-
指定目标 IP 列表
root@kali:~# vim iplist.txt root@kali:~# cat iplist.txt http://172.16.10.133 http://172.16.10.138 http://172.16.10.139 root@kali:~# skipfish -o test1 @iplist.txt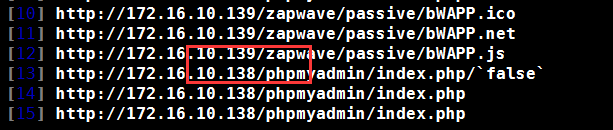
-
指定扫描内容和扫描字典
# 默认扫描使用的字典 root@kali:~# dpkg -L skipfish | grep wl /usr/share/skipfish/dictionaries/medium.wl /usr/share/skipfish/dictionaries/minimal.wl /usr/share/skipfish/dictionaries/extensions-only.wl /usr/share/skipfish/dictionaries/complete.wl # 指定字典 (-S) root@kali:~# skipfish -o test1 -I /dvwa/ -S /usr/share/skipfish/dictionaries/minimal.wl http://172.16.10.133/dvwa/ NOTE: The scanner is currently configured for directory brute-force attacks, and will make about 65130 requests per every fuzzable location. If this is not what you wanted, stop now and consult the documentation. # 将目标网站特有的特征漏洞代码存到文件 (-W) root@kali:~# skipfish -o test1 -I /dvwa/ -S /usr/share/skipfish/dictionaries/minimal.wl -W abc.wl http://172.16.10.133/dvwa/ -
指定最大连接数 (每秒多少个连接)
root@kali:~# skipfish -o test1 -l 2000 -S /usr/share/skipfish/dictionaries/minimal.wl http://172.16.10.133/dvwa/ root@kali:~# skipfish -o test1 -l 10 -S /usr/share/skipfish/dictionaries/minimal.wl http://172.16.10.133/dvwa/ -
指定并发连接数 (并发请求)
root@kali:~# skipfish -o test1 -m 200 -S /usr/share/skipfish/dictionaries/minimal.wl http://172.16.10.133/dvwa/
3. 身份认证###
-
身份认证
- skipfish -A user:pass -o test http://1.1.1.1
- skipfish -C “name=val” -o test http://1.1.1.1
- Username / Password
-
用户名密码验证
root@kali:~# skipfish -A admin:password -I /dvwa/ -o test1 http://172.16.10.133/dvwa/ root@kali:~# skipfish -C "PHPSESSID=a5b1d5b679e934f24bf6ae172dfbf8e0" -C "security=low" -X logout.php -I /dvwa/ -o test1 http://172.16.10.133/dvwa/
4. 提交用户名密码表单###
-
使用 man 手册
root@kali:~# man skipfish -A/--auth <username:password> For sites requiring basic HTTP authentication, you can use this flag to specify your credentials. --auth-form <URL> The login form to use with form authentication. By default skipfish will use the form's action URL to sub‐ mit the credentials. If this is missing than the login data is send to the form URL. In case that is wrong, you can set the form handler URL with --auth-form-target <URL> . --auth-user <username> The username to be used during form authentication. Skipfish will try to detect the correct form field to use but if it fails to do so (and gives an error), then you can specify the form field name with --auth- user-field. --auth-pass <password> The password to be used during form authentication. Similar to auth-user, the form field name can (option‐ ally) be set with --auth-pass-field. --auth-verify-url <URL> This URL allows skipfish to verify whether authentication was successful. This requires a URL where anony‐ mous and authenticated requests are answered with a different response. root@kali:~# skipfish -o test1 --auth-form http://172.16.10.133/dvwa/login.php --auth-form-target http://172.16.10.133/dvwa/login.php --auth-user-field username --auth-user admin --auth-pass-field password --auth-pass password --auth-verify-url http://172.16.10.133/dvwa/index.php -I /dvwa/ -X logout.php http://172.16.10.133/dvwa/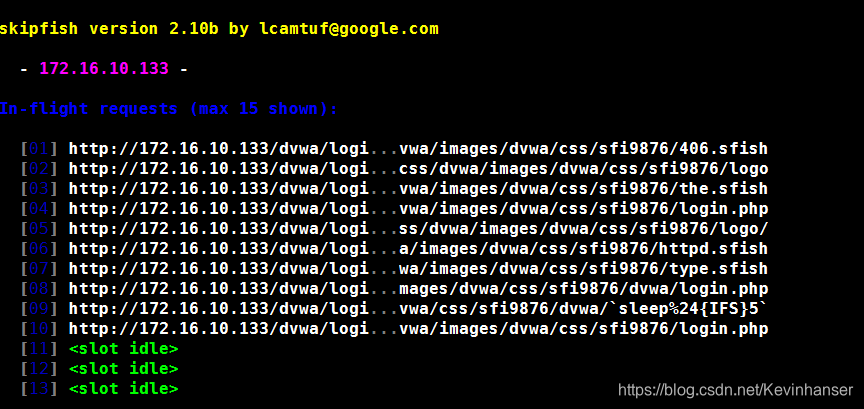














 239
239











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









