







题目解析:
其实就是层序遍历,先遍历完第一层,再遍历完第二层……这时,就要用到数据结构队列:先将根节点入队列,然后出队列,访问节点,将左右子节点入队列,依次循环即可层序访问所有节点。
完整代码如下:
#include<iostream>
#include<cstdio>
#include<cstdlib>
#include<stack>
#include<queue>
using namespace std;
//面试题23从上往下打印二叉树 思路:本质为树的层序遍历,设立一个队列。从上到下访问即可
typedef struct BinaryTreeNode
{
int data;
BinaryTreeNode *left,*right;
}BinaryTreeNode;
void LevelOrder(BinaryTreeNode*pRoot)
{
if(pRoot==NULL)
{
return;
}
BinaryTreeNode *pNode=pRoot;
queue<BinaryTreeNode*> Queue;
Queue.push(pNode);
while(!Queue.empty())
{
pNode=Queue.front();
Queue.pop();
printf("%d\t",pNode->data);
if(pNode->left!=NULL)
{
Queue.push(pNode->left);
}
if(pNode->right!=NULL)
{
Queue.push(pNode->right);
}
}
}
int main()
{
return 0;
}题目:
输入一个整数数组,判断该数组是不是某二叉搜索树的后续遍历的结果。如果是则返回true,否则返回false。假设输入的数组的任意两个数组都互不相同
既然是后序遍历,那么根元素肯定是在最后一个。
又应该为二叉搜索树,所以左边一半的肯定比根要小,右边一半的比根要大。
现在有了根,就可以把剩下的数组根据比根小与比根大的分割线分成两半。
然后再递归判断。
什么时候返回false:
当确定了某个分割点以后,(左边的全比根小,右边的第一个比根大)又在右边的数组中找到一个比根小的,说明该数组不满足二叉搜索树的后序遍历。
#include "stdafx.h"
#include <iostream>
using namespace std;
bool VerifySequenceOfBST(int nSequence[], int nLength)
{
if (nSequence == NULL || nLength <= 0)
{
return false;
}
int nRoot = nSequence[nLength - 1];
int nIndex = 0;
while (nSequence[nIndex] < nRoot)//左子树中结点的值小于根节点的值
{
nIndex++;
}
for (int i=nIndex+1; i<nLength; i++)//右子树中结点的值大于根节点的值
{
if (nSequence[i] < nRoot)
{
return false;
}
}
bool bLeft = true;
if (nIndex > 0)
{
bLeft = VerifySequenceOfBST(nSequence, nIndex);
}
bool bRight = true;
if ((nIndex + 1) < nLength)
{
bRight = VerifySequenceOfBST(nSequence+nIndex, nLength - 1 - nIndex);
}
return (bLeft && bRight);
}
int _tmain(int argc, _TCHAR* argv[])
{
int nArr1[7] = {5, 7, 6, 9, 11, 10, 8};//正确序列,有左右子树
cout << VerifySequenceOfBST(nArr1, 7) << endl;
int nArr2[4] = {7, 4, 6, 5};//错误序列
cout << VerifySequenceOfBST(nArr2, 4) << endl;
int nArr3[3] = {3, 2, 1};//右单支
cout << VerifySequenceOfBST(nArr3, 3) << endl;
int nArr4[3] = {1, 2, 3};//左单支
cout << VerifySequenceOfBST(nArr4, 3) << endl;
int nArr5[1] = {1};//单个结点
cout << VerifySequenceOfBST(nArr5, 1) << endl;
system("pause");
return 0;
}
题目:输入一颗二叉树和一个整数,打印出二叉树中节点值得和为输入整数的所有路径。从熟的根节点开始往下一直到叶节点所经过的节点形成一条路径。
如
10
5 12
4 7
二叉树有两条和为22的路径,一条:10-5-7,另一条10-12
思路:首先要想到的是通过遍历可以找到所有路径,按照先序遍历的思路,先将经过的左节点入栈,如果是进的是叶子节点,则判断和是否符合要求,遍历到右节点时,先回到根节点,出栈,再进栈,判断叶子节点。
当用前序遍历的方式访问到某一结点时,我们把该结点添加到路径上,并累加该结点的值。如果该结点为叶结点并且路径中结点值的和刚好等于输入的整数,则当前的路径符合要求,我们把它打印出来。如果当前结点不是叶结点,则继续访问它的子结点。当前结点访问结束后,递归函数将自动回到它的父结点。因此我们在函数退出之前要在路径上删除当前结点并减去当前结点的值,以确保返回父结点时路径刚好是从根结点到父结点的路径。我们不难看出保存路径的数据结构实际上是一个栈,因为路径要与递归调用状态一致,而递归调用的本质就是一个压栈和出栈的过程。这里没有直接用STL 中的stack的原因是在stack中只能得到栈顶元素,而我们打印路径的时候需要得到路径上的所有结点,因此在代码实现的时候std::stack不是最好的选择。如果你需要在递归中存储路径,不妨使用vector,它可以使用push_back()和pop_back()实现栈一样的操作,又可以随时使用vector<T>::iterator来完成其值的遍历。当然,在递归中记录路径,别忘了在递归的末尾需要把结点从vector中pop()出。
void printPath(BinaryTreeNode *node, vector<int> &path, int currentSum, int expectedSum)
{
if(NULL == node)
return;
if((currentSum + node -> m_nValue) > expectedSum )
return;
path.push_back(node -> m_nValue);
if(node -> m_pLeft == NULL && node -> m_pRight == NULL)
{
if((currentSum + node -> m_nValue) == expectedSum)
{
vector<int>::iterator ite = path.begin();
for(; ite != path.end();ite++)
{
printf("%d", *ite);
}
printf("\n");
}
}
else
{
printPath(node -> pLeft, path, currentSum + node -> m_nValue, expectedSum);
printPath(node -> pRight, path, currentSum + node -> m_nValue, expectedSum);
}
path.pop_back();//这一点至关重要,函数结束必须将当前结点从路径结点中Pop出。
}------------------------------------------------
Felix原创,转载请注明出处,感谢博客园!
struct ComplexListNode
{
int m_nValue ;
ComplexListNode * m_pNext ;
ComplexListNode * m_pSibling ;
} ;下图是一个含有5个结点的该类型复杂链表。实线箭头表示m_pNext指针,虚线箭头表示m_pSibling指针,指向NULL的指针没有画出。
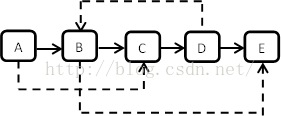
在常见的数据结构上稍加变化,这是一种很新颖的面试题。看到这个问题,我的第一反应是分成两步:第一步是复制原始链表上的每个结点,并用m_pNext链接起来;第二步,假设原始链表中的某节点N的m_pSibling指向结点S。由于S的位置有可能在N的前面也可能在N的后面,所以要定位N的位置需要从原始链表的头结点开始找。假设从原始链表的头结点开始经过s步找到结点S。那么在复制后的链表上结点N’的m_pSibling(记为S’),离头结点的距离也是s。用这种办法就能为复制后的链表的每个结点设置m_pSibling了。
对一个含有n个结点的链表,由于定位每个结点的m_pSibling都需要从链表头结点开始经过O(n)步才能找到,因此这种方法的总时间复杂度是O(n^2)。
由于上述方法的时间主要花在定位结点的m_pSibling上面,我们试着在这方面做优化。还是分两步:第一步仍然是复制原始链表上的每个结点N,并创建N’,然后把这些创建出来的结点链接起来。同时我们把<N, N’>的配对信息放到一个哈希表中。第二步还是设置复制后的链表上每个结点的m_pSibling。如果在原始链表中结点N的m_pSibling指向结点S,那么在复制后的链表中,对应的N’应该指向S’。由于有了哈希表,可以用O(1)的时间根据S找到S’。这种方法相当于用空间换时间,以O(n)的空间消耗把时间复杂度由O(n^2)降低到O(n)。
(注:哈希表中的每一个配对(pair)的Key是原始链表的结点,Value是Key中结点的对应的拷贝结点。这样在哈希表中,就可以在O(1)的时间里,找到原始结点对应的拷贝出来的结点。比如想求得N’的m_pSibling所指向的S’,可以由N的m_pSibling求得S,而<S, S’>的配对信息就在哈希表中,可以用O(1)时间求得。)
在解决复杂问题时,可以将复杂问题分成多个步骤的小问题。然后每一步解决一个小问题,各个击破,这样整个过程的逻辑也会更加清晰明了。计算机中常用的一类算法“分治法”,也是基于这个思想。
下面换一种思路来解决这个问题,在不用辅助空间的情况下实现O(n)的时间效率。第三种方法的第一步仍然是根据原始链表的每个结点N,创建对应的N’。这一次,把N’链接在N的后面。

这一步的代码如下:
void CloneNodes ( ComplexListNode * pHead )
{
ComplexListNode * pNode = pHead ;
while ( pNode != NULL )
{
ComplexListNode * pCloned = new ComplexListNode ( ) ;
pCloned -> m_nValue = pNode -> m_nValue ;
pCloned -> m_pNext = pNode -> m_pNext ;
pCloned -> m_pSibling = NULL ;
pNode -> m_pNext = pCloned ;
pNode = pCloned -> m_pNext ;
}
}第二步是设置复制出来的结点的m_pSibling。假设原始链表上的N的m_pSibling指向结点S,而N对应的复制出来的N’等于N->m_pNext,同样S’就等于S->m_pNext。这就是在上一步中把每个复制出来的结点链接在原始结点后面的原因。有了这样的链接方式,就能在O(1)时间中找到每个结点的m_pSibling了。
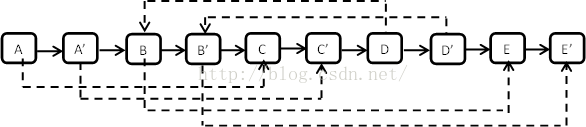
这一步的代码如下:
void ConnectSiblingNodes ( ComplexListNode * pHead )
{
ComplexListNode * pNode = pHead ;
while ( pNode != NULL )
{
ComplexListNode * pCloned = pNode -> m_pNext ;
if ( pNode -> m_pSibling != NULL )
pCloned -> m_pSibling = pNode -> m_pSibling -> m_pNext ;
pNode = pCloned -> m_pNext ;
}
}第三步是把这个长链表拆分成两个:把奇数位置的结点用m_pNext链接起来就是原始链表,把偶数位置的结点m_pNext链接出来就是复制出来的链表。

要实现这一步,也不是很难的事情。其对应的代码如下:
ComplexListNode * ReconnectNodes ( ComplexListNode * pHead )
{
ComplexListNode * pNode = pHead ;
ComplexListNode * pClonedHead = NULL ;
ComplexListNode * pClonedNode = NULL ;
if ( pNode != NULL )
{
pClonedHead = pClonedNode = pNode -> m_pNext ;
pNode -> m_pNext = pClonedNode -> m_pNext ;
pNode = pNode -> m_pNext ;
}
while ( pNode != NULL )
{
pClonedNode -> m_pNext = pNode -> m_pNext ;
pClonedNode = pClonedNode -> m_pNext ;
pNode -> m_pNext = pClonedNode -> m_pNext ;
pNode = pNode -> m_pNext ;
}
return pClonedHead ;
}注:while循环的前两行代码是设置完“复制后的链表”的当前结点的m_pNext之后,将指针pClonedNode后移。后两行代码是设置完“原始链表” 的当前结点的m_pNext之后,将指针pNode后移。以便继续处理,如果一时理解不了,就动笔划一划。)
最后把上面三步合起来,就是复制链表的完整过程:
ComplexListNode * Clone ( ComplexListNode * pHead )
{
CloneNodes ( pHead ) ;
ConnectSiblingNodes ( pHead ) ;
return ReconnectNodes ( pHead ) ;
}题目:输入一棵二叉搜索树,将该二叉搜索树转换成一个排序的双向链表。要求不能创建任何新的结点,只能调整树中结点指针的指向。比如输入下图中左边儿茶搜索树,则输出转换后的排序双向链表。
10
/ \
6 14
/ \ / \
4 8 12 16
4=6=8=10=12=14=16
分析:
1. 二叉树中,每个结点都有两个指向子结点的指针。
2. 在双向链表中,每个结点也有两个指针,分别指向前一个结点和后一个结点。
3. 二叉搜索树中,左子结点的值总是小于父结点的值,右子结点的值总是大于父结点的值。
4. 将二叉搜索树转换为双向链表时,原先指向左子结点的指针调整为链表中指向前一个结点的指针,原先指向右子结点的指针调整为链表中指向后一个结点的指针。
5. 由于要求转换之后的链表是排好序的,所以我们采取中序遍历。
6. 当遍历转换到根结点时,左子树已经转换成了一个排序的链表了,并且处在链表中的最后一个结点是当前值最大的结点,将其与根结点连接起来,接着去遍历转换右子树,并把根结点和右子树中的最小的结点连接起来。
#include "stdafx.h" #include <iostream> using namespace std; struct BinaryTreeNode { int m_nValue; BinaryTreeNode *m_pLeft; BinaryTreeNode *m_pRight; }; void Convert(BinaryTreeNode *pRoot, BinaryTreeNode *&pLastInList) { if (pRoot == NULL) { return; } BinaryTreeNode *pCurrentNode = pRoot; if (pCurrentNode->m_pLeft != NULL) { Convert(pCurrentNode->m_pLeft, pLastInList); } pCurrentNode->m_pLeft = pLastInList; if (pLastInList != NULL) { pLastInList->m_pRight = pCurrentNode; } pLastInList = pCurrentNode; if (pCurrentNode->m_pRight != NULL) { Convert(pCurrentNode->m_pRight, pLastInList); } } BinaryTreeNode *ConvertBSTToDoubleList(BinaryTreeNode *pRoot) { if (pRoot == NULL) { return NULL; } BinaryTreeNode *pLastInList = NULL;//指向排好序的双向链表的最后一个结点 Convert(pRoot, pLastInList); while (pLastInList->m_pLeft != NULL)//返回到头结点 { pLastInList = pLastInList->m_pLeft; } return pLastInList; } //以先序的方式构建二叉树,输入-1表示结点为空 void CreateBinaryTree(BinaryTreeNode *&pRoot) { int nNodeValue = 0; cin >> nNodeValue; if (-1 == nNodeValue) { pRoot = NULL; return; } else { pRoot = new BinaryTreeNode(); pRoot->m_nValue = nNodeValue; CreateBinaryTree(pRoot->m_pLeft); CreateBinaryTree(pRoot->m_pRight); } } void PrintInOrder(BinaryTreeNode *&pRoot)//中序遍历二叉树 { if (pRoot != NULL) { PrintInOrder(pRoot->m_pLeft); cout << pRoot->m_nValue << " "; PrintInOrder(pRoot->m_pRight); } } void PrintDoubleListFromLeftToRight(BinaryTreeNode *pRoot)//从左到右打印双向链表 { if (pRoot == NULL) { return; } BinaryTreeNode *pNode = pRoot; while (pNode != NULL) { cout << pNode->m_nValue << " "; pNode = pNode->m_pRight; } cout << endl; } void PrintDoubleListFromRightToLeft(BinaryTreeNode *pRoot)//从右向左打印双向链表 { if (pRoot == NULL) { return; } BinaryTreeNode *pNode = pRoot; while (pNode->m_pRight != NULL) { pNode = pNode->m_pRight; } while (pNode != NULL) { cout << pNode->m_nValue << " "; pNode = pNode->m_pLeft; } cout << endl; } int _tmain(int argc, _TCHAR* argv[]) { BinaryTreeNode *pRoot = NULL; CreateBinaryTree(pRoot); PrintInOrder(pRoot);//4 6 8 10 12 14 16 cout << endl; BinaryTreeNode *pDoubleListHead = ConvertBSTToDoubleList(pRoot); PrintDoubleListFromLeftToRight(pDoubleListHead);//4 6 8 10 12 14 16 PrintDoubleListFromRightToLeft(pDoubleListHead);//16 14 12 10 8 6 4 system("pause"); return 0; }
【题目】
输入一个字符串,打印出该字符串中字符的所有排列。
【例子】
输入字符串abc,则输出由字符a、b、c所能排列出来的所有字符串abc、acb、bac、bca、cab和cba。
【分析】
这是一道排列组合的题目。而做排列组合的时候头脑要保持清醒并且有序。我们列举一个例子,假设有字符串abc,如果我们手动排列,过程是怎样的呢?
一般人的分析习惯总是把大问题化成小问题来解决。这是我们的习惯。
首先保持a在第一位不动,我们看子字符串bc,bc的排列是bc和cb,这样我们得到结果是abc,acb ;
其次保持b在第一位不东,我们看子字符串ac,ac的排列是ac和ca,这样我们得到结果是bac,bca ;
再次保持c在第一位不东,我们看子字符串ab,ab的排列是ab和ba,这样我们得到结果是cab,cba 。
这样我们都得到三个字符的排列是abc,acb,bac,bca,cab,cba。这样思维是不是很清晰。
参照上面的手工做法,我们如何用程序去实现呢。显然用递归的方式更符合我们的思维。
第一步:当字符串只有1个字符的时候,其排列是字符本身。
第二步:递归求出子字符串的排列
第三步:算法结束。
//k表示当前选取到第几个数,m表示共有多少个数
#define swap(a, b) { char c=a; a=b; b=c; }
void Permutation(char* pStr,int k,int m)
{
assert(pStr);
if(k == m)
{
static int num = 1; //局部静态变量,用来统计全排列的个数
printf("第%d个排列\t%s\n",num++,pStr);
}
else
{
for(int i = k; i <= m; i++)
{
swap(*(pStr+k),*(pStr+i));
Permutation(pStr, k + 1 , m);
swap(*(pStr+k),*(pStr+i));
}
}
}
int main(void)
{
char str[] = "abc";
Permutation(str , 0 , strlen(str)-1);
return 0;
}由于全排列就是从第一个数字起每个数分别与它后面的数字交换。我们先尝试加个这样的判断——如果一个数与后面的数字相同那么这二个数就不交换了。如122,第一个数与后面交换得212、221。然后122中第二数就不用与第三个数交换了,但对212,它第二个数与第三个数是不相同的,交换之后得到221。与由122中第一个数与第三个数交换所得的221重复了。所以这个方法不行。
换种思维,对122,第一个数1与第二个数2交换得到212,然后考虑第一个数1与第三个数2交换,此时由于第三个数等于第二个数,所以第一个数不再与第三个数交换。再考虑212,它的第二个数与第三个数交换可以得到解决221。此时全排列生成完毕。
这样我们也得到了在全排列中去掉重复的规则——去重的全排列就是从第一个数字起每个数分别与它后面非重复出现的数字交换。下面给出完整代码:
#include<iostream>
using namespace std;
#include<assert.h>
#define swap(a, b) { char c=a; a=b; b=c; }
//在[nBegin,nEnd)区间中是否有字符与下标为pEnd的字符相等
bool IsSwap(char* pBegin , char* pEnd)
{
char *p;
for(p = pBegin ; p < pEnd ; p++)
{
if(*p == *pEnd)
return false;
}
return true;
}
void Permutation(char* pStr , char *pBegin)
{
assert(pStr);
if(*pBegin == '\0')
{
static int num = 1; //局部静态变量,用来统计全排列的个数
printf("第%d个排列\t%s\n",num++,pStr);
}
else
{
for(char *pCh = pBegin; *pCh != '\0'; pCh++) //第pBegin个数分别与它后面的数字交换就能得到新的排列
{
if(IsSwap(pBegin , pCh))
{
swap(*pBegin , *pCh);
Permutation(pStr , pBegin + 1);
swap(*pBegin , *pCh);
}
}
}
}
int main(void)
{
char str[] = "baa";
Permutation(str , str);
return 0;
}字符串全排列扩展----八皇后问题
题目:在8×8的国际象棋上摆放八个皇后,使其不能相互攻击,即任意两个皇后不得处在同一行、同一列或者同一对角斜线上。下图中的每个黑色格子表示一个皇后,这就是一种符合条件的摆放方法。请求出总共有多少种摆法。

这就是有名的八皇后问题。解决这个问题通常需要用递归,而递归对编程能力的要求比较高。因此有不少面试官青睐这个题目,用来考察应聘者的分析复杂问题的能力以及编程的能力。
由于八个皇后的任意两个不能处在同一行,那么这肯定是每一个皇后占据一行。于是我们可以定义一个数组ColumnIndex[8],数组中第i个数字表示位于第i行的皇后的列号。先把ColumnIndex的八个数字分别用0-7初始化,接下来我们要做的事情就是对数组ColumnIndex做全排列。由于我们是用不同的数字初始化数组中的数字,因此任意两个皇后肯定不同列。我们只需要判断得到的每一个排列对应的八个皇后是不是在同一对角斜线上,也就是数组的两个下标i和j,是不是i-j==ColumnIndex[i]-Column[j]或者j-i==ColumnIndex[i]-ColumnIndex[j]。
关于排列的详细讨论,详见上面的讲解。
接下来就是写代码了。思路想清楚之后,编码并不是很难的事情。下面是一段参考代码:
#include<iostream>
using namespace std;
int g_number = 0;
void Permutation(int * , int , int );
void Print(int * , int );
void EightQueen( )
{
const int queens = 8;
int ColumnIndex[queens];
for(int i = 0 ; i < queens ; ++i)
ColumnIndex[i] = i; //初始化
Permutation(ColumnIndex , queens , 0);
}
bool Check(int ColumnIndex[] , int length)
{
int i,j;
for(i = 0 ; i < length; ++i)
{
for(j = i + 1 ; j < length; ++j)
{
if( i - j == ColumnIndex[i] - ColumnIndex[j] || j - i == ColumnIndex[i] - ColumnIndex[j]) //在正、副对角线上
return false;
}
}
return true;
}
void Permutation(int ColumnIndex[] , int length , int index)
{
if(index == length)
{
if( Check(ColumnIndex , length) ) //检测棋盘当前的状态是否合法
{
++g_number;
Print(ColumnIndex , length);
}
}
else
{
for(int i = index ; i < length; ++i) //全排列
{
swap(ColumnIndex[index] , ColumnIndex[i]);
Permutation(ColumnIndex , length , index + 1);
swap(ColumnIndex[index] , ColumnIndex[i]);
}
}
}
void Print(int ColumnIndex[] , int length)
{
printf("%d\n",g_number);
for(int i = 0 ; i < length; ++i)
printf("%d ",ColumnIndex[i]);
printf("\n");
}
int main(void)
{
EightQueen();
return 0;
}#include<iostream>
#include<list>
using namespace std;
void sumk(int sum_m, int n)
{
static list<int> indexStack;
if(n<1||sum_m<1)return;
if(sum_m>n)
{
indexStack.push_front(n);
sumk(sum_m-n,n-1);
indexStack.pop_front();
sumk(sum_m,n-1);
}
else
{
cout<<sum_m<<" ";
for(list<int>::iterator iter = indexStack.begin();iter!=indexStack.end();++iter)
cout<<*iter<<" ";
cout<<endl;
}
}
void sumk_m(int sum_m, int n)
{
if(sum_m<=n)
{
cout<<sum_m<<endl;
sumk(sum_m,sum_m-1);
}
else
{
sumk(sum_m,n);
}
}
int main()
{
sumk_m(10, 12); cout<<endl;
sumk_m(10, 10); cout<<endl;
sumk_m(10, 9); cout<<endl;
return 0;
}题目:数组中有一个数字出现的次数超过数组长度的一半,请找出这个数字。例如输入一个长度为9的数组{1,2,3,2,2,5,4,2}。由于数字2在数组中出现了5词,超过数组长度的一半,因此输出2.
思路:
根据数组特点,数组中一个数组出现的次数超过数组长度的一半,即它出现的次数比其他所有数字出现次数的和还要多。
因此,遍历数组时,保留两个值,一个是数组中的一个数字,一个是次数。
当我们遍历到下一个数字的时候,如果下一个数字和我们之前保存的数字相同,则次数加1,;如果下一个数字和我们之前保存的数字不同,则次数减1,。如果次数为0,我们需要保存下一个数字,并把数字设为1,。由于我们要找的数字出现的次数比其他所有数字出现的次数还要多,那么要找的数字肯定是最后一次把次数设为1时对应的数字。
#include "stdio.h"
int Partition(int A[],int low,int high)
{
int pivot=A[low];
while(low <high)
{
while(low<high && A[high]>=pivot) --high;
A[low]=A[high];
while(low<high && A[low]<=pivot) ++low;
A[high]=A[low];
}
A[low]=pivot;
return low;
}
int HalfData(int a[],int len)
{
int start=0;
int end=len-1;
int middle=len >> 1;
int index=Partition(a,start,end);
printf("index1:%d\n",index);
while(index != middle)
{
if(index > middle)
{
end=index-1;
index=Partition(a,start,end);
}
else
{
start=index+1;
index=Partition(a,start,end);
}
}
return a[index];
}
void main()
{
int a[9]={1,2,3,2,2,2,5,4,2};
int len=9;
int result=HalfData(a,9);
printf("result:%d",result);
}#include<iostream>
using namespace std;
void findpath(int * a,int start,int n,int * path,int top,int sum)//start表示每个子问题从数组a的什么位置开始
{
for(int i=start;i<n;i++)
{
sum -= a[i];
path[top++]=i;//path记录每一条经过的路径
if(sum == 0)
{
for(int j=0;j<top;j++)
{
cout<<a[path[j]]<<" ";
}
cout<<endl;
}
else if(sum > 0)
{
findpath(a,i+1,n,path,top,sum);
}
sum +=a[i];
top--;
}
}
int main()
{
int a[]={5,8,6,3,2,4,7,1,9,10};
int path[10]={0};
findpath(a,0,10,path,0,20);
return 0;
}思路一:维护一个maxSize为k的最大堆,用来存放这k个数,遍历数组,如果堆未满,插入堆中。如果堆已满,如果数字比堆的根节点小,则删除堆的根节点,向堆中插入这个数字。
时间复杂度为 O(nlog(k))。如果求最大的k个数,就是使用最小堆了。
这里给出思路一的实现。
如果真正写代码,要知道堆是没有STL的,也就是说我们要自己实现。书中使用了multiset,multiset和set一样,都是基于红黑树实现,区别是set不允许重复而multiset允许重复。
那么multiset和vector区别在哪里?区别在于multiset支持排序。multiset的插入和删除的时间复杂度也都为 O(logk)
附上代码:
typedef multiset<int, greater<int> > intSet;
typedef multiset<int, greater<int> >::iterator setIterator;
void GetLeastNumbers_Solution2(const vector<int>& data, intSet& leastNumbers, int k)
{
leastNumbers.clear();
if(k < 1 || data.size() < k)
return;
vector<int>::const_iterator iter = data.begin();
for(; iter != data.end(); ++ iter)
{
if((leastNumbers.size()) < k)
leastNumbers.insert(*iter);
else
{
setIterator iterGreatest = leastNumbers.begin();
if(*iter < *(leastNumbers.begin()))
{
leastNumbers.erase(iterGreatest);
leastNumbers.insert(*iter);
}
}
}
}题目:输入一个整型数组,数组里有正数也有负数。数组中一个或连续的多个整数组成一个子数组。求所有子数组的和的最大值。要求时间负责度为O(n)。
看到这个题目,我们首先想到的是求出这个整型数组所有连续子数组的和,长度为n的数组一共有 n(n+2)/2个子数组,因此要求出这些连续子数组的和最快也需要O(n^2)的时间复杂度。但是题目要求的O(n)的时间复杂度,因此上述思路不能解决问题。
看到O(n)时间复杂度,我们就应该能够想到我们只能对整个数组进行一次扫描,在扫描过程中求出最大连续子序列和以及子序列的起点和终点位置。假如输入数组为{1,-2,3,10,-4,7,2,-5},我们尝试从头到尾累加其中的正数,初始化和为0,第一步加上1,此时和为1,第二步加上-2,此时和为-1,第三步加上3,此时我们发现-1+3=2,最大和2反而比3一个单独的整数小,这是因为3加上了一个负数,发现这个规律以后我们就重新作出累加条件:如果当前和为负数,那么就放弃前面的累加和,从数组中的下一个数再开始计数。
#include<iostream> #include<stdlib.h> using namespace std; //求最大连续子序列和 int FindGreatestSumOfSubArray(int arry[],int len) { if(arry==NULL||len<=0) return -1; int start=0,end=0;//用于存储最大子序列的起点和终点 int currSum=0;//保存当前最大和 int greatestSum=-10000;//保存全局最大和 for(int i=0;i<len;i++) { if(currSum<0)//如果当前最大和为负数,则舍弃前面的负数最大和,从下一个数开始计算 { currSum=arry[i]; start=i; } else currSum+=arry[i];//如果当前最大和不为负数则加上当前数 if(currSum>greatestSum)//如果当前最大和大于全局最大和,则修改全局最大和 { greatestSum=currSum; end=i; } } cout<<"最大子序列位置:"<<start<<"--"<<end<<endl; return greatestSum; } void main() { int arry[]={1,-2,3,10,-4,7,2,-5}; int len=sizeof(arry)/sizeof(int); //cout<<len<<endl; int sum= FindGreatestSumOfSubArray(arry,len); cout<<"最大子序列和:"<<sum<<endl; system("pause"); }
看过《编程之美》的人,应该都知道书上的解题思路,它总是先从最容易想到的解决方法入手,然后再一直追问,有没有更好的解决方法。我觉得这个解决问题的思路非常好,任何问题都要一遍一遍的推敲,找到最佳的解决方案,从空间和时间上进行双重的优化。
这道题最简单的思路,就是穷举,穷举所有满足条件的数字。其实,仔细想想,穷举有时可以看成是万能的方法,但是效率也是最低的。
bool IsUgly(int number)
{
while(number % 2 == 0)
number /= 2;
while(number % 3 == 0)
number /= 3;
while(number % 5 == 0)
number /= 5;
return (number == 1) ? true : false;
}
int Method1(int index)
{
if(index <= 0)
return 0;
int number = 0;
int uglyFound = 0;
while(uglyFound < index)
{
++number;
if(IsUgly(number))
{
++uglyFound;
}
}
return number;
}上面的方法,效率低的无法让人接受。于是,我们在寻求更好的解决办法。仔细阅读题目,会发现这题貌似有点像找素数的问题,对了,就是这样,我们换个思路,不是去枚举所有符合条件的数,而是去通过条件生成这些数字。根据丑数的定义,丑数应该是另一个丑数乘以2、3或者5的结果(1除外)。因此我们可以创建一个数组,里面的数字是排好序的丑数。里面的每一个丑数是前面的丑数乘以2、3或者5得到的。这个思路的关键点,就是要保证数组里面的丑数是排好序的。假设arr[1..i]是已经排好序的数组,则arr[i]一定是这里面最大的数,那么我们只要去寻找新生成的数字中比arr[i]大的的最小的数。新生成的数是由前面的数字*2或*3或*5得到的。我们定义index2为前面数字*2中的所有数字中满足大于arr[i]的最小的数的下标,index3,index5类似定义,则应该放在arr[i+1]位置的数字便是min(arr[index2]*2,arr[index3]*3,arr[index5]*5)。
注意代码里,index2,index3,index5是维持动态向前的,不会产生无效搜索,因为当前找的数字一定比原来找的要大,所以从上一次找到的下标开始进行搜索就可以了。
具体代码实现如下:
int Min(int a, int b , int c)
{
a=a<b?a:b;
if(c<a) return c;
else return a;
}
int Method2(int Mindex)
{
int index=1;
int *arr= new int[Mindex];
arr[0]=1;
int index2=0, index3=0, index5=0;
while(index<Mindex)
{
int min=Min(arr[index2]*2,arr[index3]*3,arr[index5]*5);
arr[index]=min;
while(arr[index2]*2<=arr[index])
index2++;
while(arr[index3]*3<=arr[index])
index3++;
while(arr[index5]*5<=arr[index])
index5++;
index++;
}
int ans=arr[Mindex-1];
delete arr;
return ans;
}题目:在字符串中找出第一个只出现一次的字符。如输入“abaccdeff”,则输出‘b’。
题目中要求第一个只出现一次的字符,那么就跟字符出现的次数有关。我们考虑如何统计字符出现的次数,然后找出第一个次数为1的那个字符。这里我们需要一个数据容器来保存字符出现次数,并且能够通过字符找出其相对应的次数。哈希表就是一种常用用的容器。
我们可以定义哈希表的键值(Key)是字符的ASCII值,而值(Value)是该字符出现的次数。同时我们需要扫描两次字符串,第一次扫描字符串时,每扫描到一个字符就在哈希表的对应项中把次数加1。接下来第二次扫描的时候,没扫描到一个字符就能在哈希表中得到该字符出现的次数。找出第一个Value为1的那个key就是我们需要找到那个字符。
#include<iostream> #include<cassert> #include<cstdlib> using namespace std; #define HS_TABSIZE 256// #define MAX 10000 int FristNotRepeatChar(char * pString) { assert(pString!=NULL); int hashtable[HS_TABSIZE]; for(int i=0;i<HS_TABSIZE;i++) { hashtable[i]=0; } char *index=pString; for(;*index!='\0';index++) { hashtable[*index]++; } index=pString; for(;*index!='\0';index++) { if(hashtable[*index]==1) return (index-pString); } return -1; } int main(void) { char *str=new char[MAX]; while(cin>>str) { int chr=FristNotRepeatChar(str); cout<<chr<<endl; } delete []str; return 0; } /************************************************************** Problem: 1283 User: 慢跑的小蜗 Language: C++ Result: Accepted Time:70 ms Memory:1520 kb ****************************************************************/
我们以数组{7, 5, 6, 4}为例来分析统计逆序对的过程。每次扫描到一个数字的时候,我们不能拿它和后面的每一个数字作比较,否则时间复杂度就是O(n^5),因此我们可以考虑先比较两个相邻的数字。
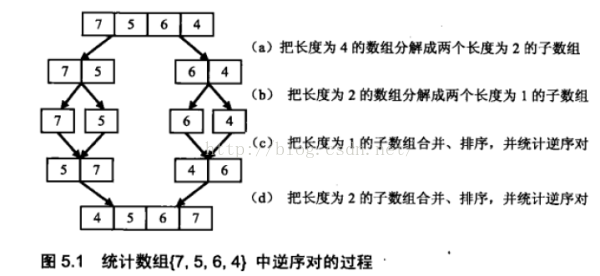
如图5 . 1 ( a )和图5.1 ( b)所示,我们先把数组分解成两个长度为2的子数组, 再把这两个子数组分别拆分成两个长度为1 的子数组。接下来一边合并相邻的子数组, 一边统计逆序对的数目。在第一对长度为1 的子数组{7}、{5}中7 大于5 , 因此(7, 5)组成一个逆序对。同样在第二对长度为1 的子数组{6}、{4}中也有逆序对(6, 4)。由于我们已经统计了这两对子数组内部的逆序对,因此需要把这两对子数组排序( 图5.1 ( c)所示),以免在以后的统计过程中再重复统计。
注 图中省略了最后一步, 即复制第二个子数组最后剩余的4 到辅助数组中.
(a) P1指向的数字大于P2指向的数字,表明数组中存在逆序对.P2 指向的数字是第二个子数组的第二个数字, 因此第二个子数组中有两个数字比7 小. 把逆序对数目加2,并把7 复制到辅助数组,向前移动P1和P3.
(b) P1指向的数字小子P2 指向的数字,没有逆序对.把P2 指向的数字复制到辅助数组,并向前移动P2 和P3 .
(c) P1指向的数字大于P2 指向的数字,因此存在逆序对. 由于P2 指向的数字是第二个子数组的第一个数字,子数组中只有一个数字比5 小. 把逆序对数目加1 ,并把5复制到辅助数组,向前移动P1和P3 .
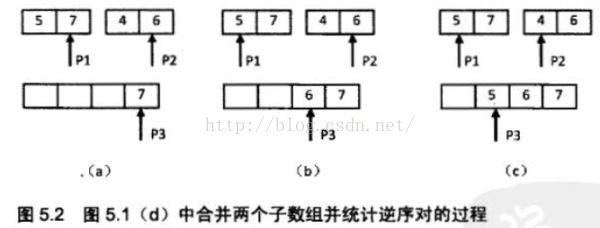
接下来我们统计两个长度为2 的子数组之间的逆序对。我们在图5.2 中细分图5.1 ( d)的合并子数组及统计逆序对的过程。
我们先用两个指针分别指向两个子数组的末尾,并每次比较两个指针指向的数字。如果第一个子数组中的数字大于第二个子数组中的数字,则构成逆序对,并且逆序对的数目等于第二个子数组中剩余数字的个数(如图5.2 (a)和图5.2 (c)所示)。如果第一个数组中的数字小于或等于第二个数组中的数字,则不构成逆序对(如图5.2 (b)所示〉。每一次比较的时候,我们都把较大的数字从·后往前复制到一个辅助数组中去,确保辅助数组中的数字是递增排序的。在把较大的数字复制到辅助数组之后,把对应的指针向前移动一位,接下来进行下一轮比较。
经过前面详细的诗论, 我们可以总结出统计逆序对的过程:先把数组分隔成子数组, 先统计出子数组内部的逆序对的数目,然后再统计出两个相邻子数组之间的逆序对的数目。在统计逆序对的过程中,还需要对数组进行排序。如果对排序贺,法很熟悉,我们不难发现这个排序的过程实际上就是归并排序。
#include<iostream>
#include<stdlib.h>
using namespace std;
void printArray(int arry[],int len)
{
for(int i=0;i<len;i++)
cout<<arry[i]<<" ";
cout<<endl;
}
int MergeArray(int arry[],int start,int mid,int end,int temp[])//数组的归并操作
{
int i=mid;
int j=end;
int k=0;//临时数组末尾坐标
int count=0;
//设定两个指针i j分别指向两段有序数组的头元素,将小的那一个放入到临时数组中去。
while(i>=start&&j>mid)
{
if(arry[i]>arry[j])
{
temp[k++]=arry[i--];//从临时数组的最后一个位置开始排序
count+=j-mid;//因为arry[mid+1...j...end]是有序的,如果arry[i]>arry[j],那么也大于arry[j]之前的元素,从a[mid+1...j]一共有j-(mid+1)+1=j-mid
}
else
{
temp[k++]=arry[j--];
}
}
cout<<"调用MergeArray时的count:"<<count<<endl;
while(i>=start)//表示前半段数组中还有元素未放入临时数组
{
temp[k++]=arry[i--];
}
while(j>mid)
{
temp[k++]=arry[j--];
}
//将临时数组中的元素写回到原数组当中去。
for(i=0;i<k;i++)
arry[end-i]=temp[i];
printArray(arry,8);//输出进过一次归并以后的数组,用于理解整体过程
return count;
}
int InversePairsCore(int arry[],int start,int end,int temp[])
{
int inversions = 0;
if(start<end)
{
int mid=(start+end)/2;
inversions+=InversePairsCore(arry,start,mid,temp);//找左半段的逆序对数目
inversions+=InversePairsCore(arry,mid+1,end,temp);//找右半段的逆序对数目
inversions+=MergeArray(arry,start,mid,end,temp);//在找完左右半段逆序对以后两段数组有序,然后找两段之间的逆序对。最小的逆序段只有一个元素。
}
return inversions;
}
int InversePairs(int arry[],int len)
{
int *temp=new int[len];
int count=InversePairsCore(arry,0,len-1,temp);
delete[] temp;
return count;
}
void main()
{
//int arry[]={7,5,6,4};
int arry[]={1,3,7,8,2,4,6,5};
int len=sizeof(arry)/sizeof(int);
//printArray(arry,len);
int count=InversePairs(arry,len);
//printArray(arry,len);
//cout<<count<<endl;
system("pause");
}-
题目描述:
- 统计一个数字在排序数组中出现的次数。
-
输入:
-
每个测试案例包括两行:
第一行有1个整数n,表示数组的大小。1<=n <= 10^6。
第二行有n个整数,表示数组元素,每个元素均为int。
第三行有1个整数m,表示接下来有m次查询。1<=m<=10^3。
下面有m行,每行有一个整数k,表示要查询的数。
-
输出:
-
对应每个测试案例,有m行输出,每行1整数,表示数组中该数字出现的次数。
-
样例输入:
-
81 2 3 3 3 3 4 513
-
样例输出:
-
4
-
题目分析:
数字在排序数组中出现的次数,第一想法应该是用hash方法,计算出数组中所有数据出现的次数,然后直接查找,时间复杂度O(n),空间复杂度O(n)。但是这种方法未能利用该数组是排序的特点,所以有关排序的题目,要及时联想到二分查找。
本题就是利用的二分查找的一个变体,来求出要查找的数在数组中第一次出现和最后一次出现的位置,来确定数字在数组中出现的次数。
当然在具体写程序的过程还要注意一些临界条件的判断以及特殊情况的处理。二分查找时间复杂度是O(logn),减少了时间复杂度。
来源: <http://blog.csdn.net/hnuzengchao/article/details/44816559>
-
#include "stdio.h" #include "stdlib.h" int GetFirstK(int* data,int length,int k,int start,int end) { if(start > end) return -1; int middleIndex=(start+end)/2; int middleData=data[middleIndex]; if(middleData == k) { if((middleIndex >0 && data[middleIndex - 1]!=k) || middleIndex ==0) return middleIndex; else end =middleIndex - 1; } else if(middleData > k) end =middleIndex -1; else start=middleIndex+1; return GetFirstK(data,length,k,start,end); } int GetLastK(int* data,int length,int k,int start,int end) { if(start > end) return -1; int middleIndex=(start+end)/2; int middleData=data[middleIndex]; if(middleData == k) { if((middleIndex < length-1 && data[middleIndex + 1] !=k) || middleIndex ==length-1) return middleIndex; else start =middleIndex + 1; } else if(middleData < k) start =middleIndex +1; else end=middleIndex-1; return GetLastK(data,length,k,start,end); } int GetNumberOfK(int* data,int length,int k) { int number=0; if(data !=NULL && length >0) { int first=GetFirstK(data,length,k,0,length-1); printf("f:%d\n",first); int last=GetLastK(data,length,k,0,length-1); printf("l:%d\n",last); if(first > -1 && last > -1) number =last - first +1; } return number; } void main() { int a[8]={1,2,3,3,3,3,4,5}; int result=GetNumberOfK(a,8,3); printf("%d",result); }
题目:输入一棵二叉树的根节点,求该树的深度。从根节点到叶子结点一次经过的结点形成树的一条路径,最长路径的长度为树的深度。根节点的深度为1。
解体思路:
- 如果根节点为空,则深度为0,返回0,递归的出口
- 如果根节点不为空,那么深度至少为1,然后我们求他们左右子树的深度,
- 比较左右子树深度值,返回较大的那一个
- 通过递归调用
代码实现
#include<iostream> #include<stdlib.h> using namespace std; struct BinaryTreeNode { int m_nValue; BinaryTreeNode* m_pLeft; BinaryTreeNode* m_pRight; }; //创建二叉树结点 BinaryTreeNode* CreateBinaryTreeNode(int value) { BinaryTreeNode* pNode=new BinaryTreeNode(); pNode->m_nValue=value; pNode->m_pLeft=NULL; pNode->m_pRight=NULL; return pNode; } //连接二叉树结点 void ConnectTreeNodes(BinaryTreeNode* pParent,BinaryTreeNode* pLeft,BinaryTreeNode* pRight) { if(pParent!=NULL) { pParent->m_pLeft=pLeft; pParent->m_pRight=pRight; } } //求二叉树深度 int TreeDepth(BinaryTreeNode* pRoot)//计算二叉树深度 { if(pRoot==NULL)//如果pRoot为NULL,则深度为0,这也是递归的返回条件 return 0; //如果pRoot不为NULL,那么深度至少为1,所以left和right=1 int left=1; int right=1; left+=TreeDepth(pRoot->m_pLeft);//求出左子树的深度 right+=TreeDepth(pRoot->m_pRight);//求出右子树深度 return left>right?left:right;//返回深度较大的那一个 } void main() { // 1 // / \ // 2 3 // /\ \ // 4 5 6 // / // 7 //创建树结点 BinaryTreeNode* pNode1 = CreateBinaryTreeNode(1); BinaryTreeNode* pNode2 = CreateBinaryTreeNode(2); BinaryTreeNode* pNode3 = CreateBinaryTreeNode(3); BinaryTreeNode* pNode4 = CreateBinaryTreeNode(4); BinaryTreeNode* pNode5 = CreateBinaryTreeNode(5); BinaryTreeNode* pNode6 = CreateBinaryTreeNode(6); BinaryTreeNode* pNode7 = CreateBinaryTreeNode(7); //连接树结点 ConnectTreeNodes(pNode1, pNode2, pNode3); ConnectTreeNodes(pNode2, pNode4, pNode5); ConnectTreeNodes(pNode3, NULL, pNode6); ConnectTreeNodes(pNode5, pNode7, NULL ); int depth=TreeDepth(pNode1); cout<<depth<<endl; system("pause"); }
判断树是不是二叉平衡树bool IsBalanced(BinaryTreeNode* pRoot, int* depth) { if(pRoot== NULL) { *depth = 0; return true; } int nLeftDepth,nRightDepth; bool bLeft= IsBalanced(pRoot->m_pLeft, &nLeftDepth); bool bRight = IsBalanced(pRoot->m_pRight, &nRightDepth); if (bLeft && bRight) { int diff = nRightDepth-nLeftDepth; if (diff<=1 || diff>=-1) { *depth = 1+(nLeftDepth > nRightDepth ? nLeftDepth : nRightDepth); return true; } } return false; } bool IsBalanced(BinaryTreeNode* pRoot) { int depth = 0; return IsBalanced(pRoot, &depth); }
题目:整型数组中除了两个数字之外,其他的数字都出现两次,找出这两个只出现一次的数字
思路:利用异或运算的性质:任何一个数字异或自己都等于0;
1.从头到尾依次异或数组中的每个数字,最终得到的结果就是两个只出现一次的数字的异或结果;
2. 异或结果的二进制表示中至少有一位为1,找到结果数字中第一个为1的位的位置,记为第n位;
3. 以第n位是否为1为标准把原数组中的数字分为两个子数组,第一个子数组中的每个数字的第n位都为1,
第二个子数组中的每个数字的第n位都为0;
4. 最后分别对两个子数组进行异或运算,就可以求出两个只出现一次的数字
代码如下:
#include "stdafx.h"
#include <iostream>
using namespace std;
//整型数组中除了两个数字之外,其他的数字都出现两次,找出这两个只出现一次的数字
//要求:时间复杂度O(n),空间复杂度:O(1)
//判断在num的二进制表示中从右边数起的indexBit位是否为1
bool IsBit1(int num, int indexBit)
{
num = num >> indexBit;
return (num & 1);
}
//在num的二进制表示中找到最右边是1的位
int FindFirstBitIs1(int num)
{
int indexBit = 0;
while ((num & 1) == 0)
{
num = num >> 1;
indexBit++;
}
return indexBit;
}
void FindNumsAppearOnce(int nArr[], int nLength, int &num1, int &num2)
{
if (nArr == NULL || nLength < 2)
{
return;
}
int nResultExlusiveOR = 0;//记录数组中所有数进行异或之后的结果
for (int i=0; i<nLength; i++)
{
nResultExlusiveOR ^= nArr[i];
}
int indexBit = FindFirstBitIs1(nResultExlusiveOR);//找到异或结果的二进制表示中最右边1的位置
//根据该位上为1或0将原数组分为两部分,然后对两部分数字分别进行异或运算,得到的两个数即为所求
for (int j=0; j<nLength; j++)
{
if (IsBit1(nArr[j], indexBit))
{
num1 ^= nArr[j];
}
else
{
num2 ^= nArr[j];
}
}
}
int _tmain(int argc, _TCHAR* argv[])
{
int nArr[8] = {2,4,3,6,3,2,5,5};
int nNum1 = 0;
int nNum2 = 0;
FindNumsAppearOnce(nArr, 8, nNum1, nNum2);
cout << "只出现一次的数字为:" << nNum1 << " " << nNum2 << endl;
system("pause");
return 0;
}题目1:输入一个递增排序的数组和一个数字s,在数组中查找两个数,使得他们的和正好是s。如果有多对数字的和等于s,全部输出。
题目2:输入一个正数s,打印所有的和为s的连续正数序列(至少含有两个数)。例如输入15,由于1+2+3+4+5 = 4+5+6 = 7+8 = 15,所以打印三个连续序列,即1-5, 4-6, 7-8。
思路:两个题目的特殊之处,都用黑体标出来了。另外题目一的要求,我略作改动,与原书不同。两个题总体思路都是一致的,两个指针一前一后,根据当前指向或当前范围确定和,在和输入的s比较。如果一致,就输出;如果不一致,就动态调整两个指针。
第一个题目中,前边的指针指向数组最前位置,后边的指针指向数组最后位置,设cursum为两个指针指向的数字之和,cursum>s时,前一个指针后移,否则后一个指针前移。当cursum==s时,输出这两个数字。另外,我们假设输入的数组中不出现重复的数字,那么在输出这两个符合条件的数字后,需要同时移动前后两个指针。按照这个规则移动指针,直到两个指针相遇。这个题目还算简单,这样基本就OK了。
第二个题目中,由于是需要打印连续的正整数序列,所以不需要单独开空间存放数组,直接使用两个int类型的变量即可。两个指针之间的数字之和为cursum,当cursum>s时,前一个指针head移动(只允许后移),否则后一个指针rear移动(也是后移)。当cursum==s时,输出两个指针之间的数字,并同时移动两个指针。
这里还有一点问题,就是什么时候需要停下来。根据题目要求,至少含有两个数的时候,才称为序列。那么两个连续的数字,其和只可能是奇数,且一个是(s+1)/2,另一个是(s-1)/2。考虑到这些以后,我们只需要让rear不超出(s+1)/2即可。
之后的另一个问题就是,怎么保证head和rear不重叠,即保证序列最少包含两个数。可以发现,当两个指针相邻时,如果还没有达到(s+1)/2,那么cursum必然会小于s,这时rear一定会后移。这样就可以保证head在(s+1)/2的范围之内,永远不会与rear重叠。
下面是第一题的代码:
bool FindNumbersWithSum(int data[], int length, int sum, int* num1, int* num2)
{
bool found = false;
if(length < 1 || num1 == NULL || num2 == NULL)
return found;
int ahead = length - 1;
int behind = 0;
while(ahead > behind)
{
long long curSum = data[ahead] + data[behind];
if(curSum == sum)
{
*num1 = data[behind];
*num2 = data[ahead];
found = true;
break;
}
else if(curSum > sum)
ahead --;
else
behind ++;
}
return found;
}下面是第二题的代码:
void FindContinuousSequence(int sum)
{
if(sum < 3)
return;
int small = 1;
int big = 2;
int middle = (1 + sum) / 2;
int curSum = small + big;
while(small < middle)
{
if(curSum == sum)
PrintContinuousSequence(small, big);
while(curSum > sum && small < middle)
{
curSum -= small;
small++;
if(curSum == sum)
PrintContinuousSequence(small, big);
}
big++;
curSum += big;
}
}
void PrintContinuousSequence(int small, int big)
{
for(int i = small; i <= big; ++i)
printf("%d ", i);
printf("\n");
}题目:把n个骰子扔在地上,所有骰子朝上一面的点数之和为S。输入n,打印出S的所有可能的值出现的概率。
分析: 一般来说骰子只有6面,点数为1~6,故n个骰子的最小和为n,最大和为6*n,则n个骰子的点数之和出现的频数可以用一个数组来保存,大小为6*n-n。
- 先把骰子分成两堆,第一堆只有一个,第二堆有n-1个,
- 单独的那一个可能出现1到6的点数,我们需要计算从1-6的每一种点数和剩下的n-1个骰子来计算点数和。
- 还是把n-1个那部分分成两堆,上一轮的单独骰子点数和这一轮的单独骰子点数相加,然后再和剩下的n-2个骰子来计算点数和。
#include <iostream>
#include <cstdio>
using namespace std;
int g_maxValue = 6;
void Probability(int original, int current, int sum, int *pProbabilities)
{
if (current == 1)
{
pProbabilities[sum - original]++;
}
else
{
for (int i = 1; i <= g_maxValue; ++i)
{
Probability(original, current - 1, i + sum, pProbabilities);
}
}
}
void Probability(int number, int *pProbabilities)
{
for (int i = 1; i <= g_maxValue; ++i)
{
Probability(number, number, i, pProbabilities);
}
}
void PrintProbability(int number)
{
if (number < 1)
{
return;
}
int maxSum = number * g_maxValue;
int *pProbabilities = new int[maxSum - number + 1];
for (int i = number; i <= maxSum; ++i)
{
pProbabilities[i - number] = 0;
}
Probability(number, pProbabilities);
int total = pow( (double)g_maxValue, number);
for (int i = number; i <= maxSum; ++i)
{
double ratio = (double)pProbabilities[i - number] / total;
printf("%d: %e\n", i, ratio);
}
delete[] pProbabilities;
}
int main()
{
PrintProbability(6);
return 0;
}- 用两个数组来存储骰子点数的每一种出现的次数。
- 在一次循环中,第一个数组中的第n个数字表示骰子和为n出现的次数。
- 在下一次循环中我们加上一个新的骰子,此时和为n的骰子出现的次数应该等于上一次循环中骰子点数和为n-1、n-2、n-3、n-4、n-5与n-6的次数的综合,所以我们把另一个数组的第n个数字设为前一个数组对应的第n-1、n-2、n-3、n-4、n-5与n-6之和。
#include <iostream>
#include <cstdio>
using namespace std;
int g_maxValue = 6;
void PrintProbability(int number)
{
if (number < 1)
{
return ;
}
int *pProbabilities[2];
pProbabilities[0] = new int[g_maxValue * number + 1];
pProbabilities[1] = new int[g_maxValue * number + 1];
for (int i = 0; i < g_maxValue; ++i)
{
pProbabilities[0][i] = 0;
pProbabilities[1][i] = 0;
}
int flag = 0;
for (int i = 1; i <= g_maxValue; ++i)
{
pProbabilities[flag][i] = 1;
}
for (int k = 2; k <= number; ++k)
{
for (int i = 0; i < k; ++i)
{
pProbabilities[1 - flag][i] = 0;
}
for (int i = k; i <= g_maxValue * k; ++i)
{
pProbabilities[1 - flag][i] = 0;
for (int j = 1; j <= i && j <= g_maxValue; ++j)
{
pProbabilities[1 - flag][i] += pProbabilities[flag][i - j];
}
}
flag = 1 - flag;
}
double total = pow( (double)g_maxValue, number);
for (int i = number; i <= g_maxValue * number; ++i)
{
double ratio = (double)pProbabilities[flag][i] / total;
printf("%d: %e\n", i, ratio);
}
delete[] pProbabilities[0];
delete[] pProbabilities[1];
}
int main()
{
PrintProbability(6);
return 0;
}题目:从扑克牌中随机抽5张牌,判断是不是一个顺子,即这5张牌是不是连续的。2~10为数字本身,A为1,J为11,Q为12,K为13,而大小王可以看成是任意数字。
思路:
1,首先把数组排序,然后统计数组中0的个数和数组中不连续数之间的距离。如果空缺距离小于或者等于0的个数,则是连续的。否则是非连续的。
2,判断条件
a,数组为空
b,长度《1
c,相同数字不连续(重要)
#include "stdio.h"
#include "stdlib.h"
#include "string.h"
int compare(const void *arg1,const void *arg2)
{
return *(int*)arg1 - *(int*)arg2;
}
void print(int* numbers,int length)
{
for(int i=0;i<length;i++)
printf("%d ",numbers[i]);
printf("\n");
}
bool IsContinuous(int* numbers,int length)
{
if(numbers ==NULL || length < 0)
return false;
qsort(numbers,length,sizeof(int),compare);
print(numbers,length);
int numberOfZero=0;
int numberOfGap=0;
for(int i=0;i<length && numbers[i] ==0;++i)
++numberOfZero;
for(i=1;i<length;i++)
{
if(numbers[i] == numbers[i-1])
return false;
numberOfGap+=numbers[i]-numbers[i-1]-1;
}
if(numberOfZero >= numberOfGap)
return true;
else
return false;
}
void main()
{
int a[5]={1,2,5,4,0};
bool result=IsContinuous(a,5);
printf("%d\n",result);
}
接下来我们试着从数学上分析出一些规律。首先定义最初的n个数字(0,1,…,n-1)中最后剩下的数字是关于n和m的方程为f(n,m)。
在这n个数字中,第一个被删除的数字是m%n-1,为简单起见记为k。那么删除k之后的剩下n-1的数字为0,1,…,k-1,k+1,…,n-1,并且下一个开始计数的数字是k+1。相当于在剩下的序列中,k+1排到最前面,从而形成序列k+1,…,n-1,0,…k-1。该序列最后剩下的数字也应该是关于n和m的函数。由于这个序列的规律和前面最初的序列不一样(最初的序列是从0开始的连续序列),因此该函数不同于前面函数,记为f’(n-1,m)。最初序列最后剩下的数字f(n,m)一定是剩下序列的最后剩下数字f’(n-1,m),所以f(n,m)=f’(n-1,m)。
接下来我们把剩下的的这n-1个数字的序列k+1,…,n-1,0,…k-1作一个映射,映射的结果是形成一个从0到n-2的序列:
k+1 -> 0
k+2 -> 1
…
n-1 -> n-k-2
0 -> n-k-1
…
k-1 -> n-2
把映射定义为p,则p(x)= (x-k-1)%n,即如果映射前的数字是x,则映射后的数字是(x-k-1)%n。对应的逆映射是p-1(x)=(x+k+1)%n。
由于映射之后的序列和最初的序列有同样的形式,都是从0开始的连续序列,因此仍然可以用函数f来表示,记为f(n-1,m)。根据我们的映射规则,映射之前的序列最后剩下的数字f’(n-1,m)= p-1 [f(n-1,m)]=[f(n-1,m)+k+1]%n。把k=m%n-1代入得到f(n,m)=f’(n-1,m)=[f(n-1,m)+m]%n。
经过上面复杂的分析,我们终于找到一个递归的公式。要得到n个数字的序列的最后剩下的数字,只需要得到n-1个数字的序列的最后剩下的数字,并可以依此类推。当n=1时,也就是序列中开始只有一个数字0,那么很显然最后剩下的数字就是0。我们把这种关系表示为:
0 n=1 //递归基准情况
f(n,m)={
[f(n-1,m)+m]%n n>1
尽管得到这个公式的分析过程非常复杂,但它用递归或者循环都很容易实现。最重要的是,这是一种时间复杂度为O(n),空间复杂度为O(1)的方法,因此无论在时间上还是空间上都优于前面的思路。
int LastRemaining(unsigned int n, unsigned int m)
{
if(n < 1 | rn < l)
return -l;
int last = 0;
for (int i = 2; i<= n; i ++)
last = (last + m) %i;
return last;
}atoi()函数
原型:int atoi (const char *nptr)
用法:#include <stdlib.h>
功能:将字符串转换成整型数;atoi()会扫描参数nptr字符串,跳过前面的空格字符,直到遇上数字或正负号才开始做转换,而再遇到非数字或字符串时('\0')才结束转化,并将结果返回。
说明:atoi()函数返回转换后的整型数。
#include "stdafx.h"
#include <stdio.h>
#include <stdlib.h>
bool g_bInvalidInput = FALSE;
int StrToInt(const char * pstr)
{
g_bInvalidInput = FALSE;
bool bNegtive = FALSE;
int result = 0; //任性的不考虑long long,累不累呀?
if ( pstr == NULL || pstr == '\0' )
{
g_bInvalidInput = TRUE;
return 0; //返回0时需要查找标志位
}
while( *pstr == ' ' )
pstr++; //跳过空格
if ( *pstr == '+' )
bNegtive = FALSE;
else if (*pstr == '-')
{
bNegtive = TRUE; //记录正负号
}
while( *pstr != '\0' ) //循环计算
{
if (*pstr >= '0' && *pstr <= '9' ) //有效范围内进行转换
{
if (bNegtive) //如果是负数则每新增部分均乘以-1
result = result * 10 + (-1) * ( *pstr - '0' );
else
result = result * 10 + *pstr - '0';
if ( (bNegtive && result <( unsigned int )0x80000000) ||
(!bNegtive && result > 0x7ffffff) ) //判断是否溢出,负数小于0x80000000,正数大于0x7fffffff均为溢出
{
result = 0; //已经无法恢复为上一位,干脆赋值为0
break;
}
}
else
{
break; //此处不应该将result赋值为0,那样不符合atoi的定义
}
}
return result; //如果是0的话,需要用户去查下定义。
}
// ====================测试代码====================
void Test(char* string)
{
int result = StrToInt(string);
if(result == 0 && g_nStatus == kInvalid)
printf("the input %s is invalid.\n", string);
else
printf("number for %s is: %d.\n", string, result);
}
int _tmain(int argc, _TCHAR* argv[])
{
Test(NULL);
Test("");
Test("123");
Test("+123");
Test("-123");
Test("1a33");
Test("+0");
Test("-0");
//有效的最大正整数, 0x7FFFFFFF
Test("+2147483647");
Test("-2147483647");
Test("+2147483648");
//有效的最小负整数, 0x80000000
Test("-2147483648");
Test("+2147483649");
Test("-2147483649");
Test("+");
Test("-");
return 0;
}情况一:root未知,但是每个节点都有parent指针
此时可以分别从两个节点开始,沿着parent指针走向根节点,得到两个链表,然后求两个链表的第一个公共节点,这个方法很简单,不需要详细解释的。
情况二:节点只有左、右指针,没有parent指针,root已知
思路:有两种情况,一是要找的这两个节点(a, b),在要遍历的节点(root)的两侧,那么这个节点就是这两个节点的最近公共父节点;
二是两个节点在同一侧,则 root->left 或者 root->right 为 NULL,另一边返回a或者b。那么另一边返回的就是他们的最小公共父节点。
递归有两个出口,一是没有找到a或者b,则返回NULL;二是只要碰到a或者b,就立刻返回。
// 二叉树结点的描述
typedef struct BiTNode
{
char data;
struct BiTNode *lchild, *rchild; // 左右孩子
}BinaryTreeNode;
// 节点只有左指针、右指针,没有parent指针,root已知
BinaryTreeNode* findLowestCommonAncestor(BinaryTreeNode* root , BinaryTreeNode* a , BinaryTreeNode* b)
{
if(root == NULL)
return NULL;
if(root == a || root == b)
return root;
BinaryTreeNode* left = findLowestCommonAncestor(root->lchild , a , b);
BinaryTreeNode* right = findLowestCommonAncestor(root->rchild , a , b);
if(left && right)
return root;
return left ? left : right;
}// 二叉树是个二叉查找树,且root和两个节点的值(a, b)已知
BinaryTreeNode* findLowestCommonAncestor(BinaryTreeNode* root , BinaryTreeNode* a , BinaryTreeNode* b)
{
char min , max;
if(a->data < b->data)
min = a->data , max = b->data;
else
min = b->data , max = a->data;
while(root)
{
if(root->data >= min && root->data <= max)
return root;
else if(root->data < min && root->data < max)
root = root->rchild;
else
root = root->lchild;
}
return NULL;
}













 600
600











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









