









转载:Redis2.2.2源码学习——aeEvent事件轮询
转载:【Redis源码剖析】 - Redis之事务的实现原理
一、Redis的事件
Redis是单线程模型(虚拟内存等功能会启动其它线程(进程)),通过事件机制异步地处理所有请求。 Redis的事件模型在不同的操作系统中提供了不同的实现,ae_epoll.h/ae_epoll.c为epoll的实现,ae_select.h/ae_select.c是select的实现,ae_kqueue.h/ae_kqueue.c是bsd中kqueue的实现。
基本事件
Redis提供两种基本事件:FileEvent和TimeEvent。前者是基于操作系统的异步机制(epoll/kqueue)实现的文件事件,后者是Redis自己实现的定时器。 aeEventLoop是事件模型中最基本的结构体:
typedef struct aeEventLoop {
int maxfd;
long long timeEventNextId;
aeFileEvent events[AE_SETSIZE]; /* Registered events */
aeFiredEvent fired[AE_SETSIZE]; /* Fired events */
aeTimeEvent *timeEventHead;
int stop;
void *apidata; /* This is used for polling API specific data */
aeBeforeSleepProc *beforesleep;
} aeEventLoop;typedef struct aeFileEvent {
int mask; /* one of AE_(READABLE|WRITABLE) */
aeFileProc *rfileProc;
aeFileProc *wfileProc;
void *clientData;
} aeFileEvent;typedef struct aeTimeEvent {
long long id; /* time event identifier. */
long when_sec; /* seconds */
long when_ms; /* milliseconds */
aeTimeProc *timeProc;
aeEventFinalizerProc *finalizerProc;
void *clientData;
struct aeTimeEvent *next;
} aeTimeEvent;二、Redis的事件循环
“Redis在处理请求时完全是用单线程异步模式,通过epoll监听所有连接的读写事件,并通过相应的响应函数处理。Redis使用这样的设计来满足需求,很大程度上因为它服务的是高并发的短连接,且请求处理事件非常短暂。这个模型下,一旦有请求阻塞了服务,整个Redis的服务将受影响。Redis采用单线程模型可以避免系统上下文切换的开销。”
在 redis-server 启动时,首先会初始化一些 redis 服务的配置,最后会调用 aeMain 函数陷入 aeEventLoop循环中,等待外部事件的发生:
int main(int argc, char **argv) {
// ...
initServer();
// ....
aeSetBeforeSleepProc(server.el,beforeSleep);
aeMain(server.el);
aeDeleteEventLoop(server.el);
}该函数负责许多功能,例如处理已经
ready
的客户端连接,处理虚拟内存的换入换出机制,处理
aof
等等。
void aeMain(aeEventLoop *eventLoop) {
eventLoop->stop = 0;
while (!eventLoop->stop) {
if (eventLoop->beforesleep != NULL)
eventLoop->beforesleep(eventLoop);
aeProcessEvents(eventLoop, AE_ALL_EVENTS);
}
} aeProcessEvents函数首先会处理定时器事件,然后是io事件,下面介绍这个函数的实现。
int processed = 0, numevents;
/* Nothing to do? return ASAP */
if (!(flags & AE_TIME_EVENTS) && !(flags & AE_FILE_EVENTS)) return 0; 首先,声明变量记录处理的事件个数,以及触发的事件。flags表示此轮需要处理的事件类型,如果不需要处理定时器事件和io事件直接返回。
redis中的定时器事件是通过epoll实现的。大体思路是,在每次事件迭代调用epoll_wait时需要指定此轮sleep的时间。如果没有io事件发生,则在sleep时间到了之后会返回。通过算出下一次最先发生的事件,到当前时间的间隔,用这个值设为sleep,这样就可以保证在事件到达后回调其处理函数。但是,由于每次返回后,还有处理io事件,所以定时器的触发事件是不精确的,一定是比预定的触发时间晚的。下面看下具体实现。
/* Note that we want call select() even if there are no
* file events to process as long as we want to process time
* events, in order to sleep until the next time event is ready
* to fire. */
// 在两种情况下进入poll,阻塞等待事件发生:
// 1)在有需要监听的描述符时(maxfd != -1)
// 2)需要处理定时器事件,并且DONT_WAIT开关关闭的情况下
if (eventLoop->maxfd != -1 ||
((flags & AE_TIME_EVENTS) && !(flags & AE_DONT_WAIT))) {
int j;
aeTimeEvent *shortest = NULL;
struct timeval tv, *tvp;
// 根据最快发生的定时器事件的发生时间,确定此次poll阻塞的时间
if (flags & AE_TIME_EVENTS && !(flags & AE_DONT_WAIT))
// 线性查找最快发生的定时器事件
shortest = aeSearchNearestTimer(eventLoop);
if (shortest) {
// 如果有定时器事件,则根据它触发的时间,计算sleep的时间(ms单位)
long now_sec, now_ms;
/* Calculate the time missing for the nearest
* timer to fire. */
aeGetTime(&now_sec, &now_ms);
tvp = &tv;
tvp->tv_sec = shortest->when_sec - now_sec;
if (shortest->when_ms < now_ms) {
tvp->tv_usec = ((shortest->when_ms+1000) - now_ms)*1000;
tvp->tv_sec --;
} else {
tvp->tv_usec = (shortest->when_ms - now_ms)*1000;
}
if (tvp->tv_sec < 0) tvp->tv_sec = 0;
if (tvp->tv_usec < 0) tvp->tv_usec = 0;
} else {
// 如果没有定时器事件,则根据情况是立即返回,或者永远阻塞
/* If we have to check for events but need to return
* ASAP because of AE_DONT_WAIT we need to set the timeout
* to zero */
if (flags & AE_DONT_WAIT) {
tv.tv_sec = tv.tv_usec = 0;
tvp = &tv;
} else {
/* Otherwise we can block */
tvp = NULL; /* wait forever */
}
}
由于文件事件触发条件较多,并且 OS 底层实现差异性较大,底层的 I/O 多路复用模块使用了 eventLoop->aeFiredEvent 保存对应的文件描述符以及事件,将信息传递给上层进行处理,并抹平了底层实现的差异。整个 I/O 多路复用模块在事件循环看来就是一个输入事件、输出 aeFiredEvent 数组的一个黑箱。
首先是,查找下一次最先发生的定时器事件,以确定sleep的事件。如果没有定时器事件,则根据传入的flags,选择是一直阻塞指导io事件发生,或者是不阻塞,检查完立即返回。通过调用aeSearchNearestTimer函数查找最先发生的事件,采用的是线性查找的方式,复杂度是O(n),可以将定时器事件组织成堆,加快查找。不过,redis中只有一个serverCron定时器事件,所以暂时不需优化。
三、Redis的定时事件——serverCron线程
所有的时间事件都是保存在链表中的,新的时间事件总是插入到链表的头部,所以时间事件按ID逆序排列 。
时间事件都是通过aeCreateTimeEvent函数创建起来的
long long aeCreateTimeEvent(aeEventLoop *eventLoop, long long milliseconds,aeTimeProc *proc, void *clientData,aeEventFinalizerProc *finalizerProc)
{
te = zmalloc(sizeof(*te));
//设置事件参数
te->id = id;
aeAddMillisecondsToNow(milliseconds,&te->when_sec,&te->when_ms);
te->timeProc = proc;
te->finalizerProc = finalizerProc;
te->clientData = clientData;
//将事件插入到链表头部
te->next = eventLoop->timeEventHead;
eventLoop->timeEventHead = te;
return id;
}
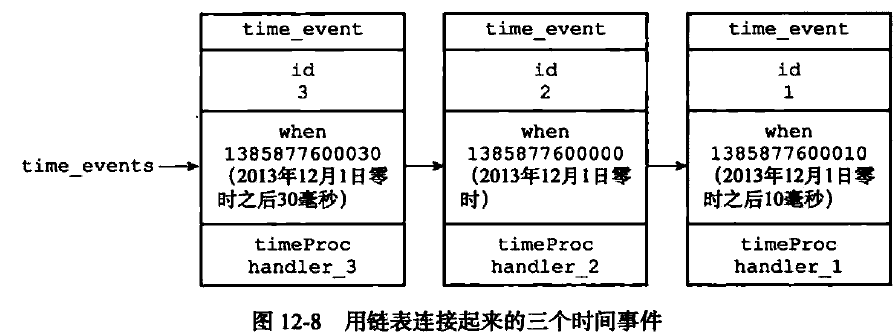
每次在处理时间事件时,就遍历整个链表,查找所有已经到达的时间事件,然后调用对应的处理函数。
/* Process time events */
static int processTimeEvents(aeEventLoop *eventLoop) {
eventLoop->lastTime = now; //更新最后一次处理事件
te = eventLoop->timeEventHead;
while(te) {
aeGetTime(&now_sec, &now_ms); //获取当前时间
if (now_sec > te->when_sec || //比较时间
(now_sec == te->when_sec && now_ms >= te->when_ms))
{
id = te->id;
//调用时间处理函数
retval = te->timeProc(eventLoop, id, te->clientData);
processed++;
//判断是否需要循环执行该事件
if (retval != AE_NOMORE) {//是,更新下次触发时间
aeAddMillisecondsToNow(retval,&te->when_sec,&te->when_ms);
} else { //否,删除该事件
aeDeleteTimeEvent(eventLoop, id);
}
te = eventLoop->timeEventHead;
} else {
te = te->next;
}
}
return processed;
}serverCron是redis每隔100ms执行的一个循环事件,由ae事件框架驱动。其主要执行如下任务:
- 更新服务器的各类统计信息,比如时间、内存占用、数据库占用情况等
- 清理数据库中的过期键值对
- 对不合理的数据库进行大小调整
- 关闭和清理连接失效的客户端
- 尝试进行 AOF 或 RDB 持久化操作
- 如果服务器是主节点的话,对附属节点进行定期同步
- 如果处于集群模式的话,对集群进行定期同步和连接测试
serverCron是由redis的事件框架驱动的定位任务,这个定时任务中会调用activeExpireCycle函数,针对每个db在限制的时间REDIS_EXPIRELOOKUPS_TIME_LIMIT内迟可能多的删除过期key,之所以要限制时间是为了防止过长时间的阻塞影响redis的正常运行。这种主动删除策略弥补了被动删除策略在内存上的不友好。
1.记录循环时间:
server.unixtime = time(NULL)redis使用 全局状态cache了当前的时间值。在vm实现以及lru实现中,均需要对每一个对象的访问记录其时间,在这种情况下,对精度的要求并不高(100ms内的访问值一样是没有问题的)。使用cache的时间值,其代价要 远远低于每次均调用time()系统调用
2.更新LRUClock值:
后续在执行lru淘汰策略时,作为比较的基准值。redis默认的时间精度是10s(#define REDIS_LRU_CLOCK_RESOLUTION 10),保存lru clock的变量共有22bit。换算成总的时间为1.5 year(每隔1.5年循环一次)。不知为何在最初设计的时候,为lru clock只给了22bit的空间。
3.更新峰值内存占用:
if (zmalloc_used_memory() > server.stat_peak_memory)
server.stat_peak_memory = zmalloc_used_memory();SIG_TERM信号的处理函数中并没有立即终止进程的执行,而是选择了标记 shutdown_asap flag,然后在serverCron中通过执行 prepareForShutdown函数,优雅的退出。
在prepareForShutdown函数中,redis处理了rdb、aof记录文件退出的情况,最后保存了一次 rdb文件,关闭了相关的文件描述符以及删除了保存pid的文件(server.pidfile).
5.打印统计信息
统计信息分为两类,两类统计信息均为每5s输出一次。第一类是key数目、设置了超时值的key数目、以及当前的hashtable的槽位数,第二类是当前的client数目,slaves数目,以及总体的内存使用情况:
6.尝试resize hash表
因为现在的操作系统fork进程均大多数采用的是copy-on-write,为了避免resize哈希表造成的无谓的页面拷贝,在有后台的rdb save进程或是rdb rewrite进程时,不会尝试resize哈希表。
否则,将会每隔1s,进行一次resize哈希表的尝试;同时,如果设置了递增式rehash(redis默认是设置的),每次serverCron执行,均会尝试执行一次递增式rehash操作(占用1ms的CPU时间);
7.关闭超时的客户端
隔10s进行一次尝试
if ((server.maxidletime && !(loops % 100)) || server.bpop_blocked_clients)
closeTimedoutClients();9.如果有后台的save rdb操作或是rewrite操作:
调用wait3获取子进程状态。此wait3为非阻塞(设置了WNOHANG flag)。注意:APUE2在进程控制章节其实挺不提倡用wait3和wait4接口的,不过redis的作者貌似对这个情有独钟。如果后台进程刚好退出,调用backgroundSaveDoneHandler或backgroundRewriteDoneHandler进行必要的善后工作,并更新dict resize policy(如果已经没有后台进程了,就可以允许执行resize操作了)。
10.否则,如果没有后台的save rdb操作及rewrite操作:
首先,根据saveparams规定的rdb save策略,如果满足条件,执行后台rdbSave操作;
其次,根据aofrewrite策略,如果当前aof文件增长的规模,要求触发rewrite操作,则执行后台的rewrite操作。
11.如果推迟执行aof flush,则进行flush操作,调用flushAppendOnlyFile函数;
12.如果此redis instance为master,则调用activeExpireCycle,对过期值进行处理(slave只等待master的DEL,保持slave和master的严格一致);
13.最后,每隔1s,调用replicationCron,执行与replication相关的操作。
serverCron最后,return 100。表明server将会在100ms后重新调用这个例程的执行。
四、Redis的文件事件
redis中的文件事件都是通过aeCreateFileEvent来创建的
/* fd为要监听的描述符,mask为要监听的事件类型,proc为对应的处理函数*/
int aeCreateFileEvent(aeEventLoop *eventLoop, int fd, int mask,
aeFileProc *proc, void *clientData)
{
if (fd >= eventLoop->setsize) {
errno = ERANGE;
return AE_ERR;
}
aeFileEvent *fe = &eventLoop->events[fd];
// 将事件加入到事件集中
if (aeApiAddEvent(eventLoop, fd, mask) == -1)
return AE_ERR;
// 设置回调函数
fe->mask |= mask;
if (mask & AE_READABLE) fe->rfileProc = proc;
if (mask & AE_WRITABLE) fe->wfileProc = proc;
fe->clientData = clientData;
if (fd > eventLoop->maxfd)
eventLoop->maxfd = fd;
return AE_OK;
}1)监听socket,只需要监听来自客户端的连接请求
因此只需要注册一个读事件,处理函数为acceptTcpHandler()
2) 连接socket:与已经建立连接的client通信
初始时也只需要监听来自client的请求,因此需要注册一个读事件 readQueryFromClient()。
当server处理了来自client的请求后,需要将操作的结果返回给client,因此此时需要注册一个写事件sendReplyToClient()
redis处理文件事件和时间事件都是在函数aeProcessEvents中完成的
由于select、epoll等IO复用机制在一定时间内没有事件发生时,会一直阻塞在那里。因此为了不影响后面时间事件的处理,必须在最近的一个时间事件到来之前,完成IO复用机制的调用。因此首先找到最近一个时间事件,计算距离当前时间的时间差,来作为调用aeApiPoll()的参数。
五、Redis中的阻塞BLPOP的实现
redis中blpop可以实现链表的阻塞操作,客户端连接在list没有数据的情况下会进行阻塞。这让我产生了一个疑问,redis本身是一个单线程服务,如果阻塞客户端一直保持着跟服务器的链接,会不会阻塞其他命令的执行呢?
答案显然是不会,这就涉及到redis阻塞命令的实现原理。
我们知道,在redis server中有两个循环:IO循环和定时事件。在IO循环中,redis完成客户端连接应答、命令请求处理和命令处理结果回复等,在定时循环中,redis完成过期key的检测等。redis一次连接处理的过程包含几个重要的步骤:IO多路复用检测套接字状态,套接字事件分派和请求事件处理。
redis在blpop命令处理过程时,首先会去查找key对应的list,如果存在,则pop出数据响应给客户端。否则将对应的key push到blocking_keys数据结构当中,对应的value是被阻塞的client。当下次push命令发出时,服务器检查blocking_keys当中是否存在对应的key,如果存在,则将key添加到ready_keys链表当中,同时将value插入链表当中并响应客户端。
服务端在每次的事件循环当中处理完客户端请求之后,会遍历ready_keys链表,并从blocking_keys链表当中找到对应的client,进行响应,整个过程并不会阻塞事件循环的执行。所以, 总的来说,redis server是通过ready_keys和blocking_keys两个链表和事件循环来处理阻塞事件的。
六、Redis中的事务的实现原理
Redis事务通常会使用MULTI,EXEC,WATCH等命令来完成,redis实现事务实现的机制与常见的关系型数据库有很大的区别,比如redis的事务不支持回滚,事务执行时会阻塞其它客户端的请求执行。redis事务从开始到结束通常会通过三个阶段:
1.事务开始
2.命令入队
3.事务执行
redis > MULTI
OK
redis > SET "username" "bugall"
QUEUED
redis > SET "password" 161616
QUEUED
redis > GET "username"
redis > EXEC
1) ok
2) "bugall"
3) "bugall"标记事务的开始,MULTI命令可以将执行该命令的客户端从非事务状态切换成事务状态,这一切换是通过在客户端状态的flags属性中打开REDIS_MULTI标识完成, 我们看下redis中对应部分的源码实现:
void multiCommand(client *c) {
if (c->flags & CLIENT_MULTI) {
addReplyError(c,"MULTI calls can not be nested");
return;
}
c->flags |= CLIENT_MULTI; //打开事务标识
addReply(c,shared.ok);
}redis客户端有自己的事务状态,这个状态保存在客户端状态mstate属性中,mstate的结构体类型是multiState,multiState的定义:
typedef struct multiState {
multiCmd *commands; //存放MULTI commands的数组
int count; //命令数量
} multiStatetypedef struct multiCmd {
robj **argv; //参数
int argc; //参数数量
struct redisCommand *cmd; //命令指针
} multiCmd;当开启事务标识的客户端发送 EXEC命令的时候,服务器就会执行,客户端对应的事务队列里的命令,EXEC 的实现细节:
void execCommand(client *c) {
int j;
robj **orig_argv;
int orig_argc;
struct redisCommand *orig_cmd;
int must_propagate = 0; //同步持久化,同步主从节点
//如果客户端没有开启事务标识
if (!(c->flags & CLIENT_MULTI)) {
addReplyError(c,"EXEC without MULTI");
return;
}
//检查是否需要放弃EXEC
//如果某些被watch的key被修改了就放弃执行
if (c->flags & (CLIENT_DIRTY_CAS|CLIENT_DIRTY_EXEC)) {
addReply(c, c->flags & CLIENT_DIRTY_EXEC ? shared.execaborterr :
shared.nullmultibulk);
discardTransaction(c);
goto handle_monitor;
}
//执行事务队列里的命令
unwatchAllKeys(c); //因为redis是单线程的所以这里,当检测watch的key没有被修改后就统一clear掉所有的watch
orig_argv = c->argv;
orig_argc = c->argc;
orig_cmd = c->cmd;
addReplyMultiBulkLen(c,c->mstate.count);
for (j = 0; j < c->mstate.count; j++) {
c->argc = c->mstate.commands[j].argc;
c->argv = c->mstate.commands[j].argv;
c->cmd = c->mstate.commands[j].cmd;
//同步主从节点,和持久化
if (!must_propagate && !(c->cmd->flags & CMD_READONLY)) {
execCommandPropagateMulti(c);
must_propagate = 1;
}
//执行命令
call(c,CMD_CALL_FULL);
c->mstate.commands[j].argc = c->argc;
c->mstate.commands[j].argv = c->argv;
c->mstate.commands[j].cmd = c->cmd;
}
c->argv = orig_argv;
c->argc = orig_argc;
c->cmd = orig_cmd;
//取消客户端的事务标识
discardTransaction(c);
if (must_propagate) server.dirty++;
handle_monitor:
if (listLength(server.monitors) && !server.loading)
replicationFeedMonitors(c,server.monitors,c->db->id,c->argv,c->argc);
}watch:
命令是一个乐观锁,它可以在EXEC命令执行之前,监视任意数量的数据库键,并在执行EXEC命令时判断是否至少有一个被watch的键值,被修改如果被修改就放弃事务的执行,如果没有被修改就清空watch的信息,执行事务列表里的命令。
unwatch:
顾名思义可以看出它的功能是与watch相反的,是取消对一个键值的“监听”的功能能
discard:
清空客户端的事务队列里的所有命令,并取消客户端的事务标记,如果客户端在执行事务的时候watch了一些键,则discard会取消所有
键的watch.














 6594
6594











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









