







一、Scala语言简介
scala本身是一门函数式编程和面向对象编程结合的语言:
1.函数式编程非常擅长数值计算
2.面向对象特别适合于大型工程或项目的组织以及团队的分工协作。
scala基于函数式编程和面向对象编程,构建了一门非常优雅的语言。 我们借助于scala,可以非常优雅地构造出各种规模的项目,这种项目不仅结构优雅,而且在做计算的时候,非常地精致和富于表现力。
所以,从软件工程和具体的数值计算上来看,scala是一门近乎完美的语言。既具有Java语言的面向对象支持的优势,又有具体的函数式编程处理数值的强大能力。
二、Scala会是下一个伟大的语言吗?
Will Scala be the next great language?Only time willtell.Martin Odersky's team certainly has the taste and skill for the job.Onething is sure:Scala sets a new standard against which future languages will bemeasured.
Neal Gafter
San Jose, California
September 3, 2008
翻译:
Scala将会是下一个最棒的语言吗?只有时间知道一切。Martin Odersky(Scala之父)的团队当然有这样的兴趣和技能来完成这样的工作。有一件事是肯定的:Scala会设定未来语言将如何被衡量的标准。
这里对scala语言进行了非常高的评价。目前大数据领域最火爆的计算框架Spark本身就是用Scala语言编写的。所以,大家如果说掌握了Scala语言就可以为Spark学习打下非常良好的语言基础。那我们从零起步,现在来带领大家去构建Scala的开发环境。
三、Scala开发环境的搭建
1.java的安装
如果要开发Scala,由于Scala本身依旧是基于JVM的,所以我们需要安装Java。大家可以打开Java的官方网站(www.oracle.com),可以安装最新的Java8,也可以选择匹配当前操作系统的版本的位数的JDK.
关于如何下载JDK,请参考这篇文章。http://jingyan.baidu.com/article/9989c746064d46f648ecfe9a.html
推荐大家使用java8.
2.Java环境变量的配置
玩儿Java的童鞋都知道,我这里再赘述一下:
计算机右键-->属性-->高级系统配置-->环境变量。用户变量和系统变量都可以,我这里设置系统变量。
1.新建 变量名JAVA_HOME 变量值是jdk的安装路径,我这里是 D:\Program Files\Java\jdk1.8.0_101
2.找到path变量,添加 ;%JAVA_HOME%\bin; 这样方便我们在任何目录下使用Java的命令。
3.找到classpath变量,添加 ;%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar;.;
3.scala的安装
从scala语言学习的角度来看,可以安装最新版本。但是在这里必须强调的是,由于到目前为止最新的Spark版本是2.1.0,编译语言环境是Scala2.11.x。所以,我们在构建真正的Scala开发环境的时候,下载的版本也需要2.11.x。spark官网上说的非常清楚。但是我电脑之前安装的spark和scala都是老版本的,所以,后续介绍的scala的版本是2.10.4。大家可忽略我演示的版本号,下载2.11.x。
打开Scala官网,http://www.scala-lang.org/ 点击download:
再点击 all downloads,所有下载版本:
选择2.10.4版本:
把鼠标停留在Scala2.10.4的框框上,出来download,点击下载:
4.Scala环境变量的配置:
1.新建 变量名SCALA_HOME 变量值是scala的安装路径,我这里是D:\Program Files (x86)\scala
2.在path环境变量里加入 %SCALA_HOME%\bin 这样,可以在任意目录下使用scala的命令。
5.验证Java和Scala的配置是否有误
在命令终端输入java,运行出现如下图的一堆参数说明没有问题。
再输入java -version 查看版本号,我这里是1.8.0_101.
再输入scala,运行出现如下图说明没有问题。
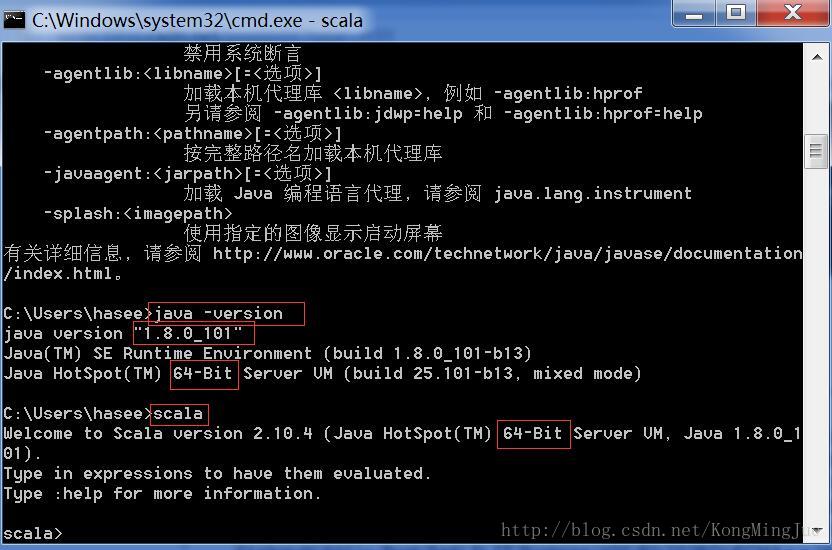
到此,说明Java和Scala的安装和配置都没有问题了。
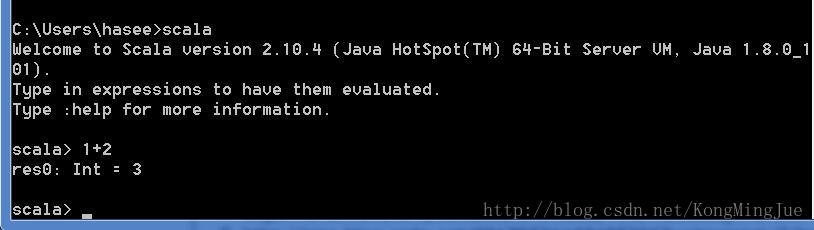
我们可以用scala做一个数值计算,再输入1+2,可以看到它可以作为一个计算器,返回res0:Int = 3
6.Scala集成开发环境(IDE)的选择
我们主要通过IDE集成开发环境来开发scala,Scala的IDE集成开发环境有好几个,首推的是IDEA。我们在做Spark大数据开发的时候都是基于IDEA的方式。一方面是IEDA对Java和Scala支持地特别好,另一方面就是IDEA集成了Maven 和SBT这些工具,特别方便我们持续构建和打包。IDEA下载方法:http://www.jetbrains.com/idea/features/ 把页面滑到最下面,点击Free download 上的download按钮即可下载。
而在Windows上,我们还会推荐另外一个工具,就是Scala-IDE for Eclipse。在这种方式下,也非常方便。像我们刚刚安装好了Java和Scala,那直接下载下来(http://scala-ide.org/),解压,就可以了。Scala-IDE for Eclipse内部是在eclipse的基础上自动集成好了Scala插件,如果是初学者,王老师强烈建议采用这种方式。我们初步学习时也用这种方式。
总结:
我们要构建scala集成开发环境,装好Java(建议Java8),然后安装scala(也特别注意是2.10.x, 建议使用2.10.4)。然后就是安装Scala-IDE for Eclipse。
四、HelloWorld程序
new scala project --> 新建package --> new scala object。 scala object是scala中的类的静态对象。object中拥有scala程序的main方法的入口。选中public static void main,其实由于object里的所有成员,包括方法和属性都是静态的,所以这边虽然选中了,但是finish后,发现main方法前面没有static关键字,因为它已经是静态的了。关于object和class,后续再谈。
package com.dt.scala.hello
object HelloScala {
def main(args : Array[String]) : Unit = {
println("Hello Scala!! A new World!!!")
}
}右键Run As -->Scala Application
打印出Hello Scala!! A new World!!!
代码说明:
object里的所有成员都是静态的,这是Scala的语法现象。后续讲类和对象的时候都会再讲解。object是类的伴生对象,因为现在没有类,所以它就是个静态方法和成员的集合。main是程序的入口,args是参数名,类型是数组,数组的类型是String。我们可以为当前程序的入口传入参数,冒号:后面加了Unit,Unit是空值的意思,这个main方法不返回什么值。=是scala定义函数的方式。当然也可以把: Unit = 去掉,运行也会得出上面的结果。
增加代码:
for(arg <- args) println(arg)右键Run As -->Run Configurations-->Arguments里输入四个参数(Spark Scala Hadoop Java)作为main方法的参数args.
打印出Spark Scala Hadoop Java
Spark是用Scala写的,Hadoop是用Java写的。Scala可以操作Java的一切,所以Spark也可以操作Hadoop的一切!
如果大家也跟着老师得出了同样的结果,那么恭喜你,迈开了通往大数据重要的第一步!我们就在这个步骤的基础上开启整个大数据的征程!
参考资料来源于 DT大数据梦工厂 Scala零基础实战经典第1课 由王家林老师讲解














 3963
3963











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









