







Hbase
官网:http://hbase.apache.org/
1、hbase rowkey怎么创建比较好,列簇怎么创建比较好?
1、三维
Hbase有序存储的三维是指:rowkey(行主键),column key(columnFamily+qualifier),timestamp(时间戳)三部分组成的三维有序存储。
2、Hbase 表添加大量数据
File/datas--->hfile--->bulk load into hbase table
一个region大量数据放到里面,regionServer有可能出问题,所以进行预分区,数据同时插入多个region。
实质就是提前划分region
默认情况:startkey和endkey都为空
提前分区:提前创建多个region,为每个region划分rowkey的区间
实现预分区:rowkey是前缀匹配
创建预分区的三种方式:
Create “ns1:t1”,”info”,split => [‘10’,’20’,’30’,’40’,’50’] 6个region哦
Create “ns1:t1”,”info”,SPLIT_FILE =>’split.txt’
Create“ns1:t1”,”info”,{NUMREGIONS =>6,SPLITALGO =>’HexStringSplit’}
3、Rowkey设计:
默认情况下,是索引检索的唯一依据。
目的:尽量减少磁盘空间,加快索引速度,避免热点问题。
基本原则:根据企业业务需求设计
唯一原则:rowkey具有唯一性
设计原则:建议rowkey长度在100以内,越短越好8-16
散列原则: 避免热点问题,随机值+算法生成
反转字符串:123--->321
4、例如:
主表:rowkey phone+time
1、索引表:rowkey别人号码+时间
列簇:info
列主表rowkey
主表与索引表同步-------->事务
https://phoenix.apache.org 在nosql中建立sql(客户端)jdbc同步
创建索引表的第二种方式
Solr
自动创建索引 cloudera search
字符串拼接:随机值+话单+时间
2、Hbase过滤器实现原则
所有的过滤器都在服务端生效,叫做谓语下推(predicate push down),这样可以保证被过滤掉的数据不会被传送到客户端。
注意:
基于字符串的比较器,如RegexStringComparator和SubstringComparator,比基于字节的比较器更慢,更消耗资源。因为每次比较时它们都需要将给定的值转化为String.截取字符串子串和正则式的处理也需要花费额外的时间。
过滤器本来的目的是为了筛掉无用的信息,所有基于CompareFilter的过滤处理过程是返回匹配的值。
filter ==> SQL 中的Where
3、Hbase读写数据的过程
hbase读写流程:
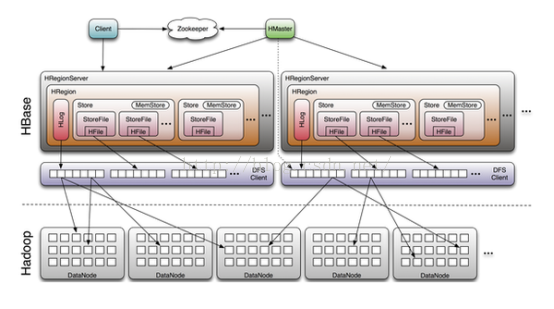
读的流程(zookeeper(regionserver地址)-->hbase(hbase(meta(regionserver(region(roekey)))))--
Region(操作))
具体流程:
1、语句检索rowkey 找到具体region-->链接zookeeper(查找meta的regionserver地址)--->找到hbase的regionserver及其管理的region-->
2、 读取一行数据--->先检查memstore等待修改的队列--->在检查blockcache看是否包含该行的block是否最近被访问过---> 最后访问硬盘上对应的hfile
写的流程:Put ‘tname’,’rowkey’,’cf:c’,’value’
先写到hlog,然后在向memstore写,memstore到达一定阈值后,在向hfile写。
具体流程:
1、语句检索:rowkey + cf +col -》 region
2、链接zookeeper(查找meta的regionserver地址)--->找到hbase的regionserver-->
Region-->store(向memstore写,memstore到达一定阈值后flush成一个storefile,storefile增长到一定阈值促发compatct合并操作,单个storefile超过一定阈值会促发split操作,把当前region split成两个region,原本的region下线,新生的两个region被HMaster分配到相应的regionserver)-->storefile(hfile)-->hdfs

4、Hbase宕机如何处理

5、Hbase怎么预分区
分区:
默认一张表一个region:
Rowkey:0000--1000
Region1:0000-0500 startkey:0000
Region2:0501-1000 startkey:0500
后面的数据:
1001--->region2
1002--->region2
1500-->region2-->region3:0501-1000
region4:1001-1500 rowkey一直是递增的。
与分区:提前划分region
默认情况下:startkey和endkey都为空
提前分区:提前创建多个region,为每个region划分rowkey
实现:
创建预分区的三种方式:
Create “ns1:t1”,”info”,split => [‘10’,’20’,’30’,’40’,’50’] 6个region哦
Create “ns1:t1”,”info”,SPLIT_FILE =>’split.txt’
Create“ns1:t1”,”info”,{NUMREGIONS =>6,SPLITALGO =>’HexStringSplit’}
6、Hbase处理并发问题
锁与mvcc机制
具体参见此篇博客:http://www.cnblogs.com/leetieniu2014/p/5393755.html
HBase同步机制
HBase提供了两种同步机制,一种是基于
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1424
1424











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









