







原理概述
跳跃表(skip list)是一个有序元素序列快速搜索的数据结构,它的效率和红黑树及AVL树等不相上下,其查找、插入、删除的期望时间复杂度都是O(lgn),空间复杂度O(n),但是理解和实现起来很容易。
跳跃表是一个基于概率的数据结构,所以跳跃表的相关时间复杂度是摊还情况下的期望值。最坏情况下的查找时间复杂度是O(n),但是我们可以合理设定参数,把最坏情况发生的概率降低到比中大乐透头奖都难。
跳跃表是一个分层结构多级链表,最下层是原始的链表,每个层级都是下一个层级的“高速跑道”。但笔者认为其本质思想依旧是平衡树的思想,所以这里笔者把它当做平衡树的一类。
下图是笔者手画跳跃表的一种实现:
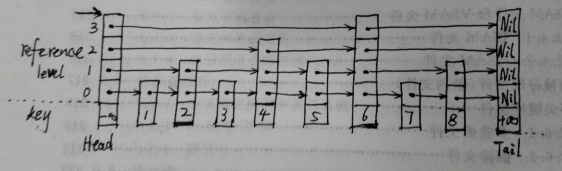
从图中可以知道:
跳跃表是由一系列的结点构成,每一个结点都包含关键字域(key)和引用层级数组域(reference level)。
有一个key为负无穷(-inf)的头结点和一个key为正无穷(inf)的尾结点,它们的引用层数都相同且具有最大引用层数。
其余的结点为有序的普通数据结点,它们具有的引用层数是随机产生的。最大引用层数不超过头尾结点的最大引用层数,但最少必须拥有一层引用。当所有结点都只具有一层引用的时候(图中第0层引用),此时跳跃表就退化成了单链表。
这里简单说下这些数据结点的引用层数是如何随机确定的。首先,结点必须最少有一层引用,在此基础上抛掷一枚硬币,若出现正面,结点引用层数加1并继续抛掷,若出现反面,即刻停止,这时的引用层数即为最终的结点引用层数。用一句术语说就是:每一层结点出现在其上层的概率固定为p。而这里我们抛掷硬币只不过将p取值为0.5罢了。实际情况下,P取值0.5、0.25、1/e都可以取得不错的效果。
查找、插入和删除
跳跃表的查找很简单,依据的一个原则就是从最高层级到最低层级逐层查找,直到搜索到待查关键字结点而退出,其中依据情况看是否跳过部分结点。
举个例子,在上图中查找node5(关键字为5的结点)。
从Head的最高层引用-第3层开始,其第3层引用的是node6,它大于node5,于是在Head上降低一层从第2层开始查找。
Head的第2层引用的结点是node4,它小于node5,于是我们直接来到node4,这其中跳过了node1、node2、node3。
node4的第2层引用的结点是node6,它大于node5,于是在node4上降低一层从第1层开始查找。
node4的第1层引用的结点是node5,即我们所需的待查结点。
一句话总结:后继比待查关键字大,下移,比待查关键字小,右移。
查找的一个路线如下图中红色箭头所示:

明白了如何查找,那删除和插入就太简单了。
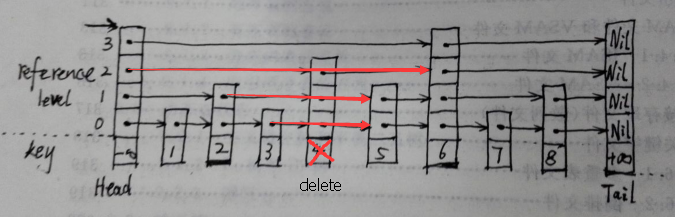
比如我要删除上图中的node4,那么需要先找到node4的所有前驱结点和所有后继结点。从上图中可以看出,Head、node2、node3都是node4的前驱结点。查找这些前驱结点和上面讲过查找方法是一样的,然后再修改找到的前驱结点的相关引用层的引用结点。比如Head的第2层修改为直接引用node4第2层的后继node6,node2的第1层修改为直接引用node4第1层的后继node5,node3第0层修改为直接引用node4第0层的后继node5,node4的各层引用置为空。至此删除node4完毕。
下图展示了删除结点后的连接情况,注意红色连接。
至于插入,本质上和删除就是一个相反的过程,插入和删除其实就是单链表的升级版,这里不再多说。整个具体实现请看后文python实现。
具体实现
# A simple implemention of skip list
# python 3.3
import random
class SkipListNode_:
def __init__(self, level = 1, key = 0):
self.level_ = int(level)
self.key_ = key
self.ptr_arr_ = []
for i in range(self.level_):
self.ptr_arr_.append(None)
class SkipList:
def __init__(self, level = 4, prob = 0.5):
self.max_level_ = int(level)
self.prob_ = float(prob)
self.head_ = SkipListNode_(self.max_level_, float('-inf'))
self.tail_ = SkipListNode_(self.max_level_, float('inf'))
for i in range(self.max_level_):
self.head_.ptr_arr_[i] = self.tail_
def _calculateLevel(self):
level = 1
while level < self.max_level_ and random.random() <= self.prob_ :
level += 1
return level
def search(self, key):
node = self.head_
i = self.max_level_-1
while i >= 0:
node_i = node.ptr_arr_[i]
if node_i.key_ > key:
i -= 1
elif node_i.key_ < key:
node = node_i
else:
return node_i
return None
def insert(self, key):
level = self._calculateLevel()
new_node = SkipListNode_(level, key)
node = self.head_
i = level - 1
while i >= 0:
node_i = node.ptr_arr_[i]
if node_i.key_ > key:
node.ptr_arr_[i] = new_node
new_node.ptr_arr_[i] = node_i
i -= 1
else:
node = node_i
def delete(self, key):
node = self.head_
i = self.max_level_-1
while i >= 0:
node_i = node.ptr_arr_[i]
if node_i.key_ > key:
i -= 1
elif node_i.key_ < key:
node = node_i
else:
node.ptr_arr_[i] = node_i.ptr_arr_[i]
node_i.ptr_arr_[i] = None
def print_sl(sl):
max_level = sl.max_level_
pn = sl.head_
key_list = []
while pn != None:
sub_key = []
for i in range(max_level):
if i < pn.level_:
sub_key.append(pn.key_)
else:
sub_key.append('--')
key_list.append(sub_key)
pn = pn.ptr_arr_[0]
for i in range(max_level-1,-1,-1):
for j in key_list:
if j[i] == float('-inf'):
print("[%s]--"%j[i],end='')
elif j[i] == float('inf'):
print("[%s]"%j[i],end='')
else:
print("%2s--"%j[i],end='')
print()
print()
# A simple test of skip list
if __name__ == '__main__':
print('Skip list test...\n')
sl_level = 5
sl_prob = 0.5
print('Initialize skip list with no data: level = %2d prob = %.2f'%(sl_level, sl_prob))
sl = SkipList(sl_level, sl_prob)
print_sl(sl)
min_num = 5
max_num = 49
num_count = 18
key_list = []
for i in range(num_count):
key_list.append(random.randint(min_num, max_num)*2)
print('Insert these keys:', key_list)
for key in key_list:
sl.insert(key)
print_sl(sl)
exist_key = random.choice(key_list)
no_exist_key = random.randint(min_num, max_num)*2-1
print("search key: %d, %d"%(exist_key,no_exist_key))
if sl.search(exist_key) != None:
print("Found %d"%exist_key)
else:
print("No found %s"%exist_key)
if sl.search(no_exist_key) != None:
print("Found %d"%no_exist_key)
else:
print("No found %s"%no_exist_key)
print()
delete_key = random.choice(key_list)
print("delete key: %d"%delete_key)
sl.delete(delete_key)
print_sl(sl)一个运行例子:

几个问题探讨
上面实现的跳跃表:
1、可以插入重复key,并且先插入的key更靠近头结点。
2、删除key结点的时候会把具有该key值的所有结点删掉。
3、若待查找的key有多个结点的时候,查找返回的结果是具有最高引用层数的key,若最高引用层数也相同,则返回更靠近头结点的key结点。
那么留给读者几个问题,只需微微修改源代码:
1、实现一个不含重复key的跳跃表。
2、有重复key,查找的时候把具有该key值的所有结点都作为结果返回。
3、有重复key,删除的时候只删除靠近头结点的key结点。
4、优化随机生成引用层数的算法,只调用一次随机数生成函数rondom()。















 1336
1336

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









