







一、概要
该paper发于NAACL2016,主要对比了BiLSTM-CRF和Stack-LSTM两种模型用于命名实体识别,本次笔记只记录第一种模型;并且采用词级向量和字符级向量结合的方式,在不使用外部的特定领域知识等,仅仅使用了少量监督语料的特征以及未标注语料情况下就可以达到领先水平。
二、模型方法
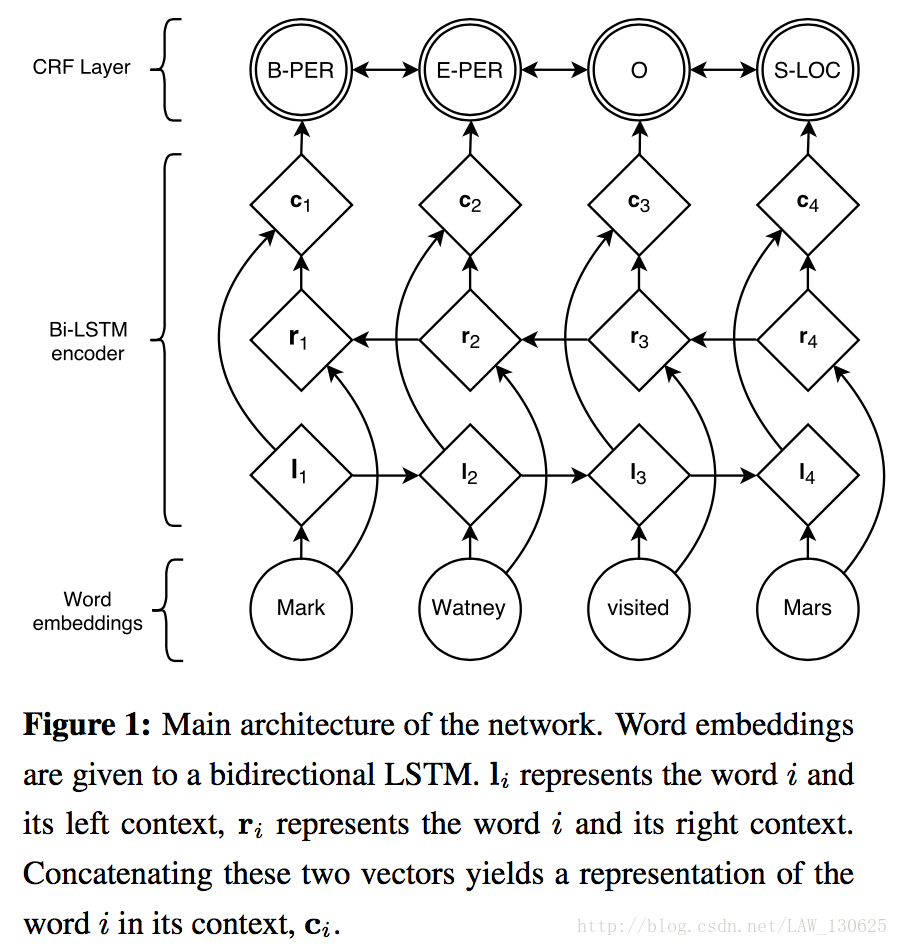
2.1 LSTM
关于LSTM使用的是其一个变种,具体可以查看:【Deep Learning】LSTM(Long Short-Term Memory)及变体,这里主要使记录使用下面几个计算公式:
其中 σ 为sigmoid函数, ⊙ 为向量元素点乘。
对于一个句子 S=(x1,x2,...,xn) 含有n个词,每个词可以映射为d-dimensional的向量,那么可以使用双LSTM分别获得从左开始的 →ht 与由右端开始的 ←ht ,最后把它们串联起来得到 ht 。
2.2 CRF Tagging Models
由上面LSTM的输出在一定情况下可以直接作为特征,然后对识别标记进行分类,但是作者认为在强相关性的输出标签分类中效果并不好,所以使用了CRF(条件随机场)。
首先定义矩阵P为LSTM的分类打分矩阵,即P的大小为n
×
k,n为词汇个数,k为tag类别个数,这可以让输出用softmax函数得到概率作为分数,那么
Pi,j
可以表示句子中第i个词标记为第j个标签的概率。
对于待预测的标签
y=(y1,y2,...,yn)
,有如下定义:
其中A是状态转移矩阵,如 Ai,j 表示从第i个tag转移到第j个tag的概率,通过求得最大的 s(X,y)
,即可得到最佳的输出标签序列。很明显这里的CRF,其实只是对输出标签二元组进行了建模,然后使用动态规划进行计算即可,最终根据得到的最优路径进行标注。
2.3 Input Word Embeddings
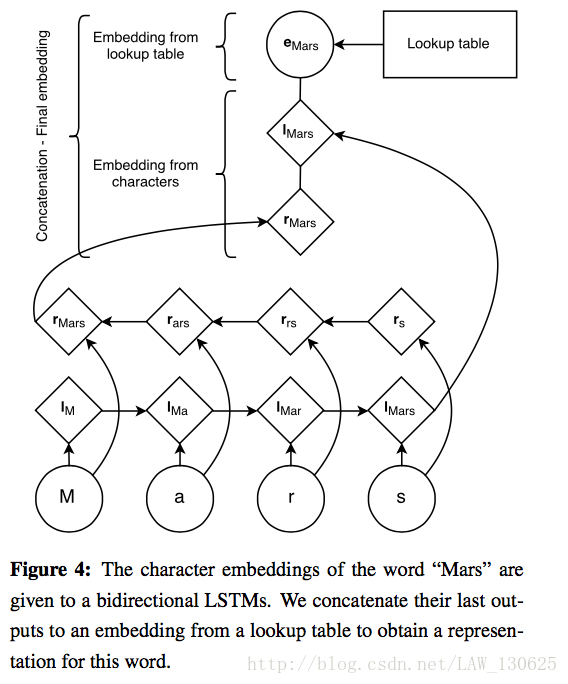
如概要介绍,作者发现名字与语言的形态和拼写有很大的关系,所以作者使用了词级向量和字符级向量结合的方式作为网络的输入。字符级的向量作者使用 forward and a backward LSTM从每个词的字符来训练每一个词向量,最终的 Input Word Embeddings,三组向量串联得到。
三、实验和结果
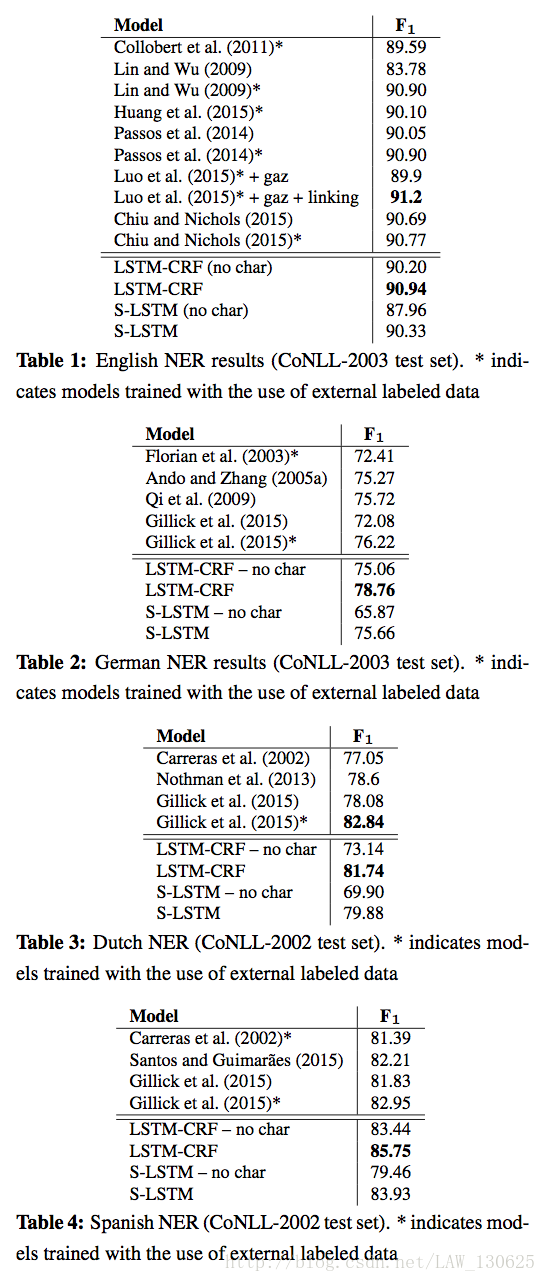
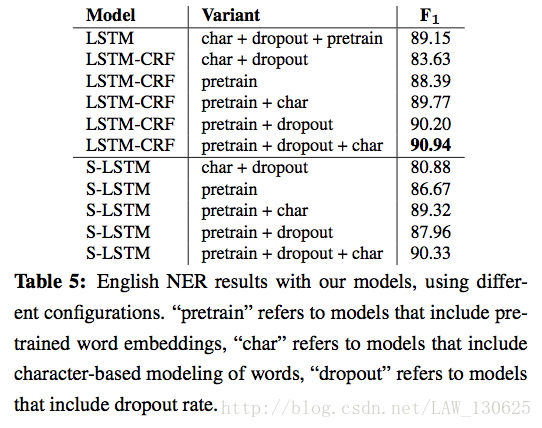
四、结论
作者认为没有使用外部知识的条件下可以取得如此好的效果主要关键是使用了CRF来利用输出标签的强相关性,以及使用字符级向量来学习到词的拼写与形态的特征。
五、个人思考
①该paper中没有使用当下流行的Attention机制;
②文中有提到把标签设置为IOBES的分类效果好于IOB模式,但是在该实验中又没有体现,一般我们的直觉也是类别少分类效果可能会更好,直觉而已。
参考文献:
①Guillaume Lample,Miguel Ballesteros.Neural Architectures for Named Entity Recognition.
②代码链接:https://github.com/liu-nlper/NER-LSTM-CRF














 260
260











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









