







持久化概述
对象持久化,必要性,应用场景,
1.程序运行的过程就是使用我们编写的程序指令来调度运算我们特定的数据或者数据结构,但这个运算过程是在内存里面的,我们知道内存不是永久性的存储,也就是当我们断电或者关机之后,内存里面的状态或者数据就会丢失。在我们实际应用开发时候,我们可能需要将当前正在计算的某个数据结果或者状态永久存储起来,这样就会用到对象的持久化。
2.日常,比如说我们玩游戏,到了某一关的状态是在内存中表现的,但是如果说我想明天接着当前的进度继续玩,那我可以把当前的进度保存一下。所谓的进度保存是指,将我们当前游戏运行内存的状态结果存储在硬盘或者其他的物理媒体上,下次再打开时可以接着上次的进度玩。就是将我们当前的进度或状态存储到一个媒介上,这种过程称之为序列化,第二天打开游戏接着玩的话,要将存储的数据反序列化到我们的内存里面,还原到之前的状态,称之为反序列化。
在做应用开发时,比如做webAPI,要在网络的两端做数据交换,这时也需要将我们计算的结果做序列化或反序列化的操作。
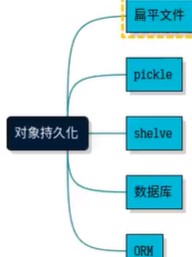
3.实际开发中常见的序列化或者持久化的技术有哪些:
使用文本文件来存储 以扁平的文件来持久化我们的数据
pickle对象
字典表方式存储shelve
数据库
ORMobject relation maper对象关系映射技术
这里介绍扁平文件,pickle,shelve在python程序里面怎么序列化,持久保存我们的对象。以及在特定场景下,如何反序列化来读取已经持久化保存的数据类型。
扁平文件—文本文件
使用格式化文本
文本文件的本质就是用来保存文本信息的。如果用它来保存我们运算的一些结果或数据对象的话,有一个问题需要解决。因为我们在内存中运算的对象或者数据结构有一些自己的特性,比如说可能会用到字典表、列表、元组,包括类型的实例,如果说我们一旦把他存到文本文件,会变成纯文字,如果再把它反序列化,载入到内存里面,还原当前内存状态时候,这里面又会有一个类型还原的过程,所以相对要做的步骤会多一些,
文本文件的操作:
# 通过上下文,用open打开一个文件,w表示要进行写操作,编码时utf8,把它放到一个上下文实例里面
with open('data.txt','w',encoding='utf8') as f:
f.write('优品课堂\n')
f.write('codeclassroom.com')
# 打回车之后上下文会自动关闭我们当前的过程,并且将文件存储在本地,
现在想把内存里面操作的状态,要保留他的数据类型,存到文件里面,再把它还原回来,如何做?
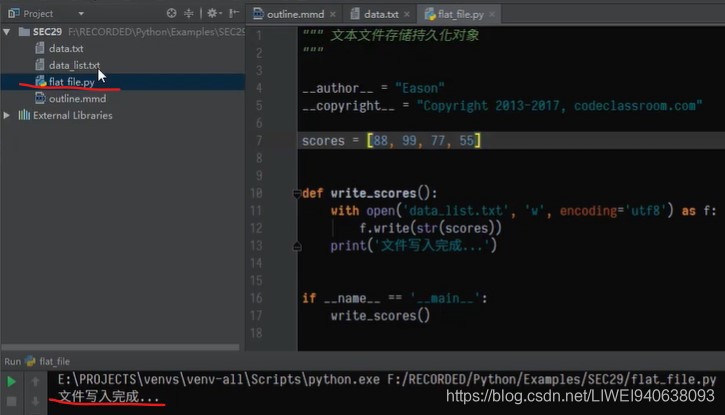
创建脚本文件flat_file.py,以文本文件来存储持久化对象
"""文本文件存储持久化对象
"""
scores = [88,99,77,55]
def write_scores():
with open('data_list.txt','w',encoding='utf8') as f:
f.write(str(scores))
print('文件写入完成.......')
if __name__ == '__main__': #在文件的主入口调用刚才的write_scores()函数
write_scores()
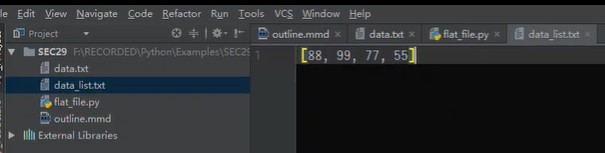
打开创建的flat_list.txt文本文件,是一个列表的内容,但是其本质是文本,跟列表类型没关系
但是如果想把他读取到我们的程序里面来,并且还原到他的类型,如何做?
再写一个读取文件的函数:
scores = [88,99,77,55]
def write_scores():
with open('data_list.txt','w',encoding='utf8') as f:
f.write(str(scores))
print('文件写入完成.......')
#读取到我们的程序里来,并且还原到他的类型。再写一个读取函数
#read()可以一次性读取所有内容。目前内容简单,所以可以一次性读取。类型不是列表,只是一个字符串
#怎样将其变成列表,来支持列表的操作,必须将其交给一个变量
def read_scores():
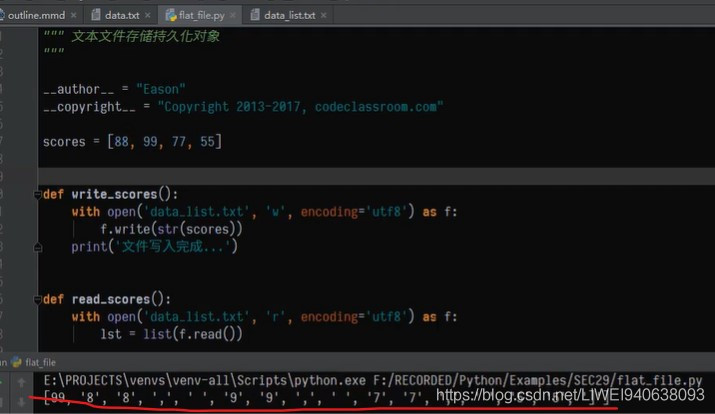
with open('data_list.txt','r',encoding='unf8') as f:
#lst = list(f.read()) # list()函数将字符串转变为列表的方法不可行,因为list()函数会将字符串中的每一个内容都转化为列表对象,包括中括号。结果如下图
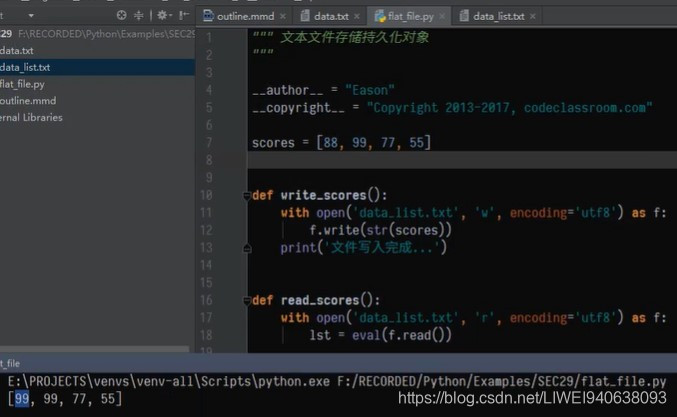
lst = eval(f.read())
lst[0] = 99
print(lst) #结果如下图
if __name__ == '__main__': #在文件的主入口调用刚才的write_scores()函数
write_scores()
list()函数将字符串转换为列表的方法,结果
由此发现用文本来存储有类型对象时比较麻烦
python提供了一个功能叫做eval()函数:将括号中传递的字符串转换成python的表达式,这样就可以当作python语句一样来运行
用eval()函数,并更改lst列表中第一个元素结果图:
这种形式尽管可以完成,但是目前结构比较简单,如果存了更复杂的结构,字典表/类型实例,那么要做的工作必须小心翼翼,还很容易出错,所以让文本文件回归他的本质,让其存储一些文本信息就可以。
想进一步序列化/持久化存储对象,可采用其他技术,pickle就可以很容易保存原有的内存中python的数据类型。
pickle
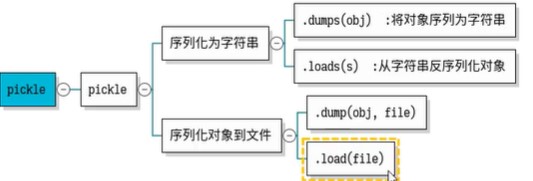
将对象序列化到字符串中
pickle模块的方法:
** pickle.dumps 将对象序列化到字符串**
** pickle.loads 将字符串反序列化为对象**
pickle给我们提供了一个模块,模块名称就叫pickle,它帮我们封装了一系列方法接口,让我们很容易地将我们内存中原有的python类型的对象将其序列化为字符串/本地的一个文件。
看代码:
import pickle
person = {'name':'Tom','age':20}
# 希望将内存中的person字典表对象序列化永久存储起来
# 1.1 将person转换为字符串,以后再从字符串还原
s = pickle.dumps() #pickle模块下的dumps方法,意思是将括号中传递过来的对象(python中的任何对象都支持)序列化为一个字符串。交给一个变量。s结果是字符串,是字节字符串。不用关心里面存储的细节是什么,当需要的时候可以把存储的字典表由字符串还原回来
# 还原做法,反序列化
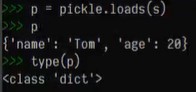
p = pickle.loads(s) #loads指从字符串中载入对象
1.希望将内存中的person字典表对象序列化永久存储起来
两种选择:
1.1 将其转换为字符串,以后需要时候再把字符串存到文本里面,读取时候再把字符串还原到以前的内容。这个过程和之前讲的“扁平文件——文本文件”很像,但是这个步骤是由他的内置方法帮我们搞定的。
dumps,废物,垃圾场
s=pickle.dumps()结果:

p = pickle.loads(s)结果:
除了上面处理的字典表之外,几乎所有的python类型都可以这样做,但是目前只是用字符串来存储有类型的对象,
将有类型特征的对象,序列化保存到文件中,然后再从文件里面反序列化读取,这个过程不使用文本文件,而使用二进制文件。
看代码:
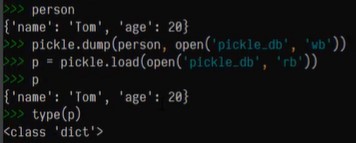
import pickle
person = {'name':'Tom','age':20}
pickle.dump(person,open('pickle_db','wb') # pickle.dump方法,两个参数,第一个参数是要序列化的对象,第二个参数是将序列化后的对象存储到哪个文件。可以现成声明一个变量,open('pickle_db','wb'),表示在当前工作目录新建一个pickle_db文件,然后告诉以写入方式,但是不要当作文本文件,所以加上b,以二进制形式写一个文件,然后把person文件放入。
# 再把对象存储过去的二进制文件载入回来
p = pickle.load(open('pickle_db','rb')) #pickle.load方法载入二进制文件。open('pickle_db','rb'),打开pickle_db文件,以二进制方式读取的形式打开。还原反序列化到p里面
open(‘pickle_db’,‘wb’)结果:
目录下面存在一个pickle_db文件,没有后缀,因为建立时候就没有指定后缀,其本质也不是文本,打开时不能识别,因为是一个二进制文件。
p = pickle.load(open(‘pickle_db’,‘rb’)) 结果:
shelve
象存到一个文件里面。通过键值来访问。
pickle有一些缺陷:
首先如果将对象存储到一个文件中,一个对象存一个文件,这没问题,如果是多个对象存到文件中,由于反序列化时候是把整个文件的对象来反序列化,所以要剥离出来想要的对象时,有些麻烦。
存储的问题可以解决,考虑将不同的对象存储到不同的文件中,维护起来有一定麻烦。如果说要把多个对象存到一个文件里面,可以通过字典表不同的键值来组织也可以,但是总之有一些额外的工作要做。
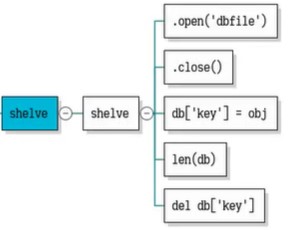
这就用到shelve工具。使用起来比pickle更进一步简化。
shelve操作特征:将我们的多个对象可以存储到一个文件里面,这些对象以后区别访问通过类似字典表的形式:给不同对象加上键值,这样存的过程和取的过程都可以通过键值来访问。
代码:
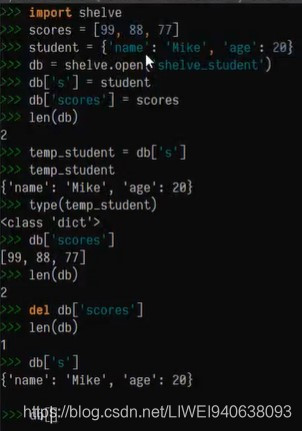
import shelve
scores = [90,88,77]
student = {'name':'Mike','age':20}
# 现在要把列表和字典表存到一个文件
# 准备一个数据库:这个数据库是语义上的,就是一个存储数据的文件。这个文件不用标准库的open方法来做,而使用shelve模块下的open方法
# 写一个叫做db的数据库,来自于shelve.open方法,括号里写上数据库名称.不用指定他的名称,也不用告诉打开的方式是写还是读,打开的是文本还是二进制。这个就直接创建了一个二进制来存储信息
db = shelve.open('shelve.student') #创建了文件对象之后,就可以把已有的数据类型的数据放进去。比如
#比如
db['s'] = student #db这个数据库文件,通过中括号给附上一个键值:叫做s,用来保存学生信息。学生信息前面声明过一个字典表,把student给他,这时就把声明的字典表序列化到数据库文件里面,并且赋予了一个键值s
db['student'] = scores
# 观察数据库中存了几个对象,len()
len(db) #结果显示有两个键值
# 访问,读取信息。和字典表一样
temp_student = db['s']
db['scores']
del db['scroes']
len[db]
存储结果:[
读取信息:删除信息:
可以方便帮我们序列化自定义类型的实例:创建一个类,再保存
"""shelve序列化自定义类型
"""
class Student:
def __init__(self,name,age):
self.name = name
self.age = age
def __str__(self):
return self.name
if __name__ == '__main__':
s = Student('Tom',20)
print(s.name)
print(s.age)
放到文件序列化来保存,在脚本中定义两个方法:存和取
import shelves
class Student:
def __init__(self,name,age):
self.name = name
self.age = age
def __str__(self):
return self.name
def write_shelve():
db = shelve.open('shelve_student_db')
s = Student('Tom',20) # 要存的时候就是构造了一个类型实例。将下面的类型实例移上来,print操作取消。
db['s'] = s #将s的Student类型实例放进去
db.close() #数据库文件有一个close方法,关掉
def read_shelve():
db = shelve.open('shelve_student_db')
st = db['s']
print(st)
print(st.name)
print(st.age)
db.close()
if __name__ == '__main__':
write_shelve()
运行结果:目录中有文件
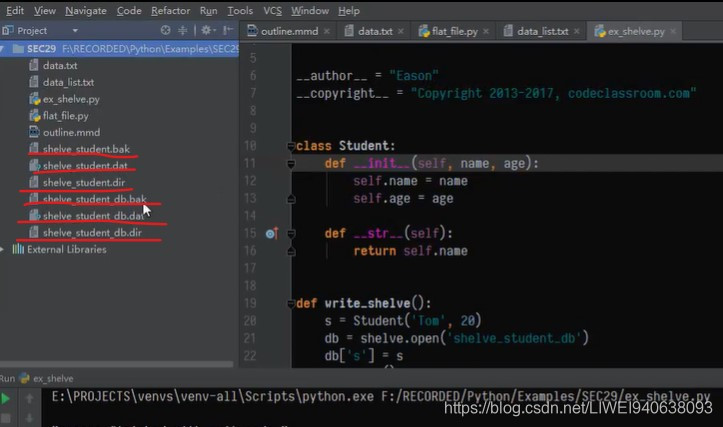
接下来将文件读出来:定义一个函数read_shelve














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









