







统计学习基础 第二版
引言
统计学习在诸多科学、金融、工业领域起到了关键性的作用,下面列举了一些学习的案例。
-
针对一位因心脏病住院的病人,预测其心脏病再次发作的概率。基于这位病人的人口信息、饮食和临床诊断信息来预测。
-
基于公司业绩评估和经济数据,预测6个月之后的股票走势。
-
基于数字化的图像,识别手写的邮政编码数字。
-
从糖尿病患者血液的红外吸收光谱数据估测患者血糖含量。
-
从临床诊断和人口统计变异值来确认前列腺癌的风险因素。
学习科学在统计、数据挖掘和人工智能领域扮演着重要的角色,在工程学和其他学科方面也有所影响。
这本书是关于数据学习的。在特定的时候,我们会得到一个结果值,通常是定量的(比如股票价格)或者是分类的(比如有心脏病或没有心脏病),我们的预测会基于一系列的特征(比如饮食、临床诊断)。我们会得到一组训练数据集,可以用来观察一个对象集(比如人)的输出结果和特征的测量值。利用这些数据,我们建立一个预测模型或者学习模型,这可以让我们对一些新的未知对象进行一些预测。一个好的学习模型可以精准地预测出结果。
表 1.1 从一封电子邮件中计算出字词的平均百分比。我们选取了一些字词来显示垃圾邮件和其他电子邮件的最大区别。
|
| george you your hp free hpl ! our re edu remove |
| Spam | 0.00 2.26 1.38 0.02 0.52 0.01 0.51 0.51 0.13 0.01 0.28 1.27 1.27 0.44 0.90 0.07 0.43 0.11 0.18 0.42 0.29 0.01 |
上面的例子描述了监督式学习的学习方式,之所有叫做监督式,是因为它利用学习结果来引导学习过程。在非监督式学习中,我们只观察特征而不会对结果进行测量。我们的任务是描述数据时如何组织或者聚合的。这本书大部分将致力于介绍监督式学习,非监督式学习在这里不会涉及许多,它会在第14章介绍。
下面是本书将要讲到的一些实际学习问题的例子。
例1:垃圾邮件
这个例子的数据时来自于4601封电子邮件,这些邮件是用来预测一封邮件是否是垃圾邮件。目的是设计一个自动识别垃圾邮件的检测器,能够将垃圾邮件过滤出来,以免填满用户的邮箱。在这4601封邮件中,得到的结果(邮件类型)是,这是普通邮件还是垃圾邮件,而且还会得到57个常用词和标点的相对频率。这是一个监督式学习问题,它的结果分为普通邮件或者垃圾邮件。这种问题又叫做分类问题。
表1.1列出的字词显示了垃圾邮件和普通邮件之间的最大平均差别。
我们所使用的学习方式必须决定使用哪种特征以及如何使用,比如我们可能会用如下方式:
if (%george<0.6) & (%you >1.5) then spam
else email.
而另一种形式的方式可能是:
if (0.2·%you−0.3·%george)>0 then spam
else email.
对于这种问题,并不是所有的误差都是平等的;我们想要避免过滤掉普通邮件,而在这种情况下让垃圾邮件通过是不让人满意而是不严谨的。我们会在本书中针对此类学习问题讨论几种不同的学习方式。
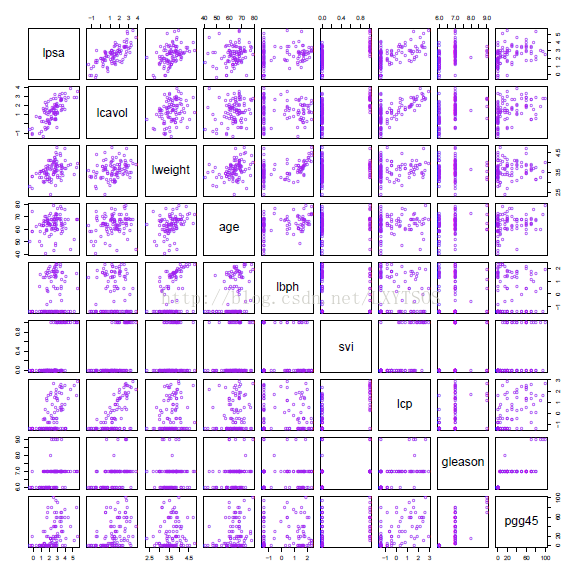
图 1.1 前列腺癌数据的散点图矩阵。第一行显示了各预测因子的反馈情况。其中两项预测因子,svi和gleason进行了分类。
例2:前列腺癌
关于这个例子的数据(图1.1),来自于Stamey et al.的研究(1989),这项研究在97位即将接受根治性前列腺切除术的男性中,检测了前列腺特异性抗原水平(PSA)和一系列临床诊断之间的关联性。
为了从一系列测量值中预测PSA(lpsa),癌细胞量(lcavol),前列腺重量lweight,年龄,良性前列腺增生值lbph,精囊侵袭svi,荚膜渗透lcp,格里森评分gleason和格里森评分4或5百分比pgg45。图1.1是各变量的散点图矩阵。一些关于lpsa的统计是明显的,但是一个好的预测模型是很难用肉眼来构建的。
这是一个监督式学习问题,又叫做回归问题,因为结果指标是定量的。
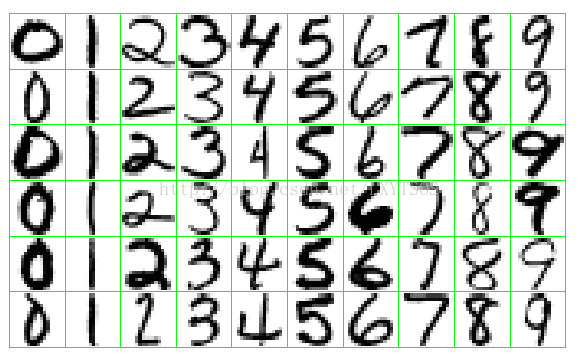
图1.2 U.S.邮政信封上手写数字的示例。
例3:手写数字识别
这个例子的数据来源于美国信封上手写的邮编。每张图片都分割自5位的邮编,隔离单个数字。这些图片是16×16像素,八位的灰度图,每个像素从0到255按强度排列。图1.2显示了一些样本图片。
这些图片都有大约相等的大小和方向。目的是在16×16的像素矩阵中快速并准确地识别每一图片(0,1,···9)。如果够准确地话,这个算法可以用在信封自动分类上。这是一个分类问题,对于这类问题,每一误差都应保持较小值,以避免邮件分类错误。为了达到如此小的误差,一些邮件可以标明“未知”,然后由人工进行分类。
例4:DNA微阵列表达
DNA的意思是脱氧核糖核酸,是组成人体染色体最基本的物质。DNA微阵列通过测量基因中的mRNA(信使核糖核酸)数量来测量细胞中基因的表达。微阵列被认为是生物学上一项突破性的技术,它促进了对一次抽样细胞上千基因中同时进行定量分析。
这里说明了DNA微阵列的工作原理。把几千基因上的核苷酸序列印在载玻片上,用红色和绿色染料来标记目标样本和参考样本,每个都与载玻片上的DNA混合。通过荧光镜检查,每边混合的RNA的强度变量记录(红或绿)被标记了。结果是,几千个数字(比如-6到6)衡量着目标样本中每个基因相对于参考样本的表达水平。正数表示的是目标样本比参考样本有着更高的表达水平,负数则反过来。
将一系列DNA微阵列实验的表达值收集在一起组成了一组基因表达的数据集,每列表示一次实验。几千行表示的是单个基因,几十列表示的是样本:在图1.3给出的具体例子中,有6830个基因(行)和64个样本(列),为了清晰表述,随机选了100行进行展示。这张图以热图的方式显示数据集,从绿(负)到红(正)。这些样本来自于64位癌症和肿瘤患者。
这里所面临的挑战是理解基因和样本是如何组织在一起的。常见的问题有:
-
哪一个样本的基因表达谱与其他样本的最相似?
-
哪一个基因的样本表达谱与其他基因的最相似?
-
对于特定的癌细胞样本,特定的基因表达会高还是低?
我们可以将这个问题看做是一个回归问题,有两个分类预测变量,基因和样本,将响应变量作为表达水平。然而,将它看做是非监督式学习可能更有用。比如,对于上面的(a)问题,我们把样本看成二维空间的6830个点,将这些点用某种方式聚合。
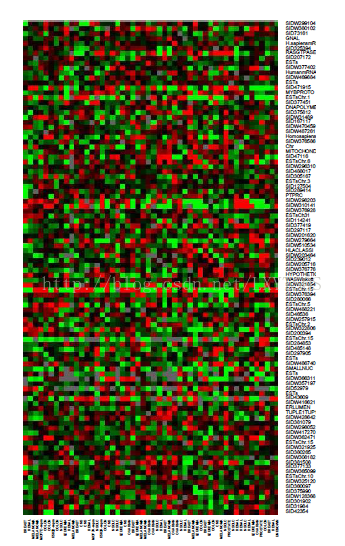
图1.3 DNA微阵列数据:人体肿瘤6830个基因(行)的表达矩阵和64个样本(列)。只显示了100个随机样本。以热图方式显示,从亮绿色(负,欠表达)到亮红色(正,过度表达)。灰色区域是缺失数据。行列随机排列。
(PS:翻译有不到位或错误的地方,还请各位指正。)














 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









