







阅读前疑问:
1.FasterRCNN的RPN 本来就是multi-scale的,印象中有27种,这篇文章针对人脸检测有什么改进么?
2.contextual是怎么结合附近信息?
驱动:
1.小的人脸使用rcnn难以检测
原始RCNN 一方面reception field大,所以小的脸占的比例就小,混入的背景信息就多了;另一方面,小的脸几次stride2以后到conv5太小了。
2.可以利用context信息(人体和脸一般是同时存在的)
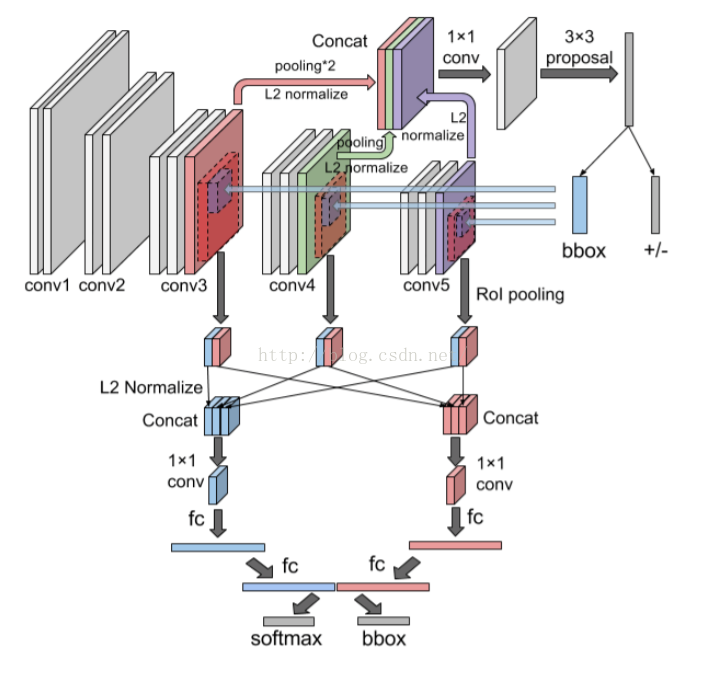
How:
1.MS-RPN(图中上半部分)还是在高层采用RPN,但是信息上将前两层的对应field的信息也取进来了。然后采用normal后concat,normal加上了一个系数gama来对不同层分配不同的比重。(需要注意:并没有在浅层上应用rpn)
2.而下半部分就是结合人体的信息。人体信息是按照人脸长宽位置,对应比例取的。比例是预先fix的参数
(疑问:如果框出图的边界的话用0padding么?)
3.train的过程中normal这一步可能作者花了功夫...
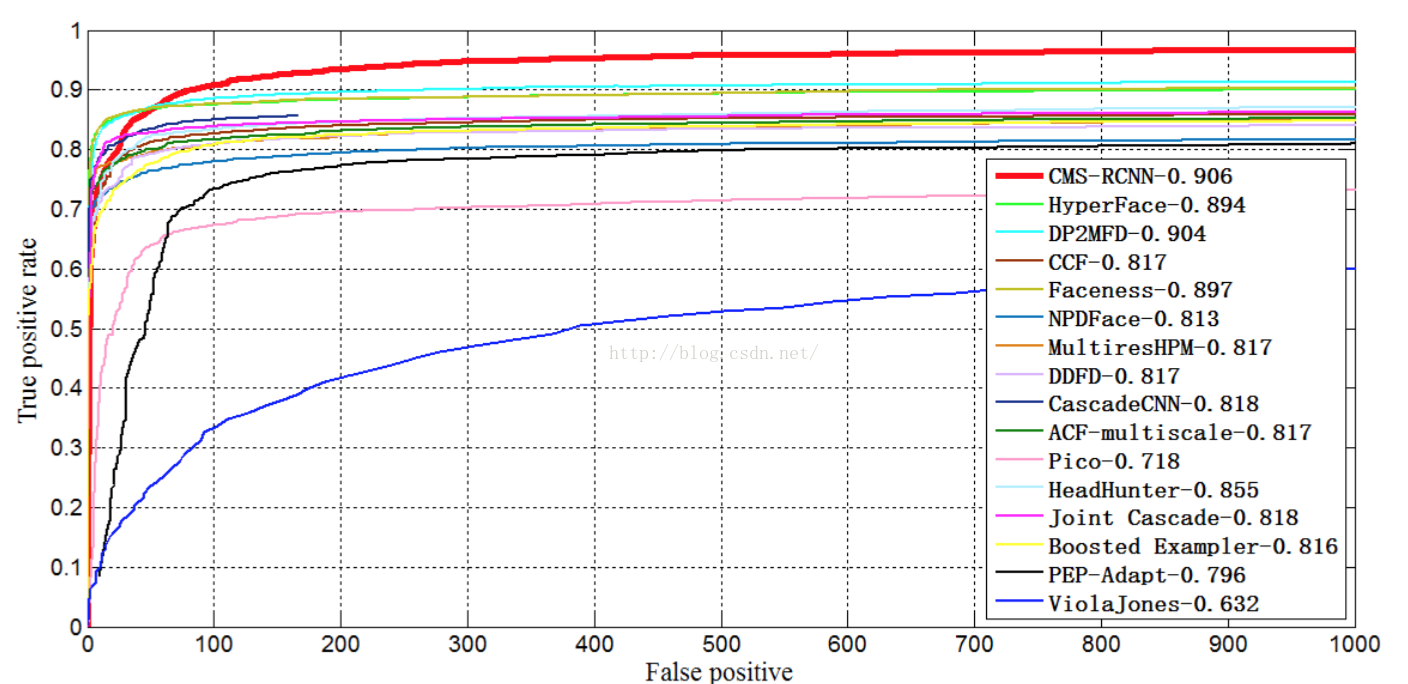
结果:

FDDB只放了discrete分数(少放一个连续得分)















 3967
3967











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











