







最近在项目中遇到了对配置文件做局部修改的需求,用到了Linux下的文本操作神器sed,本篇根据酷壳网《sed 简明教程》(http://coolshell.cn/articles/9104.html)来学习和记录一下sed命令的基本使用。
sed-stream editor
首先来了解一下sed的常见参数:
用法: sed [-nefri] [动作]
选项:
-n : 使用安静(silent)模式。在一般sed的用法中,所有来自STDIN的数据一般都会被列出到屏幕上。但如果加上-n参数后,则只有经过sed特殊处理的那一行(或者操作)才会被列出来。
-e : 直接在命令行模式上进行sed的动作编辑。
-f : 直接将sed的动作写在一个文件内,-f filename则可以执行filename内的sed动作。
-r : sed的动作支持的是扩展型正则表达式的语法(默认是基础正则表达式语法)。
-i : 直接修改读取的文件内容,而不是由屏幕输出。
动作说明: [n1[,n2]]function
n1, n2 :不一定会存在,一般代表“选择进行动作的行数”,举例来说,如果我的动作是需要在10到20行之间进行的,则“10,20[动作行为]”。
function有以下这些参数:
a :新增,a的后面可以接字符串,而这些字符串会在新的一行出现(目前的下一行)
c :替换,c的后面可以接字符串,这些字符串可以替换n1,n2之间的行
d :删除,因为是删除,所以d后面通常不接任何参数
i :插入,i的后面可以接字符串,而这些字符串会在新的一行出现(目前的上一行)
p :打印,也就是将某个选择的数据打印出来。通常p会与参数sed -n一起运行
s :替换,可以直接进行替换的工作。通常这个s的动作可以搭配正规表示法,例如 1,20s/old/new/g 1.用s命令替换
我们后面的操作均用以下这段文本做示例:
示例1:将文本中的my都替换为your
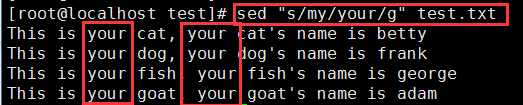
命令:sed "s/my/your/g" test.txt
说明:s表示替换命令,/my/表示匹配my,/your/表示把匹配替换成your,/g 表示全部替换,不加/g则只会替换每行的第一个匹配
一般用法:sed "s/要被替换的字符串/新的字符串/g" filename执行后,效果如下:
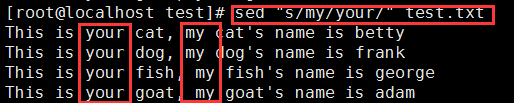
不加/g效果如下:
需要注意的是:上面的sed并没有改变文件的内容,只是把处理过后的内容输出,如果需要写回文件,可以使用重定向,如:
sed "s/my/your/g" test.txt > new_test.txt或者使用 -i 参数直接修改文件内容:
sed -i "s/my/your/g" test.txt还要注意的是:命令中我们可以用单引号或双引号,如果使用单引号,那么就没办法通过\’这样来转义,而在双引号内可以用\”来转义。
示例2:我们可以利用正则表达式来完成一些操作,正则表达式在文本的检索和替换方面作用巨大,如:
在每一行开头加点东西:sed 's/^/#/g' test.txt
(^ 匹配输入字符串的开始位置)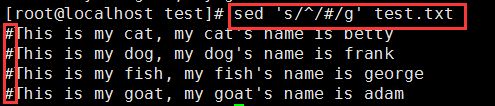
在每一行末尾加点东西:sed 's/$/.../g' test.txt
($ 匹配输入字符串的结束位置)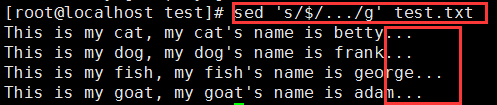
示例3:我们还可以指定需要替换的内容,如:
将第3行的my替换为your:sed "3s/my/your/g" test.txt
将第2到4行的my替换为your:sed "2,4s/my/your/g" test.txt
将每一行的第1个小写‘s’替换为大写‘S’:sed 's/s/S/1' test.txt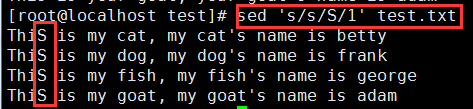
将每一行的第2个小写‘s’替换为大写‘S’:sed 's/s/S/2' test.txt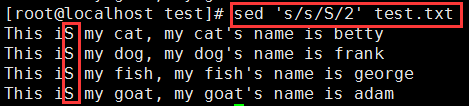
将每一行的第3个及以后的小写‘s’替换为大写‘S’:sed 's/s/S/3g' test.txt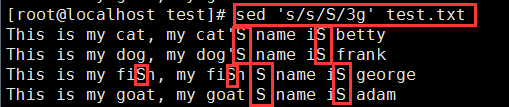
示例4:我们可以使用&来当做被匹配的变量,然后在被匹配的变量左右加点东西,如下:
给文本中的‘my’的左右都分别加上左、右中括号:sed 's/my/[&]/g' test.txt 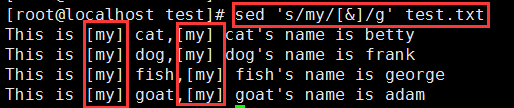
2.多个匹配和圆括号匹配
有时候我们需要一次替换多个模式,比如:
示例5:第一个模式把第一行到第三行的my替换成your,第二个则把第3行以后的This替换成了That
我们可以这样写:
sed '1,3s/my/your/g; 3,$s/This/That/g' test.txt
等价于
sed -e '1,3s/my/your/g' -e '3,$s/This/That/g' test.txt
(用到了-e:在sed命令传递多个编辑命令式时,要用到-e)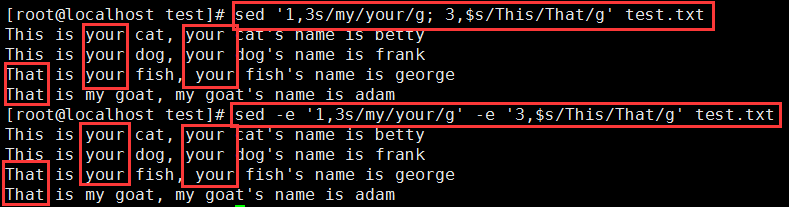
示例6:圆括号匹配即正则表达式中的分组,圆括号括起来的正则表达式所匹配的字符串可以当成变量来使用,用\1、\2…来表示
命令:sed 's/This is my \([^,]*\),.*is \(.*\)/\1:\2/g' test.txt说明:该行命令的作用是将 This is my\ ([^,]*\),.*is\ (.*\) 替换为 \1:\2。
正则表达式(去掉了转义字符)为This is my ([^,]*),.*is (.*),第一个匹配指匹配读到以逗号作为开头的地方的前面的信息,第二个匹配是指匹配任意数量的不包含换行的字符。一个匹配为:This is my (cat), ……is (betty),\1就是cat,\2就是betty。

3.sed的命令
N命令-把下一行的内容纳入当成缓冲区做匹配
示例7:sed 'N;s/my/your/' test.txt说明:本示例会把原文本中的偶数行纳入奇数行一起匹配(类似于将下一行的内容合并在一起进行匹配),且没有加/g,只匹配且替换一次
我们可以看到结果如下:

i命令-插入
在第1行前插入一行(insert):sed "1 i This is my monkey, my monkey's name is wukong" test.txt
a命令-追加
在最后一行后追加一行(append):sed "$ a This is my monkey, my monkey's name is wukong" test.txt
运用匹配来添加文本。
匹配到/fish/后就追加一行:sed "/fish/a This is my monkey, my monkey's name is wukong" test.txt
对每一行都追加一行......(因为每一行都能匹配到/my/):sed "/my/a ......" test.txt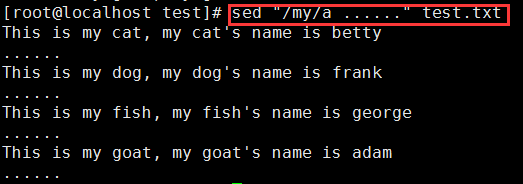
c命令-替换匹配行
将第二行的内容替换:sed "2 c This is my monkey, my monkey's name is wukong" test.txt
将匹配到fish那一行的内容替换(fish为第三行):sed "/fish/c This is my monkey, my monkey's name is wukong" test.txt
d命令-删除匹配行
删除第二行(第二行为dog):sed '2d' test.txt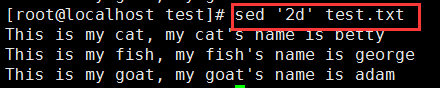
删除匹配到fish的行:sed '/fish/d' test.txt
删除第2行到最后一行:sed '2,$d' test.txt
p命令-打印
我们可以把p命令当作类似grep的命令。
我们来看这条命令:sed '/fish/p' test.txt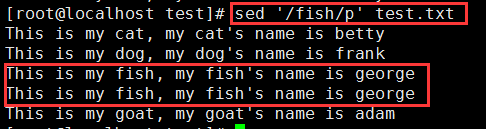
它的作用是匹配fish并输出,但是为什么fish那行会输出两遍呢,这是因为sed处理时会把处理的信息输出,我们加上-n选项就不会了:

从第一行打印到匹配fish成功的那一行:sed -n '1,/fish/p' test.txt















 1335
1335

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









