







数据缓冲区高速缓冲
缓冲头部

一个缓冲区有两部分组成:一个含有磁盘上数据的存储数组和一个标识该缓
冲区的缓冲头部。
一个缓冲区的数据与文件系统上一个逻辑磁盘块中的数据相对应,并且通过
考察缓冲头部中的标识字段来识别缓冲区内容。缓冲区是磁盘块在主存中的拷贝,
磁盘块的内容映射到缓冲区中。但是同一时刻,一个磁盘块不能映射到多个缓冲
区中。
设备号字段和块号字段指明了文件系统和磁盘上数据的块号,唯一地标识了
该缓冲区。设备号是逻辑文件系统号,不是物理设备号。缓冲区的数据部分必须
大于等于磁盘块的大小。
缓冲区的状态是有下列条件的组合:
1)缓冲区当前为“上锁”(忙)
2)缓冲区包含有效数据
3)内核把某缓冲区重新分配出去之前必须把该缓冲区内容写到磁盘上(延迟写)
4)内核当前正从磁盘往缓冲区读信息或把缓冲区的内容写到磁盘上
5)一个进程当前正在等候缓冲区变为闲。
缓冲池
内核按照最近最少使用算法把数据缓存于缓冲池中,内核维护一个缓冲区的
空闲表(双向链表),它保存最近被使用的次序。离空闲表最近的缓冲区比离空
闲表头远的缓冲区是最近最少使用的。
散列队列
内核把缓冲区组织成一个个队列,这些队列是按照设备号和块号散列的。内
核把一个散列队列上的缓冲区链接成一个个类似空闲表结构的双向链接循环表,
内核使用的散列函数也是简单的,这样保证性能。
一个缓冲区必须在散列队列里面,也可以在空闲表中。
缓冲区的检索
若果一个进程想要都一个文件中的数据,则内核需要判定数据在哪个文件系统
的哪个块上。当要从一个特定的磁盘上读取数据时,内核检测数据是否在缓冲区上,
若是在就直接可以从缓冲区上读取数据;否则,分一个空闲缓冲区。
读写磁盘块--算法getblk
内核给缓冲区分配磁盘块时,可能出现五种情况:
1)内核在散列队列找到该块,并且它的缓冲区是空闲的
2)内核在散列队列中找不到该块,因此,从空闲表中分配一个缓冲区
3)内核在散列队列中找不到该块,试图从空闲表中分配一个缓冲区的时候,
在空闲表中找到一个已经表上“延迟写”标记的缓冲区。内核必须该缓冲区的
内容写到磁盘上,并分配另外一个缓冲区。
4)内核在散列队列中找不到该块,并且空闲表已空。
5)内核在散列队列中找到该块,但是它的缓冲区为忙。
算法:getblk
输入:文件系统号 块号
输出:现在能被磁盘块使用的上了锁的缓冲区
{
while(没有找到缓冲区){
if(块在散列队列中){
if(块忙){/*第5种情况*/
sleep(等待“缓冲区变为空闲”事件);
continue;
}
为缓冲区标记上“忙”;
从空闲表中摘下缓冲区;
return (缓冲区);
}
else{
if(空闲表中没有缓冲区){/*第4种情况*/
sleep(等待“任何缓冲区变为空闲”事件);
continue;
}
从空闲表中摘下缓冲区;
if(缓冲区标记着延迟写){/*第3种情况*/
把缓冲区异步写到磁盘上;
continue;
}
从旧散列队列中摘下缓冲区;
把缓冲区投入新散列队列;
return (缓冲区);
}
}
}释放缓冲区算法brelse
算法:brelse
输入:上锁态的缓冲区
输出:无
{
唤醒正在等待缓冲区变为空闲的所有进程;
唤醒正在等待任何缓冲区变为空闲的所有进程;
提高处理机执行级以封锁中断;
if(缓冲区所有内容有效且缓冲区非旧)
将缓冲区送入空闲表尾部
else
将缓冲区送入空闲表头部
降低处理机执行级以允许中断;
给缓冲区解锁;
}情况1:内核搜索块4的实例图
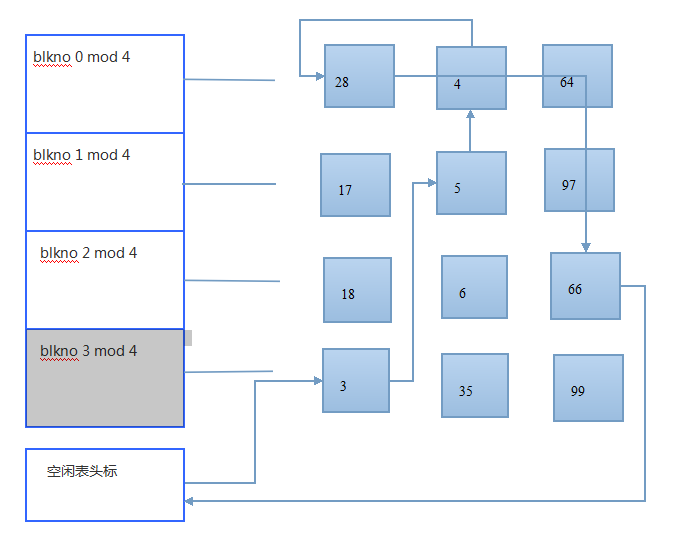
图--在散列队列上搜索块4
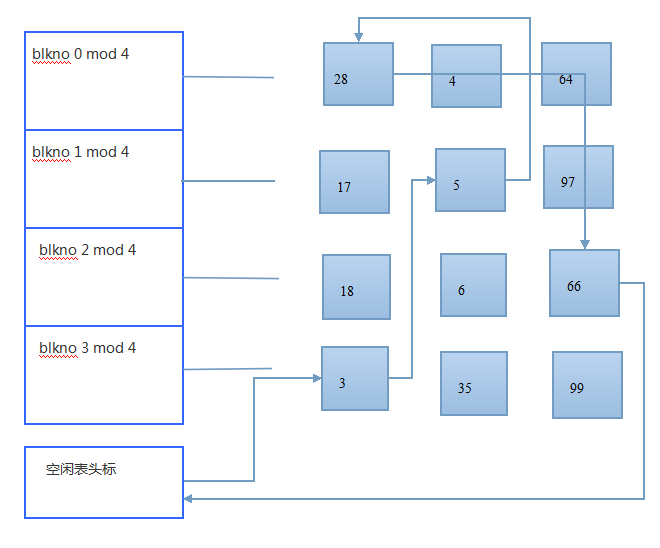
图--从空闲表上摘下第4块
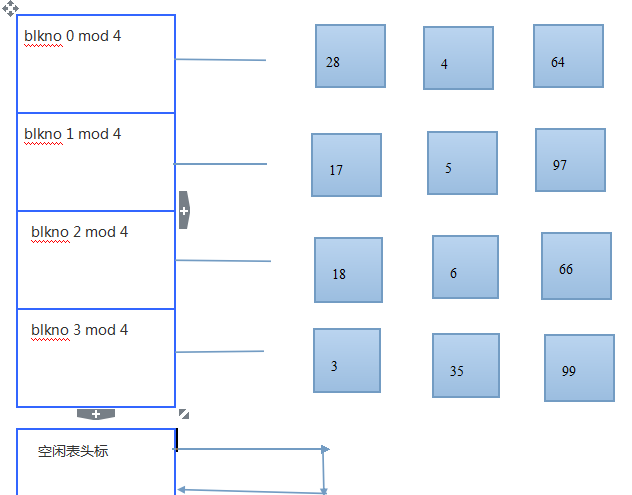
情况2:从缓冲区上找第21块
图--在缓冲区上搜索第21块
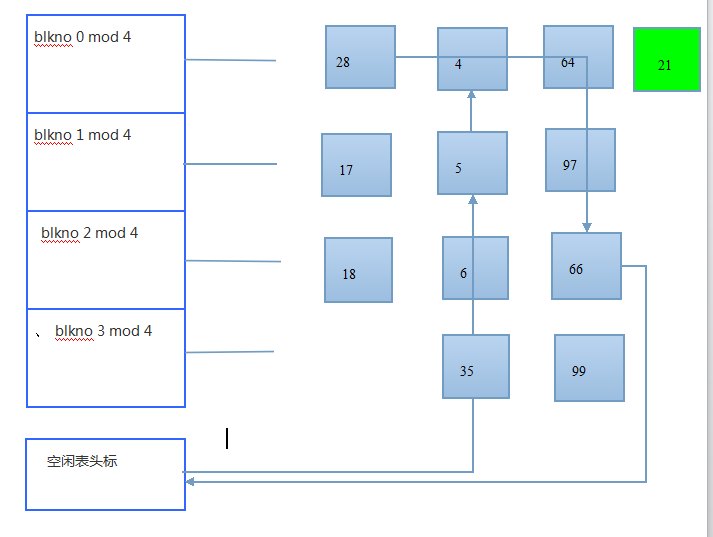
图--从空闲表中摘下第一个缓冲区,分配给第21块
重新给该块的缓冲区安置在相应的散列队列里面。
情况3:内核必须从空闲表中分配到一个缓冲区。
从空闲表中摘下的缓冲区已经被标上“延迟写”,因此,它必须在使用该缓冲区之前,
将缓冲区的内容写到磁盘上。内核开始了一个异步写,并且试图从空闲表上分配到
另外一个缓冲区。当异步写完成时,内核把该缓冲区释放,并把它放到空闲表的首部。
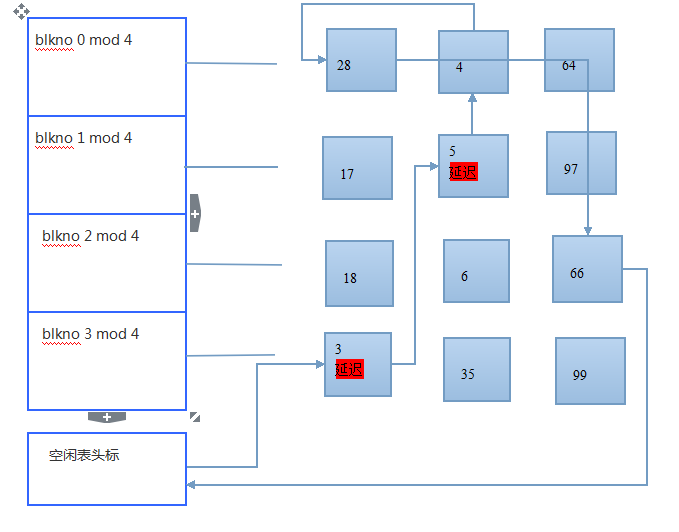
图-- 搜索第21块,空闲表上头两个缓冲区标记着延迟写
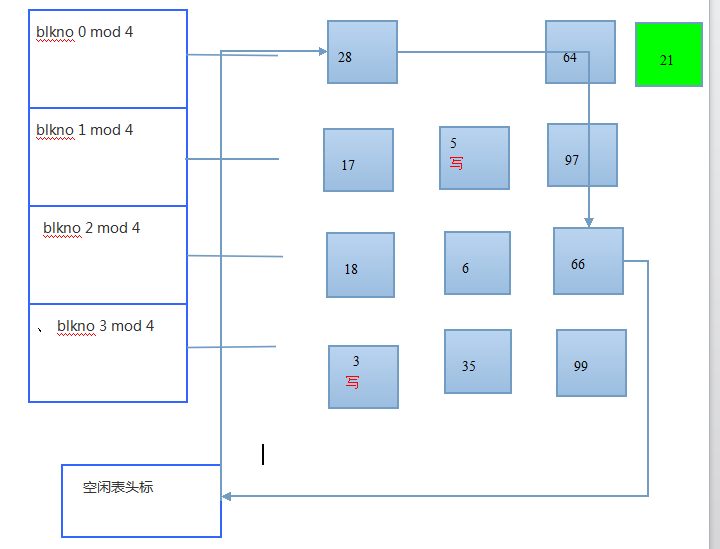
图--写第3块、第5块,把第4块的缓冲区分配该第21块
情况4:散列队列找不到该块,并且空闲表为空
进程A进入睡眠状态,直到有另外一个进程执行算法brelse,释放一个缓冲区。当内核
调度到进程A时,它必须重新为该块重新搜索散列队列,此举保证仅有一个缓冲区包含
该块。
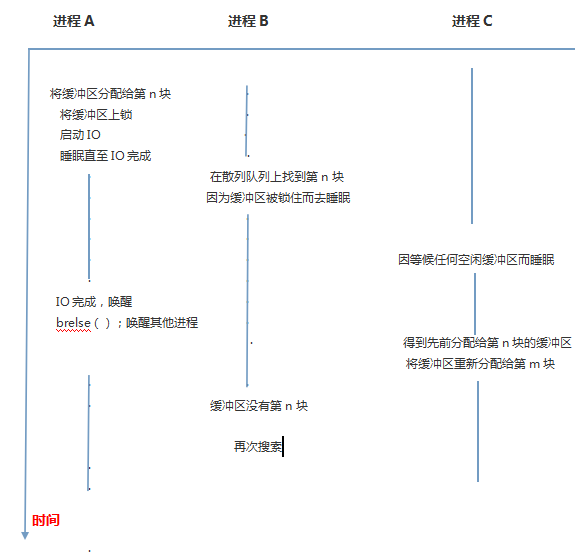
情况5:进程B等待进程A正在使用的块(忙),进程B将进入睡眠状态
进程A执行算法brelse,释放该缓冲区,这时将唤醒”缓冲区变为空闲“上睡眠的所
有进程,包括进程B。当内核调度到进程B执行时,进程B需要再次搜索该磁盘块。















 2748
2748

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









