










正则表达式学习
一、正则表达式语法
1、语法
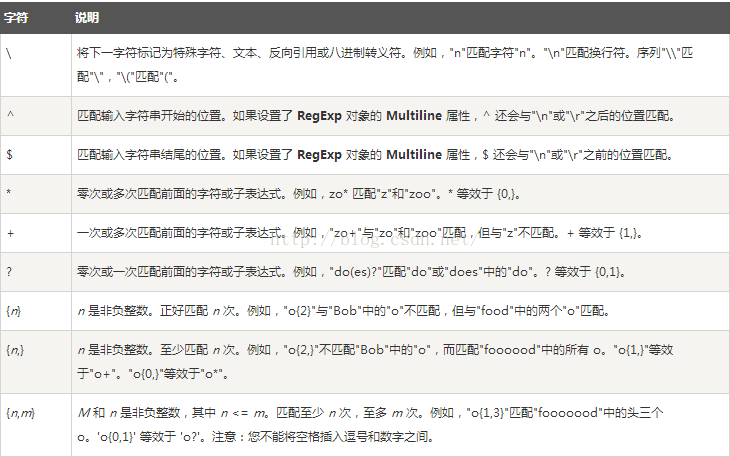

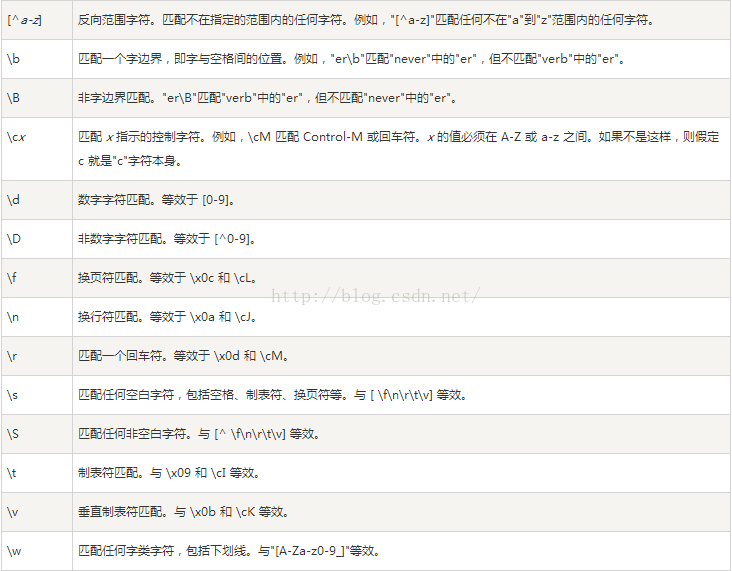
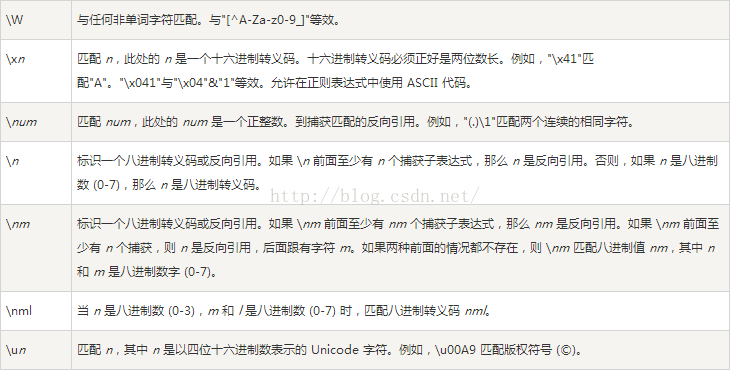
2、java API文档里面的介绍
如果觉得2这一部分有点多的话,直接看我这边的总结
:
******************************************总结***************************
①、java字符类中可以用&&表示且的意思
[a-z&&[def]] 表示d、e或f。既[a-z]和[def]的交集
[a-z&&[^bc]] 表示a到z,除了b和c。既从[a-z]中去掉[bc]
[a-z&&[^m-p]] 表示a-z中去掉[m-p]后的集合
②、特殊构造(非捕获)
| (?:X) | X,作为非捕获组 |
| (?idmsux-idmsux) | Nothing,但是将匹配标志idmsux on - off |
| (?idmsux-idmsux:X) | X,作为带有给定标志 i d m s u x on - off |
| (?=X) | X,通过零宽度的正 lookahead |
| (?!X) | X,通过零宽度的负 lookahead |
| (?<=X) | X,通过零宽度的正 lookbehind |
| (?<!X) | X,通过零宽度的负 lookbehind |
| (?>X) | X,作为独立的非捕获组 |
③、反斜杠、转义和引用
在不表示转义构造的任何字母字符前使用反斜线都是错误的;它们是为将来扩展正则表达式语言保留的。可以在非字母字符前使用反斜线,不管该字符是否非转义构造的一部分。
根据 Java Language Specification 的要求,Java 源代码的字符串中的反斜线被解释为Unicode 转义或其他字符转义。因此必须在字符串字面值中使用两个反斜线,表示正则表达式受到保护,不被 Java 字节码编译器解释。例如,当解释为正则表达式时,字符串字面值"\b" 与单个退格字符匹配,而"\\b" 与单词边界匹配。字符串字面值"\(hello\)" 是非法的,将导致编译时错误;要与字符串(hello) 匹配,必须使用字符串字面值"\\(hello\\)"。
④、字符类运算符的优先级,从最高到最低的顺序排列
| 1 | 字面值转义 | \x |
|---|---|---|
| 2 | 分组 | [...] |
| 3 | 范围 | a-z |
| 4 | 并集 | [a-e][i-u] |
| 5 | 交集 | [a-z&&[aeiou]] |
⑤、组和捕获
捕获组可以通过从左到右计算其开括号来编号。例如,在表达式 ((A)(B(C))) 中,存在四个这样的组:
1 ((A)(B(C))) 2 \A 3 (B(C)) 4 (C)
组零始终代表整个表达式。
之所以这样命名捕获组是因为在匹配中,保存了与这些组匹配的输入序列的每个子序列。捕获的子序列稍后可以通过 Back 引用在表达式中使用,也可以在匹配操作完成后从匹配器获取。
与组关联的捕获输入始终是与组最近匹配的子序列。如果由于量化的缘故再次计算了组,则在第二次计算失败时将保留其以前捕获的值(如果有的话)例如,将字符串"aba" 与表达式(a(b)?)+ 相匹配,会将第二组设置为"b"。在每个匹配的开头,所有捕获的输入都会被丢弃。
以 (?) 开头的组是纯的非捕获 组,它不捕获文本,也不针对组合计进行计数。
*******************************总结结束*******************************************











【学习技巧】:
在学习写正则表达式的时候,可以先在一些工具上面进行一些校验,这样可以很方便的进行初步校验你写的正则表达式的正确性。如你可以用OpenOffice,在百度搜索下就可以了,个人觉得这个工具还算不错,当然还有很多其他文本工具。
二、java API及实例
1、组group()、group(i)、groupCount()
// 按指定模式在字符串查找
String line = "AK47! OK?";
String pattern = "([A-Z]+)(\\d+)(.*)";
// 创建 Pattern 对象
Pattern r = Pattern.compile(pattern);
// 现在创建 matcher 对象
Matcher m = r.matcher(line);
int groupCount=m.groupCount();
if (m.find()) {
for(int i=0;i<=groupCount;i++){
System.out.println("group("+i+"):"+m.group(i));
}
} else {
System.out.println("NO MATCH!");
}
}运行结果:

说明:
从运行结果可以看出,([A-Z]+)(\\d+)(.*)这个正则表达式有四个分组:
0代表整个分组 ([A-Z]+)(\\d+)(.*)
1代表组 ([A-Z]+)
2代表组 (\\d+)
3代表组 (.*)
那为什么groupCount返回的结果却是3呢?原因是0不在groupCount()的计算返回值之内,group(0)比较特殊,代表的是整个表达式。从上面的结果来看,组()可以用来缓存匹配的数据,以便于后面的处理。但有时候有些组我们不需要获取它匹配到的值,这时候我们可以用(?:)来表示非捕获组,例如上面的例子中我们把正则表达式改为(?:[A-Z]+)(\\d+)(?:.*),则运行结果如下:

这个时候被?:修饰的那两个组都变为非捕获组,此时它们匹配到的内容不会被捕获保存到组里面,所以只剩下一个(\\d+)会捕获到数据,groupCount()返回的值为1。
2、获得索引start()、end()、start(group)、end(group)
// 按指定模式在字符串查找
String text = "AK47! 12ksdjfk445OK?";
String regex = "\\d+";
// 创建 Pattern 对象
Pattern r = Pattern.compile(regex);
// 现在创建 matcher 对象
Matcher m = r.matcher(text);
System.out.println("input:"+text);
System.out.println("regex:"+regex+"\n");
while(m.find()) {
System.out.println("匹配到:"+m.group()+"\t开始位置为:"+m.start()+"\t结束位置为:"+m.end());
}
运行结果为:

从结果中可以看出,group()会把与模式匹配的数字依次找出来,而strar()和end()会把匹配到的字符的位置返回,其中start()包含返回的位置,end()不包含。例如47的位置为索引2到4,但不包括4这个位置。
3、匹配matches()、lookingAt()
// 按指定模式在字符串查找
String text = "47AN";
String regex = "\\d+";
// 创建 Pattern 对象
Pattern r = Pattern.compile(regex);
// 现在创建 matcher 对象
Matcher m = r.matcher(text);
System.out.println("input:"+text);
System.out.println("regex:"+regex+"\n");
System.out.println("lookingAt:"+m.lookingAt());
System.out.println("matches:"+m.matches());
运行结果:

而如果把input改为AN47,结果为:

从上面的运行结果对比可以看出,lookingAt()是从整个字符串的开头去匹配,也就是从左到右去匹配,只要最开头的字符有满足模式的,它就会返回true(不管后面的字符会不会继续满足模式),否则为false;而matches()是需要字符串匹配整个模式才能方法true。例如我们平时用来校验身份证号或手机号码的匹配就是用到matches()这个方法。
4、替换replaceAll()、replaceFirst()
// 按指定模式在字符串查找
String text = "AN47 java2 C# .Net5";
String regex = "\\d+";
// 创建 Pattern 对象
Pattern r = Pattern.compile(regex);
// 现在创建 matcher 对象
Matcher m = r.matcher(text);
System.out.println("input:"+text);
System.out.println("regex:"+regex+"\n");
System.out.println("replaceAll替换后为:"+m.replaceAll("0"));
System.out.println("replaceFirst替换后为:"+m.replaceFirst("0"));运行结果为:

从运行结果可以看出replaceAll()会把所有匹配的数字都替换为0,而replaceFirst()只是把第一个替换为0。
另外,appendReplacement()、appendTail()也可以用来处理替换
// 按指定模式在字符串查找
String text = "AN47 java2 C# .Net5 php";
String regex = "\\d+";
// 创建 Pattern 对象
Pattern r = Pattern.compile(regex);
// 现在创建 matcher 对象
Matcher m = r.matcher(text);
System.out.println("input:"+text);
System.out.println("regex:"+regex+"\n");
StringBuffer result=new StringBuffer();
while(m.find()){
m.appendReplacement(result, "0");
}
// m.appendTail(result);
System.out.println("替换后为:"+result);
}
运行结果:
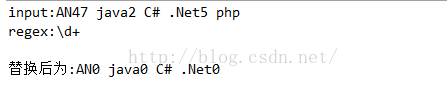
可以看出,替换成功了。但你有没有发现返回的结果少了点什么?跟input比较,可以发现php不见了,这是为什么呢?原因是我把m.appendTail(result)这一句注释掉了,这一句的作用是把尾部没有匹配的字符添加到返回的结果result中,也就是说,一般情况下,appendReplacement()和appendTail()是配套使用的。我们去掉注释后,再来看看运行结果:

这时候php就回来了
5、格式化数据
public static void main(String args[]){
String input="20161209,20161210,20161211";
forMat1(input, '-');
}
public static void forMat1(String input,char separator){
String regex="(\\d{4})(\\d{2})(\\d{2})";
Matcher m=Pattern.compile(regex).matcher(input);
while(m.find()){
System.out.print(m.group()+"\t格式化后为:");
System.out.println(m.group(1)+separator+m.group(2)+separator+m.group(3));
}
}运行结果:

public static void main(String args[]){
String input="20161209,20161210,20161211";
forMat2(input, '-');
}
public static void forMat2(String input,char separator){
String regex="(\\d{4})(\\d{2})(\\d{2})";
String format="$1"+separator+"$2"+separator+"$3";
Matcher m=Pattern.compile(regex).matcher(input);
while(m.find()){
System.out.print(input+"\t格式化后为:");
System.out.println(m.replaceAll(format));
}
}














 366
366











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









