







1、阿里巴巴国际站的股票代码是1688,这个数字具有这样的特性,首先是个首位为1的4位数,其次恰巧有且仅有1个数字出现了两次。类似的数字还有:1861,1668等。这样的数字一共有()个
A144
B180
C216
D270
E288
F432
答案:F
2、由权值分别为1、12、13、4、8的叶子节点生成一颗哈夫曼树,它的带权路径长度为()
A12
B68
C43
D6
E25
F81
答案:F
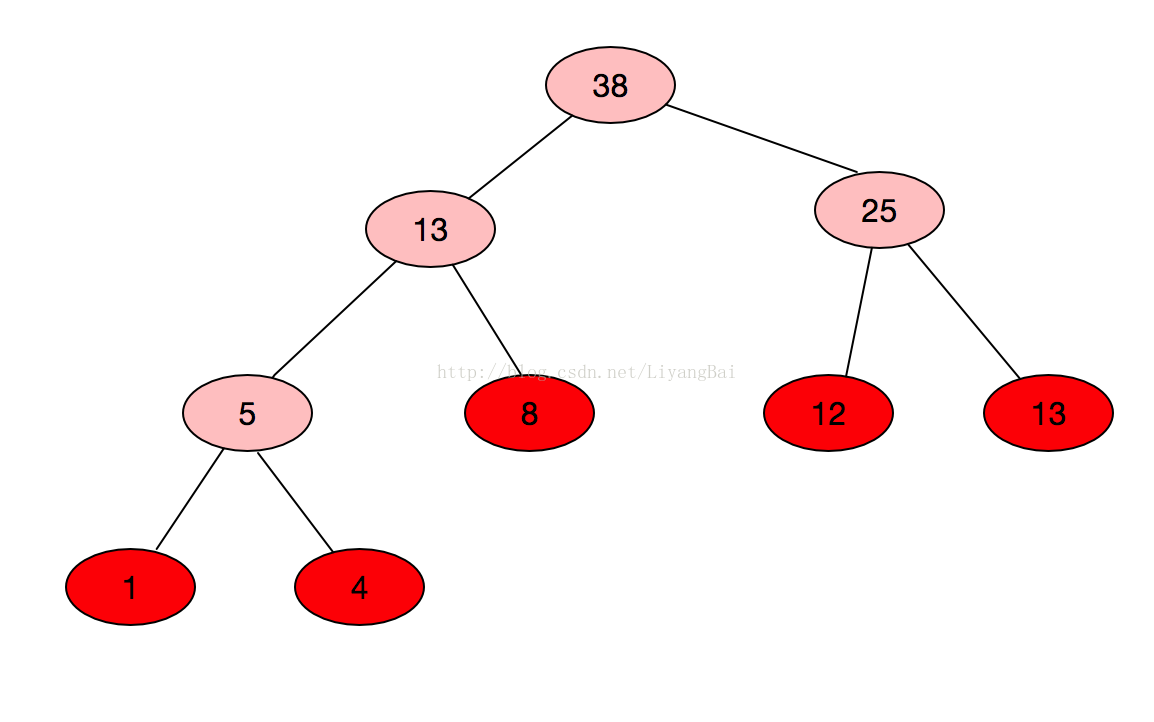
带权路径长度为所有叶子节点的权值*其路径长度:(1+4)*3+8*2+(12+13)*2=81
3、n个数值选出最大m个数(3<m<n)的最小算法复杂度是
AO(n)
BO(nlogn)
CO(logn)
DO(mlogn)
EO(nlogm)
FO(mn)
答案:A
4.下面哪一个不是动态链接库的优点?
A共享
B装载速度快
C开发模式好
D减少页面交换
答案:B
5、下列不是进程间的通信方式的是()
A管道
B回调
C共享内存
D消息队列
Esocket
F信号量
答案:B
进程间共享通信的方式主要有:管道、信号量、消息队列、共享内存、信号、套接口
# 信号量( semophore ) : 信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
# 消息队列( message queue ) : 消息队列是由消息的链表,存放在内核中并由消息队列标识符标识。消息队列克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点。
# 共享内存( shared memory ) :共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是最快的 IPC 方式,它是针对其他进程间通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号两,配合使用,来实现进程间的同步和通信。
6、已知IBM的PowerPC是big-endian字节序列而Intel的X86是little-endian字节序,如果在地址啊存储的整形值时0x04030201,那么地址为a+3的字节内存储的值在PowerPC和Intel X86结构下的值分别是?
A1 4
B1 3
C4 1
D3 1
E4 4
F1 1
答案:A
大端从大地址开始存储,小端相反,两者都是从数据低位开始存起;
假设从上至下地址递增,则
PowerPC(大): Intel X86(小):
04 01 低
03 02 |
02 03 |
01 04 高
a+3指向最大的地址,所以分别为1 4
7、在Logistic Regression中,如果同时加入L1和L2范数,会产生什么效果()
A可以做特征选择,并在一定程度上防止过拟合
B能解决维度灾难问题
C能加快计算速度
D可以获得更准确的结果
答案:A
L1范数具有系数解的特性,但是要注意的是,L1没有选到的特征不代表不重要,原因是两个高相关性的特征可能只保留一个。如果需要确定哪个特征重要,再通过交叉验证。
为什么L1,L2范数可以防止过拟合呢
在代价函数后面加上正则项,L1即是Losso回归,L2是岭回归
但是它为什么能防止过拟合呢?
奥卡姆剃刀原理:能很好的拟合数据且模型简单
模型参数在更新时,正则项可使参数的绝对值趋于0,使得部分参数为0,降低了模型的复杂度(模型的复杂度由参数决定),从而防止了过拟合。提高模型的泛化能力
8、下面关于B-和B+树的叙述中,不正确的是
AB-树和B+树都是平衡的多叉树
BB-树和B+树都可用于文件的索引结构
CB-树和B+树都能有效地支持顺序检索
DB-树和B+树都能有效地支持随机检索
答案:C
9、在分类问题中,我们经常会遇到正负样本数据量不等的情况,比如正样本为10w条数据,负样本只有1w条数据,以下最合适的处理方法是()
A将负样本重复10次,生成10w样本量,打乱顺序参与分类
B直接进行分类,可以最大限度利用数据
C从10w正样本中随机抽取1w参与分类
D将负样本每个权重设置为10,正样本权重为1,参与训练过程
答案:ACD
10、以下几种模型方法属于判别式模型的有
1)混合高斯模型
2)条件随机场模型
3)区分度训练
4)隐马尔科夫模型
A1,4
B3,4
C2,3
D1,2
11、B-树的插入算法中,通过结点的向上"分裂",代替了专门的平衡调整()
A对
B错
12、对二叉树的结点从1开始进行连续编号,要求每个结点的编号大于其左、右孩子的编号,在同一结点的左、右孩子中,其左孩子的编号小于其右孩子的编号,可采用()次序的遍历实现编号
A前序
B中序
C后序
D从根开始按层次遍历
答案:C
13、堆是满二叉树()
A对
B错
答案:B
堆是完全二叉树,但不是满二叉树。
14、下面有关序列模式挖掘算法的描述,错误的是?
AAprioriAll算法和GSP算法都属于Apriori类算法,都要产生大量的候选序列
BFreeSpan算法和PrefixSpan算法不生成大量的候选序列以及不需要反复扫描原数据库
C在时空的执行效率上,FreeSpan比PrefixSpan更优
D和AprioriAll相比,GSP的执行效率比较高
15、如下表是用户是否使用某产品的调查结果()
UID年龄 地区 学历 收入 用户是否使用调查产品
1低 北方 博士 低 是
2高 北方 本科 中 否
3低 南方 本科 高 否
4高 北方 研究生 中 是
请计算年龄,地区,学历,收入中对用户是否使用调查产品信息增益最大的属性(Log23≈0.63)
A年龄
B地区
C学历
D收入
16、深度学习是当前很热门的机器学习算法。在深度学习中,涉及到大量矩阵相乘,现在需要计算三个稠密矩阵A,B,C的乘积ABC,假设三个矩阵的尺寸分别为m*n,n*p,p*q,且m<n<p<q,以下计算顺序效率最高的是:()
AA(BC)
B(AB)C
C(AC)B
D所有效率都相同
17、二叉树是度为2的有序树()
A对
B错
答案:B
二叉树说的是孩子节点的个数是2,如左右节点
19、类域界面方程法中,不能求线性不可分情况下分类问题近似或精确解的方法是?
A伪逆法
B感知器算法
C基于二次准则的H-K算法
D势函数法
20、下面有关分类算法的准确率,召回率,F1值的描述,错误的是?
A准确率是检索出相关文档数与检索出的文档总数的比率,衡量的是检索系统的查准率
B召回率是指检索出的相关文档数和文档库中所有的相关文档数的比率,衡量的是检索系统的查全率
C正确率、召回率和 F 值取值都在0和1之间,数值越接近0,查准率或查全率就越高
D为了解决准确率和召回率冲突问题,引入了F1分数
21、以下哪个是常见的时间序列算法模型
ARSI
BMACD
CARMA
DKDJ
22、在图G的最小生成树G1中,可能会有某条边的权值超过未选边的权值()
A对
B错
答案:B
23、下列时间序列模型中,哪一个模型可以较好地拟合波动性的分析和预测
AAR模型
BMA模型
CARMA模型
DGARCH模型
24、二叉树的第I层上含有的结点数最多为()
A2I
B2I-1-1
C2I-1
D2I-1
答案:C
25、关于支持向量机SVM,下列说法错误的是()
AL2正则项,作用是最大化分类间隔,使得分类器拥有更强的泛化能力
BHinge 损失函数,作用是最小化经验分类错误
C分类间隔为1/||w||,||w||代表向量的模
D当参数C越小时,分类间隔越大,分类错误越多,趋于欠学习
















 3041
3041











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











