









实验环境:
Ubuntu 14.04
所需环境:
Caffe(GPU)
Python2.7
JUPYTER NOTEBOOK
所需依赖包:
numpy
matplotlib
skimage
h5py
本次实验采用的网络介绍:
在ICIR论文《VERY DEEP CONVOLUTIONAL NETWORK SFOR LARGE-SCALE IMAGE RECOGNITION》中,作者提出了VGG的神经网络模型。VGG网络的介绍如图1所示。
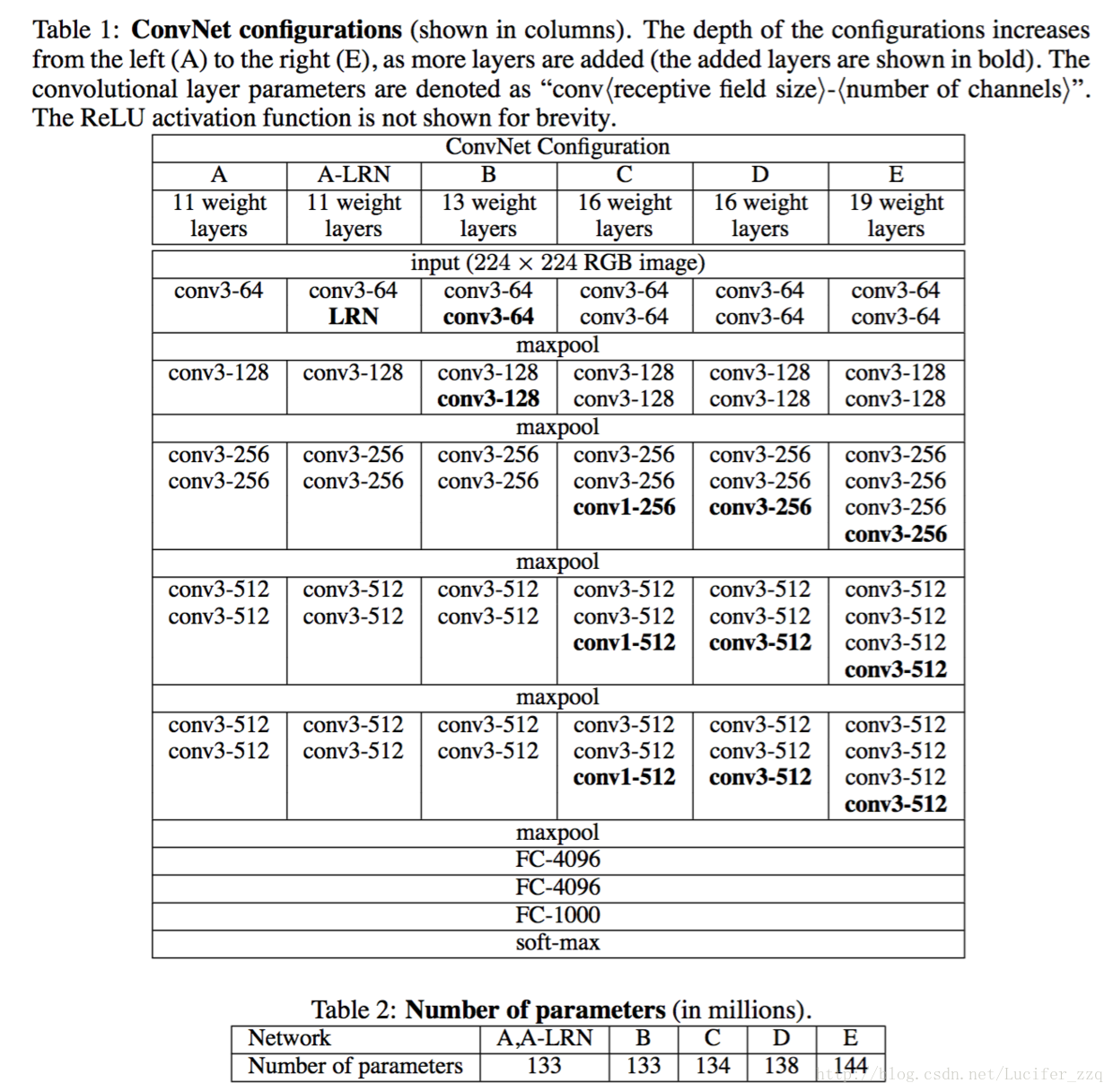
在我们的实验中,我们采用的是D类网络,这个网络的示意图如下:
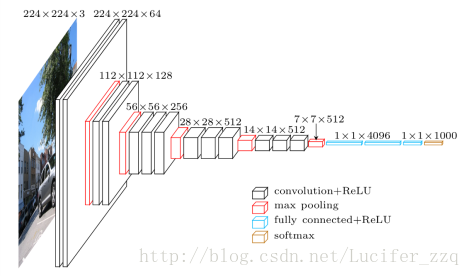
网络的输入是一张224*224的图片,之所以要乘一个3,是因为有3个通道。经过很多个规模为3*3的卷积核提取了很多个特征。如224*224*3到224*224*64这经过了64个3*3的卷积核,换言之,可以理解为提取了原来图片的64个特征。经过一次池化后(在这里采用的是max-pooling),图片规模变为了112*112*64。经过一系列的操作,输出是一个1000*1的向量,向量中每一个元素的值是一种概率的表征。因此这个向量中1000个数字的和为1。在我们的实验中只运行了前向过程。
要运行VGG16,在github上面有很多资源,本次实验的代码来源:
https://github.com/ry/tensorflow-vgg16
下载资源并解压后:首先在terminal中运行make,会自动下载文件:
VGG_ILSVRC_16_layers.caffemodel
这个文件中保存了VGG16的weight和bias。
文件VGG_2014_16.prototxt,保存了VGG16的结构。
文件tf_forward.py,描述了VGG16的前向传播过程。
那现在我们思考一个问题:
假如我们对于最后的1000个数据不是很感兴趣,而是想提取中间某一层的特征呢?
比如说,我们想提取最后一个卷积层的输出Cov_5(14*14*512),和第二个全连接层的输出FC7(4096*1)并进行比较。那我们又应该怎么做呢?
首先,将Cov_5进行降维处理将其转化为一个512*1的矩阵。这就涉及到了对于每一个14*14的矩阵都需要进行一次特征提取。我的操作是提取每一个14*14矩阵的最大值。
conv5_3=net_caffe.blobs[‘conv5_3’].data[0]
conv = [ [] for i in xrange(np.size(conv5,2)) ]
for i in xrange(np.size(conv5,2)):
//按块划分区域,一块区域14*14的大小如果n=0,按行;n=1,按列取最大值
conv[i]=np.max(conv5[:,:,i]) //将最大值存入conv[i]
为了将512*1的向量和4096*1的向量进行比较。需要将两个向量进行L2正则化。
L2正则化:平方和开根号。
conv_norm=conv/np.sqrt(np.sum(np.square(conv)))
np.squre()代表对数组取平方操作
np.sum()代表对数组进行求和操作
np.sqrt()代表对数组进行求平方根操作
同理,再将FC7提取到的矩阵如法炮制即可。














 3001
3001











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









