







最近一直在看machinelearning in action这本书,学习到很多知识,目前花费时间最多的是在Classification里面的svm(Support vector machines),主要原因是里面涉及到的数学相关的知识之前没有接触过,故本文边补习数学知识边学习svm.
1 svm简介
svm(支持向量机)主要就是在一个高维或者无限维中构造一个hyperplane(超平面),通过这个hyperplane将数据分割开来,从而达到分类目的。
a support vector machine constructs a hyperplane or set of hyperplanes in a high- or infinite-dimensional space, which can be used for classification, regression, or other tasks(http://en.wikipedia.org/wiki/Support_vector_machine)
2 什么是hyperplane?
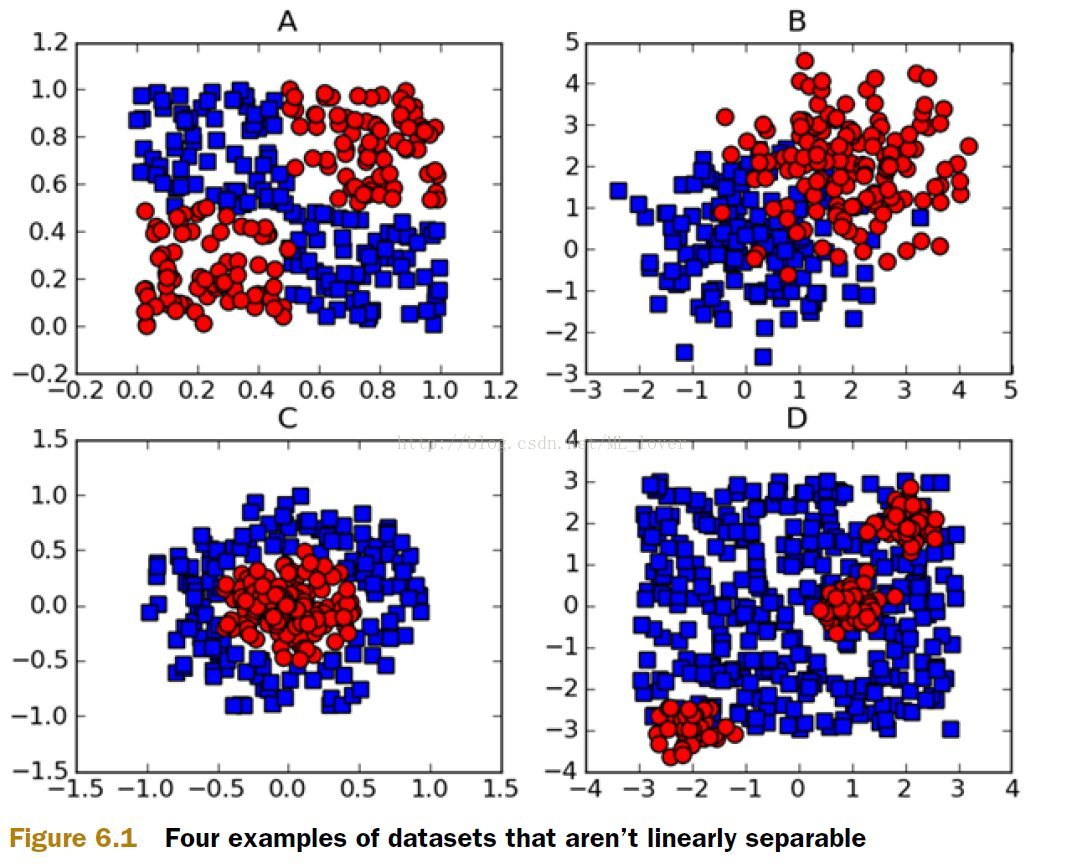
图6.1上的ABCD中的数据,能否用一条直线将颜色不同的数据区分出来呢?
那图6.2上的ABCD中的数据呢?
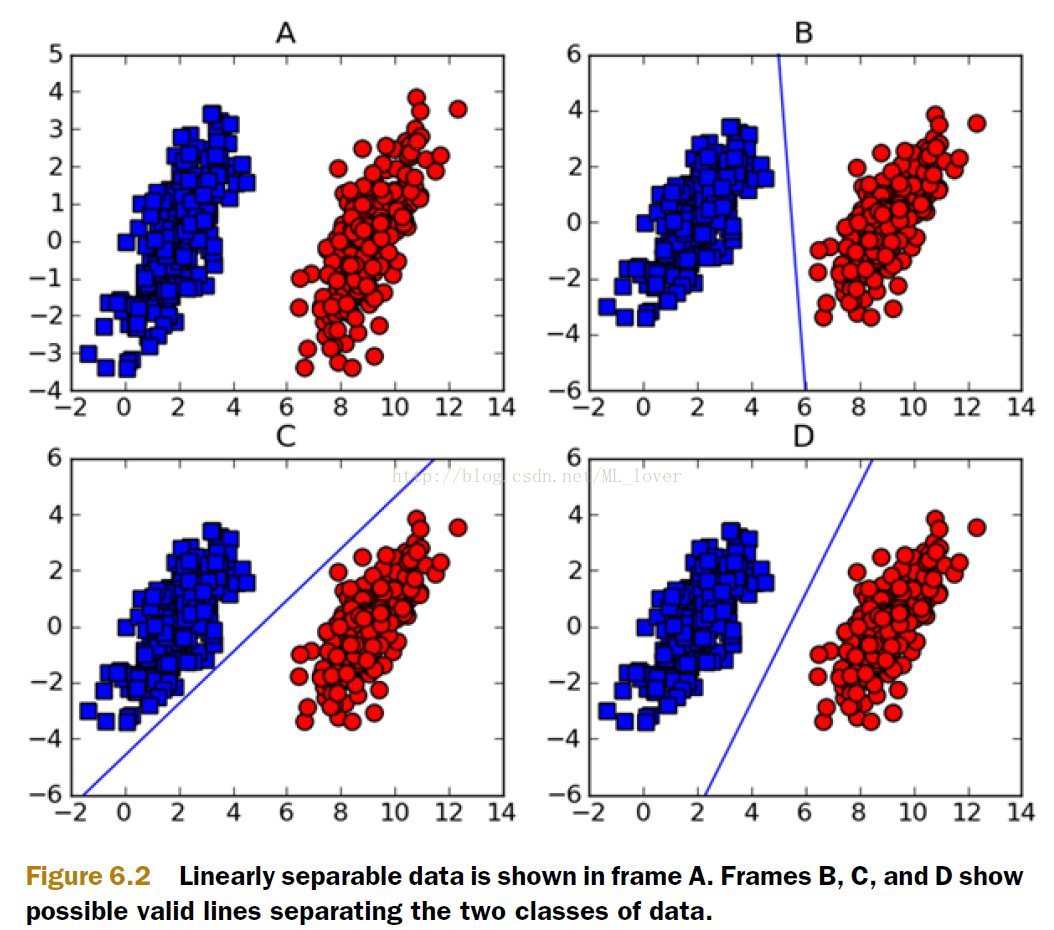
很明显图6.2中的数据是可以用直线来将不同类型的数据划分开来,存在这样的一中解决方案,就说,这些数据是linearly separable(线性可分),同时这条用来分割图上的数据集的直线就被称为separating hyperplane(分离超平面),在2维上,separating hyperplane就是个直线(y=kx+b),如果我们的数据集是3D的,那么用来划分3D数据的就是个平面,如果我们的数据是1024D的话,我们需要一个1023D的东西来划分目标数据,那这个1023D的东西是什么呢?或者说1023D这个对象该怎么称呼它呢,在抽象到N维上呢?我们就把这一个N-1D的对象称呼为hyperplane,hyperplane就是我们的decision boundary(判断边界),理想情况下,同一个边界范围内的数据是属于同一类对象的(实践情况下总有一些特殊的数据会跑到另外一个边界去了,后面在谈)。
3 什么是margin?
从图6.2上B、C、D上来看,这些hyperplane都可以将数据分开,那么哪一个是我们真正需要的?也就是说哪一个是最优的?对于我们来说,We’d like to make our classifier in such a way that the farther a data point is from the decision boundary, the more confident we are about the prediction we’ve made。
对于图6.2的B和C来说,BC上点到面的平均距离似乎比D的要少,按照平均距离这中方法去寻找最佳直线是否可行呢?按照平均距离来说是可行的,但是这并不是最好的主意。
We’d like to find the point closest to the separating hyperplane and make sure this is as far away from the separating line as possible. This is known as margin (我们需要找到每类中距离分离超平面最近的点,同时确保这些点远离这个超平面,越远越好,这就是所谓的margin)
PS:在http://en.wikipedia.org/wiki/Support_vector_machine上,margin是这样定义的
we can select two hyperplanes in a way that they separate the data and there are no points between them, and then try to maximize their distance. The region bounded by them is called "the margin"
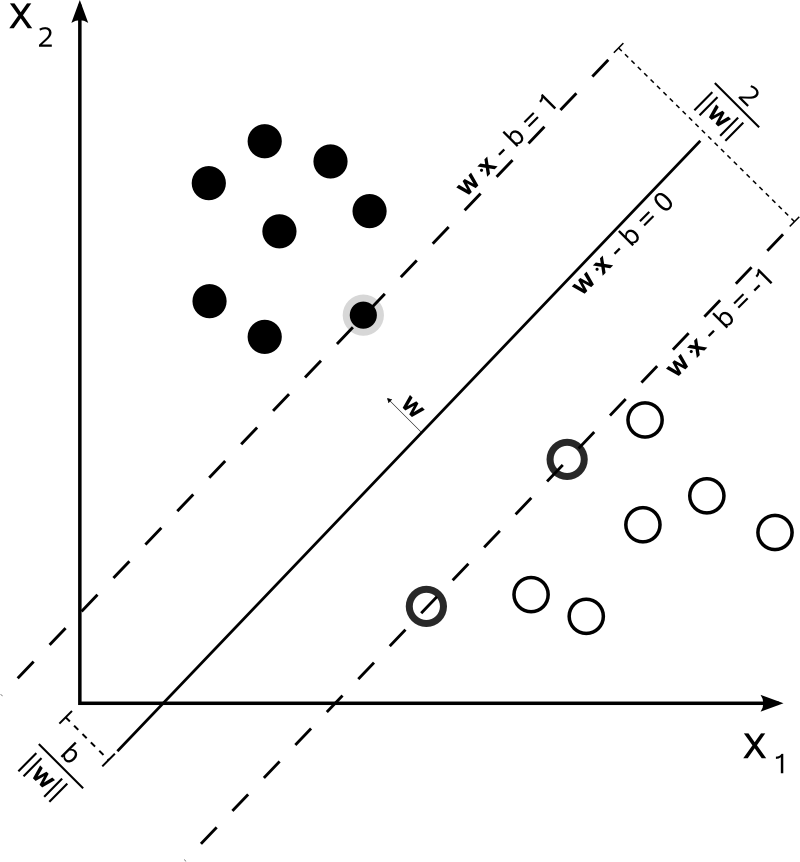
Maximum-margin hyperplane and margins for an SVM trained with samples from two classes. Samples on the margin are called the support vectors.
4 什么是support vector
在0x03中末尾的那些点,就是所谓的support vector(按照wiki上的定义就是margin上的点就是support vectors)。
5 目标
现在要做的就是找到一个hyperplane,使得support vectors距离hyperplane最大。
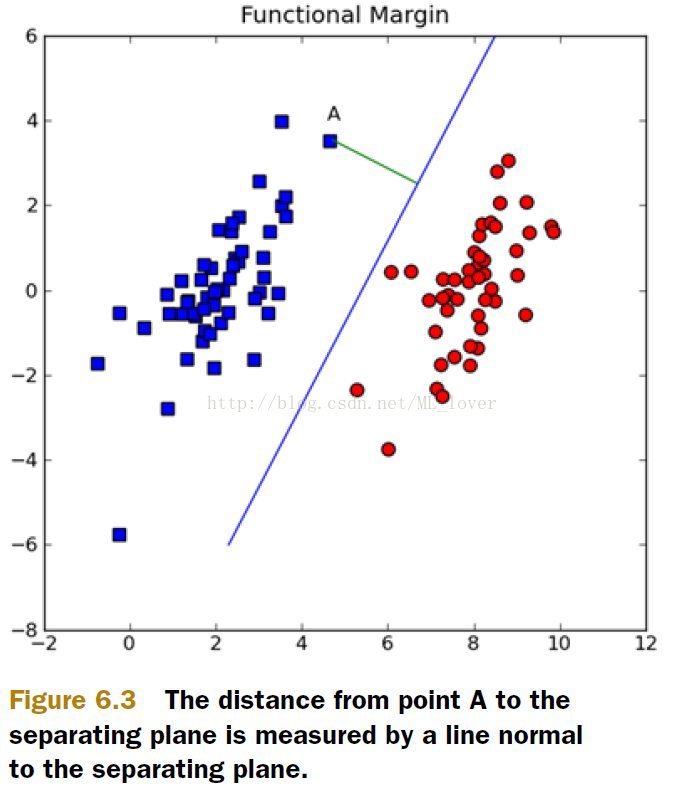
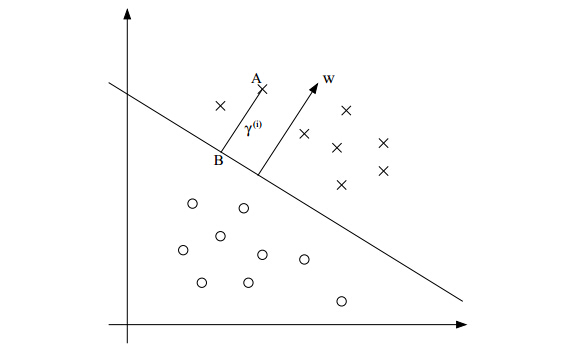
看图6.3,超平面可以用W’X+b来表示,W、X都是vector,如果我们要确定A到线的垂直距离,可以用|W‘X+b| /||W||来表示。
b就像是一个截距,比如一元线性方程y=kx+b中的b,W和b全部一起描述了这个hyperplane(线)
6 sigmoid函数
定义:
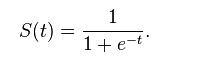
图像:
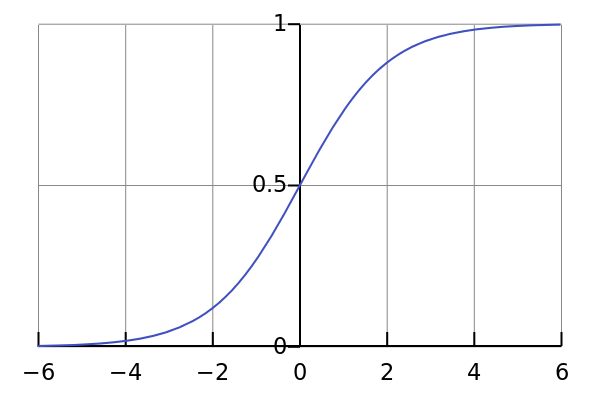
(http://en.wikipedia.org/wiki/Sigmoid_function)
PS:第一次听到和见到sigmoid函数是Ng在视频中提到的:)
从sigmoid函数可以看到这个函数的特性,在定义区间内,当x=0的时候,y=0.5,当x大于0后,y迅速区域1,当x小于0时,y迅速趋于0。鉴于这种特性,可以定义一个类似sigmoid的函数f(W‘X+b),这样f(x)当x<0的时候,f(x)取-1,反之取1,sigmoid的值是0和1,为什么要用class labels的值-1和1去代替0和1呢?Why did we switch from class labels of 0 and 1 to -1 and 1? This makes the math manageable, because -1 and 1 are only different by the sign.(主要原因是为了从数学计算方便考虑的,符号上的0、1、-1并不影响真正的分类)
Y*f(W’X+b),这里Y也是个vector,取值{-1,1},可以看到如果某个点i离超平面很远 时候,比如规定6.3中红色点的label取值为1,蓝色取值为-1,那么当点是属于红色的时候,Yi*(W‘X)是一个很大的整数,当点i是蓝色,Yi取值-11的时候,那么Yi*(W‘X)也是一个很大的正数。反正不会出现负数情况.
考虑到以下情况,如图所示:
上图中点A到超平面的距离假设为:
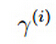
超平面的单位法向量为:
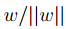
点A在超平面的投影点B,所以点B可以由点A来描述: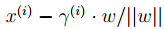
由于点B在超平面上,所以满足:
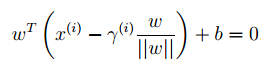
那么就得到了:
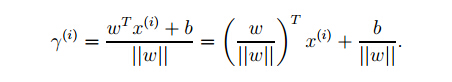
那么任意一点到超平面的几何距离都可以表示为:
同时根据这个式子,可以发现,当缩放W和b的时候,比如w变成2w,b变成2b的时候,实际的几何距离表示并没有发生改变support vector到超平面的距离可以表示为:
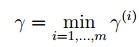
那么我们的问题就可以变成:
从上图可以看到,两类的support vector之间的距离为:2/||W||
所以现在的问题就是要求 2/||W||的最大值,也就是求||W||的最小值,||W||是个平方根,所以求
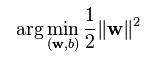
跟原问题是一样的效果,系数1/2是为了数学计算上的方便而添加的,不影响结果。
此时问题就成了一个:
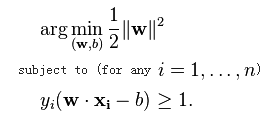
这是一个quadratic programming optimization 问题,可以用QP的解决方法来解决,但是为了使SVM便于扩展,从另外一个角度来解决此问题(Lagrange duality),这样带来的好处就是allowing us to use kernels to get optimal margin classifiers to work efficiently in very high dimensional spaces(我的理解就是便于引入核函数,使得SVM的用途更加广泛)。
7 什么是Lagrange duality?
Lagrange duality个人理解是分为2部分,首先是 Lagrange multiplier,然后就是duality。先来说说Lagrange multiplier
7.1什么是 Lagrange multiplier?
Lagrange multiplier中文就是拉格朗日乘子,为什么要提到它?(http://en.wikipedia.org/wiki/Lagrange_multiplier)
在数学优化上,使用和引入拉格朗日乘子可以解决含有等式约束的问题,并找到这个问题的优解。
例如 含有等式约束的问题可以描述为:
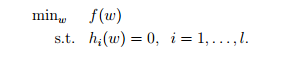
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 206
206











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









