







本文摘录一些平时遇到的、需要留意的、C语言方面的语法和用法。
但不收录那些很少用到的不重要的地方,除非我觉得它有意思。
-------------------------------------------------------------------------------------------------------------------------------------
参考资料:
1、《C语言深度解剖》 2016.06
2、《让你不再害怕指针》
3、
-------------------------------------------------------------------------------------------------------------------------------------
-4、
-------------------------------------------------------------------------------------------------------------------------------------
-3、全局变量限制只出现在一个文件中,提供专门的读写函数给外部文件操作这些变量。
-------------------------------------------------------------------------------------------------------------------------------------
-2、.注释要写"为什么这样写"、说明思路和作用
.不用写"如何实现"、除非真的不易读,如公式推导而来的代码。
-------------------------------------------------------------------------------------------------------------------------------------
-1、./**/ 会被编译器用空格 " " 替换,所以 in/**/t i = 0; 会被编译器报错。
."\" 换行符/继续符后面不能有空格 " ",否则 "\" 会被编译器视为是转义符+空格 " " 而被编译器报错。
同时要注意换行后、第二行可能会习惯性的先打空格,这些空格会被连接到第一行后面。
如:#def\
ine
会被连接成:#def ine
-------------------------------------------------------------------------------------------------------------------------------------
0、stu.name 中的 "." 可以认为是从 stu 中取出指定的偏移 name。
-------------------------------------------------------------------------------------------------------------------------------------
1、bool 变量与 0 的比较
定义: BOOL b_flag = FALSE;
最好的写法:if(b_flag); if(!b_flag);
可接受写法:if(b_flag == 1); if(b_flag = 0);
有风险写法:if(b_flag == TRUE); if(b_flag == FALSE);解释:FASE的定义一般都是0,TRUE的定义一般是1或-1。
也就是说FALSE和TRUE都是人为定义的,可能不都是0和1,尤其是TRUE。
另外、有的时候我们需要使用 不为0即是真 来作为判定条件。
-------------------------------------------------------------------------------------------------------------------------------------
2、浮点数之间的比较
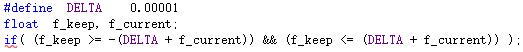
浮点数之间的比较不能直接比较,要比较一个范围,因为浮点数存储时都是有误差的,不是原值。
DELTA用来指定比较的精度。
另外、差异很大的两个浮点数之间的运算,结果很可能是错的。
-------------------------------------------------------------------------------------------------------------------------------------
3、函数的参数不要多于4个
否则CPU的处理效率会降低,参数多了可以用struct打包。
-------------------------------------------------------------------------------------------------------------------------------------
4、用typedef给类型重命名
(1).
const int temp; 和 int const temp; 等价
(2).
typedef struct student
{
int data;
...
} stu_data, *stu_ptr;
const stu_data temp; 和 stu_data const temp; 等价
const stu_ptr p_temp; 和 stu_ptr const p_temp; 等价原因在于 typedef 定义的 stu_data 和 stu_ptr 都是一个类型,对编译器来说、他们和 (1) 例中的 int 这个类型在地位上平等。
因此编译器处理 stu_data const temp; 和 stu_ptr const p_temp; 时,与处理 int const temp; 时的过程一致。
虽然在 stu_ptr 的定义中有指针符号 * ,但它不是独立的,而是和 struct student 绑定在一起的。
所 stu_ptr const p_temp; 和 struct student const * temp;是不一样的:前者是 stu_ptr const 类型的指针,后者是 struct student 类型的const指针。
另外,虽然 stu_ptr 是一个类型,但 unsigned stu_ptr 却不能被编译器识别,因为编译器... ?
|<----待解释-question-001
5、#define 常量表达式时、留意常量的范围
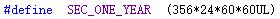
6、#error之error-information 不用加双引号



7、数组a 的名字代表数组首元素a[0]的首地址,而不是整个数组的首地址
8、函数返回的局部指针是野指针
|<----待验证=question-002
9、malloc(0) 返回不可用的地址
10、定义一个返回数组指针的函数
typedef int(*pf_array_2(void))[2]; // 对应指针
int(*fun_return_pArray2(void))[2]
{
int temp[2] = {1, 2};
int (*p)[2] = &temp;
return p;
}typedef int(*p_array_2)[2]; // 定义返回值
p_array_2 fun_return_pArray2(void)
{
int temp[2] = {1, 2};
int (*p)[2] = &temp;
return p;
}typedef int(*p_array_2)[2];
extern p_array_2 fun_return_pArray2(void);11、结构体变量初始化的理想通用方法
#include
struct student_st
{
char c;
int score;
const char *name;
};
static void show_student(struct student_st *stu)
{
printf("c = %c, score = %d, name = %s\n", stu->c, stu->score, stu->name);
}
int main(void)
{
// method 1: 按照成员声明的顺序初始化
struct student_st s1 = {'A', 91, "Alan"};
show_student(&s1);
// method 2: 指定初始化,成员顺序可以不定,Linux 内核多采用此方式
struct student_st s2 =
{
.name = "YunYun",
.c = 'B',
.score = 92,
};
show_student(&s2);
// method 3: 指定初始化,成员顺序可以不定
struct student_st s3 =
{
c: 'C',
score: 93,
name: "Wood",
};
show_student(&s3);
return 0;
}struct student_st stus[2] =
{
{
.c = 'D',
.score = 94,
/*也可以只初始化部分成员*/
},
{
.c = 'D',
.score = 94,
.name = "Xxx"
},
};-------------------------------------------------------------------------------------------------------------------------------------
12、位域的类型
struct student {
unsigned char a1:4;
unsigned int b2:4;
unsigned long c3:4,
c4:4;
unsigned long long d4:4,
d5:4;
}stu_charlotte;
unsigned long size_long;
unsigned long long size_long_long;
cout << "sizeof(size_long) = " << sizeof(size_long) << endl;
cout << "sizeof(size_long_long) = " << sizeof(size_long_long) << endl;
cout << "sizeof(stu_charlotte) = " << sizeof(stu_charlotte) << endl;sizeof(size_long) = 4
sizeof(size_long_long) = 8
sizeof(stu_charlotte) = 16
struct student {
unsigned char a1:4;
unsigned int b2:4;
unsigned long c3:4,
c4:4;
unsigned long long d4:4,
d5:4;
unsigned int number;
}stu_charlotte;
unsigned long size_long;
unsigned long long size_long_long;
cout << "sizeof(size_long) = " << sizeof(size_long) << endl;
cout << "sizeof(size_long_long) = " << sizeof(size_long_long) << endl;
cout << "sizeof(stu_charlotte) = " << sizeof(stu_charlotte) << endl;sizeof(size_long) = 4
sizeof(size_long_long) = 8
sizeof(stu_charlotte) = 24














 695
695











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









