






一、数据预处理
数据矩阵X,维度是【N*D】N是数据样本数,D是数据维度
1.均值减法
它对数据中每个独立特征减去平均值,从几何上可以理解为在每个维度上都将数据云的中心都迁移到原点
X-=np.mean(X,axis=0)
2.归一化
先对数据做零中心化,然后每个维度都除以其标准差,实现代码为X/=np.std(X,axis=0)(对每一列)
3.PCA和白化(Whitening)
先对数据进行零中心化处理,然后计算协方差矩阵,它展示了数据中的相关性结构
X-=np.mean(X,axis=0)
cov=np.dot(X.T,X)/X.shape[0] #协方差矩阵
U,S,V=np.linalg.svd(cov) #进行奇异值分解运算
U的列是特征向量,S是装有奇异值的1维数组,为了去除数据相关性,将已经零中心化处理过的原始数据投影到特征基准上
Xrot=np.dot(X,U)
因为U的列是标准正交向量,所以投影对应X中的一个旋转,旋转产生的结果就是新的特征向量。
由于U中特征向量是按照特征值的大小排列的,我们可以利用这个性质来对数据降维,只使用前面小部分的特征向量,丢掉后面的
Xrot_reduced=np.dot(X,U[:,:100])
【白化】输入为特征基准上的数据,然后对每个维度除以其特征值来对数值范围进行归一化。经过白化后,数据分布将会是一个均值为0,协方差相等的矩阵
注意: 数据预训练一定要在训练集上操作,不能再验证集或者测试集上操作,应该先分训练/验证/测试集,然后只在训练集中求图片平均值,然后各个集中的图像再减去这个平均值
二、权重初始化
错误:全0初始化
因为如果网络中的每个神经元都计算出同样的输出,然后它们就会在反向传播中计算出同样的梯度,从而进行同样的参数更新,这样神经元之间就失去了不对称性的源头
1.小随机数初始化
W=0.01* np.random.randn(D,H) ,其中randn函数是基于零均值和标准差的一个高斯分布来生成随机数的
warning:并不是小数值一定会得到好的结果,比如一个神经网络的层中的权重值很小, 那么在反向传播的时候就会计算出非常小的梯度,这就会很大程度上减小反向传播中的“梯度信号”,在深度网络中就会出现问题
2.使用1/sqrt(n)校准方法
w=np.random/randn(n)/sqrt(n)这样可以保证网络中所有神经元起始时有近似同样的输出分布,这样可以提高收敛速度
3.稀疏初始化
将权重矩阵设为0,每个神经元都同下一层固定数目的神经元随机连接
4、偏置(biases)初始化
通常都设为0,因为W已经打破了对称性
5.Batch Normalization 批量归一化
其做法是让激活数据在训练开始前通过一个网络,网络处理数据使其服从标准高斯分布。因为归一化是一个简单可求导的操作,所以上述思路是可行的。在实现层面,应用这个技巧通常意味着全连接层(或者是卷积层,后续会讲)与激活函数之间添加一个BatchNorm层。
其实如果是仅仅使用上面的类似于白化的归一化公式,对网络某一层A的输出数据做归一化,然后送入网络下一层B,这样是会影响到本层网络A所学习到的特征的。打个比方,比如我网络中间某一层学习到特征数据本身就分布在S型激活函数的两侧,你强制把它给我归一化处理、标准差也限制在了1,把数据变换成分布于s函数的中间部分,这样就相当于我这一层网络所学习到的特征分布被你搞坏了,这可怎么办?于是文献使出了一招惊天地泣鬼神的招式:变换重构,引入了可学习参数γ、β,这就是算法关键之处:
每一个神经元xk都会有一对这样的参数γ、β。这样其实当:
、
是可以恢复出原始的某一层所学到的特征的。因此我们引入了这个可学习重构参数γ、β,让我们的网络可以学习恢复出原始网络所要学习的特征分布。最后Batch Normalization网络层的前向传导过程公式就是:

上面的公式中m指的是mini-batch size。
6. Batch Renormalization
转自:http://blog.csdn.net/baidu_32173921/article/details/65448478
统计学上有一个问题叫Internal Covariate Shift,我也不知道该怎么翻译,暂且叫它ICS吧。说的是这样一个事情,即在偏统计的机器学习中,有这样一个假设,要求最初的数据的分布和最终分类结果的数据分布应该一致,一般来讲它们的条件分布应该是相同的,但是它们的边缘密度就不一定了,,在我们的神经网络中,相当于每一层都是对原数据的一个抽象映射和特征提取,但是对于每一层来说,我们的target是一致的,可我们每一层都是一个映射啊,数据的边缘分布肯定是不一样的,这时候就尴尬了。
可我们的BN做的是这样一个事情,把它变成一个0均值1方差的分布上(不包括后面修正),这样在一定程度上,可以减小ICS带来的影响,可是也不是完全解决,毕竟你只保证了均值和方差相同,分布却不一定相同。
本文系batch norm原作者对其的优化,该方法保证了train和inference阶段的等效性,解决了非独立同分布和小minibatch的问题。其实现如下:
其中r和d首先通过minibatch计算出,但stop_gradient使得反传中r和d不被更新,因此r和d不被当做训练参数对待。试想如果r和d作为参数来更新,如下式所示: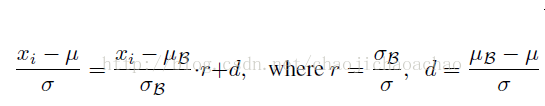
这样一来,就相当于在训练阶段也使用moving averages μ和σ,这会引起梯度优化和normalization之间的冲突,优化的目的是通过对权重的scale和shift去适应一个minibatch,normalization则会抵消这种影响,而moving averages则消除了归一化后的激活对当前minibatch的依赖性,使得minibatch丧失了对每次权重更新方向的调整,从而使得权重尺度因normalization的抵消而无边界的增加却不会降低loss。而在前传中r和d的仿射变换修正了minibatch和普适样本的差异,使得该层的激活在inference阶段能得到更有泛化性的修正。这样的修正使得minibatch很小甚至为1时的仍能发挥其作用,且即使在minibatch中的数据是非独立同分布的,也会因为这个修正而消除对训练集合的过拟合。
从Bayesian的角度看,这种修正比需要自己学习的scale和shift能更好地逆转对表征的破坏,且这种逆转的程度是由minibatch数据驱动的,在inference时也能因地制宜,而scale和shift对不同数据在inference时会施加相同的影响,因此这样的修正进一步降低了不同训练样本对训练过程的影响,也使得train和inference更为一致。
L2正则化可能是最常用的正则化方法了。可以通过惩罚目标函数中所有参数的平方将其实现。即对于网络中的每个权重,向目标函数中增加一个,其中是正则化强度。L2正则化可以直观理解为它对于大数值的权重向量进行严厉惩罚,倾向于更加分散的权重向量。在线性分类章节中讨论过,由于输入和权重之间的乘法操作,这样就有了一个优良的特性:使网络更倾向于使用所有输入特征,而不是严重依赖输入特征中某些小部分特征。最后需要注意在梯度下降和参数更新的时候,使用L2正则化意味着所有的权重都以w += -lambda * W向着0线性下降。
四、Dropout
在训练的时候,随机失活的实现方法是让神经元以超参数的概率被激活或者被设置为0。
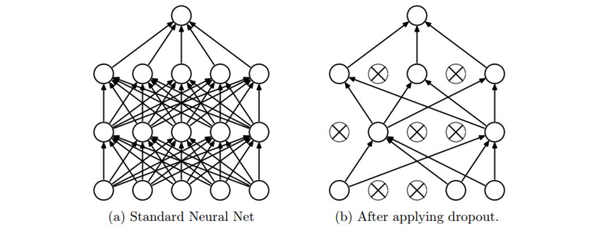
在训练过程中,随机失活可以被认为是对完整的神经网络抽样出一些子集,每次基于输入数据只更新子网络的参数(然而,数量巨大的子网络们并不是相互独立的,因为它们都共享参数)
在测试过程中不使用随机失活,可以理解为是对数量巨大的子网络们做了模型集成(model ensemble),以此来计算出一个平均的预测。
注意:在predict函数中不进行随机失活,但是对于两个隐层的输出都要乘以,调整其数值范围。以
为例,在测试时神经元必须把它们的输出减半,这是因为在训练的时候它们的输出只有一半。为了理解这点,先假设有一个神经元
的输出,那么进行随机失活的时候,该神经元的输出就是
,这是有
的概率神经元的输出为0。在测试时神经元总是激活的,就必须调整
来保持同样的预期输出。在测试时会在所有可能的二值遮罩(也就是数量庞大的所有子网络)中迭代并计算它们的协作预测,进行这种减弱的操作也可以认为是与之相关的。
实际更倾向使用反向随机失活(inverted dropout),它是在训练时就进行数值范围调整,从而让前向传播在测试时保持不变。这样做还有一个好处,无论你决定是否使用随机失活,预测方法的代码可以保持不变。反向随机失活的代码如下:
p = 0.5 # 激活神经元的概率. p值更高 = 随机失活更弱
def train_step(X):
# 3层neural network的前向传播
H1 = np.maximum(0, np.dot(W1, X) + b1)
U1 = (np.random.rand(*H1.shape) < p) / p # 第一个随机失活遮罩. 注意/p!
H1 *= U1 # drop!
H2 = np.maximum(0, np.dot(W2, H1) + b2)
U2 = (np.random.rand(*H2.shape) < p) / p # 第二个随机失活遮罩. 注意/p!
H2 *= U2 # drop!
out = np.dot(W3, H2) + b3
# 反向传播:计算梯度... (略)
# 进行参数更新... (略)
def predict(X):
# 前向传播时模型集成
H1 = np.maximum(0, np.dot(W1, X) + b1) # 不用数值范围调整了
H2 = np.maximum(0, np.dot(W2, H1) + b2)
out = np.dot(W3, H2) + b3
六、损失函数
数据损失是对所有样本的数据损失求平均。
1.分类问题
这类问题中,常见的损失函数有
SVM:
Softmax分类器:
2.属性分类
上面两个损失公式的前提,都是假设每个样本只有一个正确的标签yi,但如果yi是一个二值向量, 每个样本可能有,也可能没有某个属性。如一张图
可以同时有多个标签,这种情况下,为每个属性创建一个独立的二分类的分类器。
3.回归问题
是预测实数的值的问题,通常是计算预测值和真实值之间的损失,然后用L2平方范式度量差异,对于某个样本,L2范式计算如下:
注意: L2损失比起稳定的Softmax损失来,其优化过程要困难得多。它需要对于每个输入都要输出一个确切的正确值,而softmax中,每个评分的准确值并不是那么重要,而是比较的量级。而且L2损失的鲁棒性不好,因为异常值可以导致很大的梯度,所以在面对一个回归问题时,先要考虑能不能转化为分类问题。尽量把输出变成二分类,然后对它们进行分类。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









