







0.序言
聚类算法是机器学习领域非常简单同时也非常经典的算法,聚类所处理的对象是未标记的样本,所以属于无监督学习这一范畴。聚类算法从原理上大致课划分为3类:(1)基于原型的聚类(2)基于密度的聚类(3)基于层次的聚类,而在每一类下面又有好多算法,今天我要介绍的就是k均值聚类算法,它属于”基于原型聚类“这一类别。
( 先提个问题:有没有发现,聚类这块的算法非常之多,比机器学习的其他分支算法明显多太多了,原因?)
首先要来了解的一个概念就是聚类,下面来谈谈聚类和分类的区别,聚类简单地说就是把相似的东西分到一组,同 Classification (分类)不同,对于一个 classifier ,通常需要你告诉它“这个东西被分为某某类”这样一些例子,理想情况下,一个 classifier 会从它得到的训练集中进行“学习”,从而具备对未知数据进行分类的能力,这种提供训练数据的过程通常叫做 supervised learning (监督学习),而在聚类的时候,我们并不关心某一类是什么,我们需要实现的目标只是把相似的东西聚到一起,因此,一个聚类算法通常只需要知道如何计算相似 度就可以开始工作了,因此 clustering 通常并不需要使用训练数据进行学习,这在 Machine Learning 中被称作 unsupervised learning (无监督学习)。
1. 基础知识介绍
1.1距离度量方式
欧几里得距离:
其意义就是两个元素在欧氏空间中的集合距离,因为其直观易懂且可解释性强,被广泛用于标识两个标量元素的相异度,
表达公式:曼哈对距离:
两个n维向量a(x11,x12,…,x1n)与b(x21,x22,…,x2n)间的曼哈顿距离可以表示为:
闵可夫斯基距离:
切比雪夫距离:
二个点之间的距离定义为其各座标数值差的最大值。以(x1,y1)和(x2,y2)二点为例,其切比雪夫距离为:
(今天咱们要讲的k-means cluster就是采用欧氏距离来计算样本到聚类中心之间的距离)
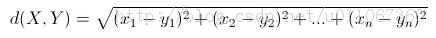
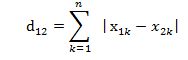
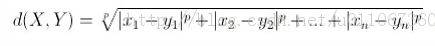
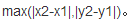
1.2划分相关的概念
- 划分的概念最早是在“集合”中出现的,划分的准确定义如下:
集合A的幂集P(A)的一个子集π={A1,A2,…,Ak}满足:
(1)π中没有空集
(2)A1,A2,…,Ak两两不相交
(3)所有集合的并集A1∪A2∪…∪Ak=A
称π是集合A的一个划分。 实际上,在聚类中,如果我们将所有的聚类样本看成是一个集合的话,聚类的结果实际上就相当于对样本进行了一个划分(请注意:一个划分,说明按照不同的划分标准就有不同的划分结果),划分后的每一类称为一个“簇”。
**下面放一张图大家感受一下,将样本划分成了3个簇:
(观察仔细的同学会发现每一个每个簇中间位置会有一个“+”,那个实际上就是聚类中心,用+来标记,聚类中心可以理解成所谓的“原型”)
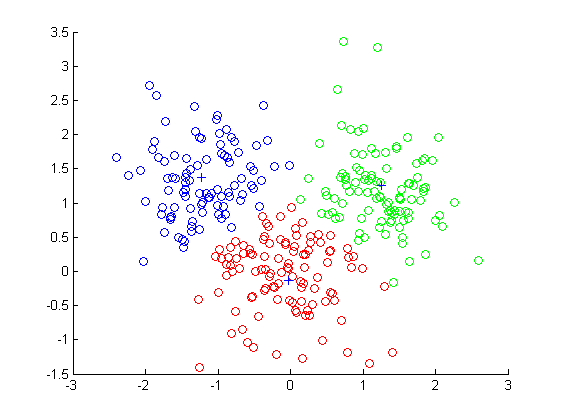
2聚类算法讲解
2.1 所要求解的问题
- 假设我们提取到原始数据的集合为(x1, x2, …, xn),并且每个xi为d维的向量,K-means聚类的目的就是,在给定分类组数k(k ≤ n)值的条件下,将原始数据分成k类
S = {S1, S2, …, Sk},在数值模型上,即对以下表达式求最小值:
其中, - 可以看出来这是一个优化问题,咱们的目标就是求得一个划分(确定最佳k值,然后找出一个最优划分)使得J最小(J越小表明簇内样本越近,簇间样本距离越远),理论证明这是一个NP难的问题,怎么办呢?
破解思路:
采用贪心策略,大致策略如下图所示:
(该算法简单,但是他背后的东西绝不简单,有兴趣的可以深入了解NP难问题以及算法的设计过程)
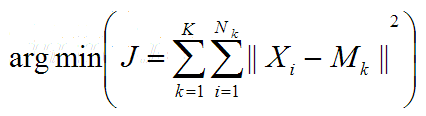
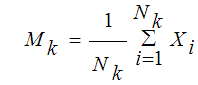

2.2 k均值聚类算法原理
算法描述
step1、为中心向量c1, c2, …, ck初始化k个种子 (初始化聚类中心)
step2、划分样本:
(1)将样本分配给距离其最近的中心向量
(2)由这些样本构造不相交( non-overlapping )的聚类
step3:更新中心向量:
用属于各个簇的所有样本均值作为新的中心向量。
step4:转step2,直至算法收敛(满足停止条件)。算法步骤精确描述
算 法 k-means算法
输入:簇的数目k和包含n个对象的数据库。
输出:k个簇,使平方误差准则最小。
算法步骤:
1.为每个聚类确定一个初始聚类中心,这样就有K 个初始聚类中心。
2.将样本集中的样本按照最小距离原则分配到最邻近聚类
3.使用每个聚类中的样本均值作为新的聚类中心。
4.重复步骤2.3直到聚类中心不再变化。
5.结束,得到K个聚类簇。
再附上一张周志华老师的《机器学习》这本书上的算法图:
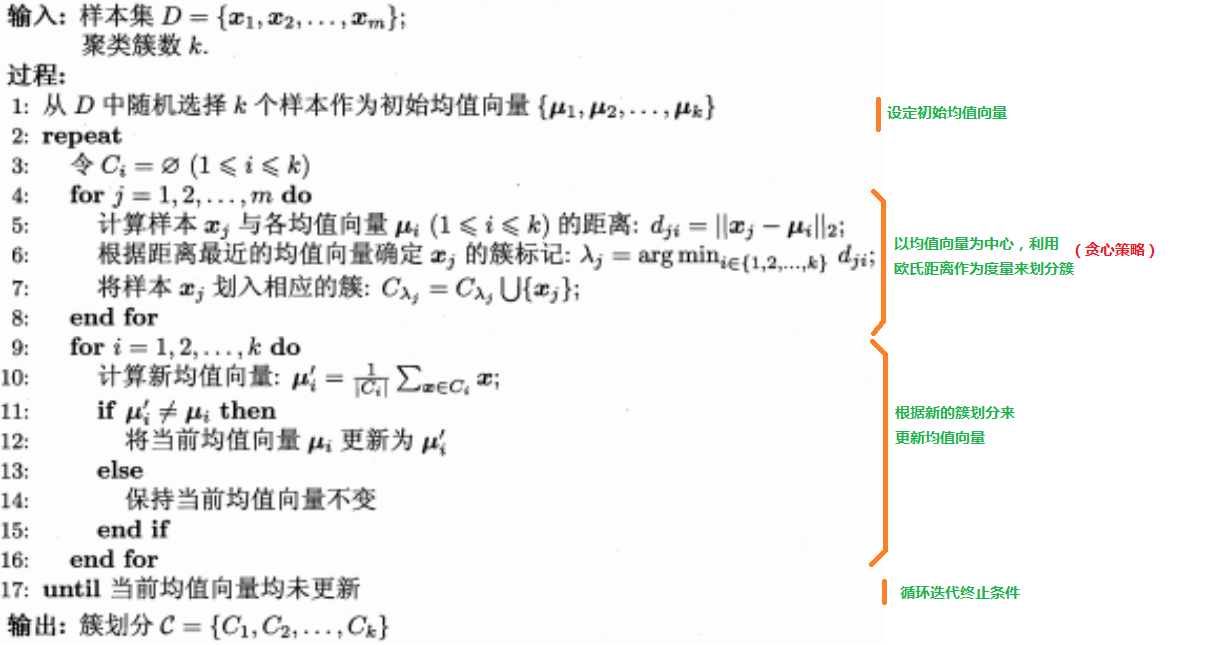
很重要:有没有发现,聚类的过程实际上就是不断更新中心向量(所谓的原型)的过程,可以这么说,在距离度量方式确定情况下,你给我一组均值向量,我必然能给你一个划分(实际上这二者是一一对应的)
3 对算法的思考
3.1 总结
K均值聚类:
将样本划分为K个不同的簇,且每个簇的中心(均值向量)采用簇中所含样本的均值计算而成。算法本质:
随机选取一组样本初始化原型,采用贪心策略,通过迭代优化来更新原型,(原型 ==簇划分)初始均值向量(质心)的选取
选取不同的质心,往往会得到不同的结果。
建议:尽量不要处于样本的边界,即质心每一维度上的值要落在原始数据集每一维度的最小与最大值之间。迭代终止条件:
所有的均值向量(实值向量)均未更新—->设置一个最大循环次数或最小调整幅度阈值。K值的选取
k值表示要划分簇的数目作为输入参数,由用户指定,
建议:(1)通过启发式算法用于自动确定k值
(2)基于不同K值多次运行之后选取最佳结果(常用)
3.2 一点思考
“相似度”度量方式:
(1)度量距离:满足:非负性,对称性,同一性,三角不等式性的函数。
如:欧氏距离、曼哈顿距离、切比雪夫距离
(2)非距离度量:不满足三角不等式性
—>对于具体的问题,应当基于数据样本来确定合适的的距离度量方式一个默认的假设:每个样本只属于一个簇
在实际生活中,样本之间不是孤立的,可能以不同程度属于不同类,这时候可以应用“软聚类”的概念,有兴趣的可以深入了解。
场景:朋友圈网络 —->软聚类算法:允许每个样本以不同程度属于多个
4实验结果
(待续)














 984
984











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









