






前言
整篇文章是对作者Russ Cox的文章Regular Expression Matching Can Be Simple And Fast的翻译,在我看来,该文章是入门正则引擎的较好的文章之一,读者在阅读之前,最好有一定的正则表达式的基础。翻译内容仅代表作者观点。侵删
该作者所有的文章的网址在此:https://swtch.com/~rsc/regexp/
正文
介绍
下图是两种不同的正则引擎的匹配时间图。一个是被广泛应用于许多语言的标准解释器中,其中包括Perl。而另外一个则只被用到了少数的几个地方,比较出名的是awk和grep。这两种匹配方式有着相当不同的性能表现。
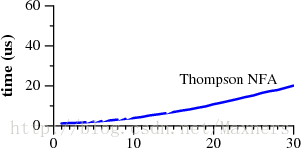
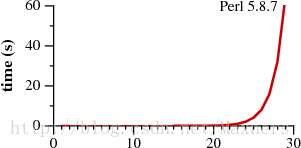
我们使用上标来表示字符串的重复,那么a?3a3便是a?a?a?aaa的缩写,而上边的两张图则表示了当我们使用a?nan去匹配字符串an时,两种不同的正则引擎所需的匹配时间。
需要注意的是Perl的正则引擎需要超过60秒的时间去匹配一个29字的字符串。而另外一种名叫Thompson NFA的引擎则只需要20微秒就可以完成匹配。而这并不是印刷的错误。注意到两张图的纵坐标,Perl的纵坐标单位以秒计,而Thompson NFA的纵坐标以微秒计:当我们在匹配一个29字符的字符串时,Thompson NFA的实现方式比Perl的实现方式快了百万倍。而两张图的曲线趋势也告诉我们,Thompson NFA可以在200微秒以内去匹配一个100字符的字符串,而Perl则需要超过1015年。(在这里,Perl只是众多使用同样正则匹配算法的语言中的具有代表性的一个,上图中的时间效率同样可以发生在Python,PHP,Ruby,或者其他的语言中。在后文中我们会给出其他实现方式的具体数据。)
要做到完全相信这两张图可能有点困难,也许有的读者曾用过Perl,它的正则匹配也从来没有图中显示的这样慢过。实际上在大多数的时间里,Perl的正则引擎是足够快的。但正如图中显示的那样,有一定的可能性我们会写出Perl匹配起来非常非常慢的“病态”的正则表达式。然而,对于Thompson NFA这种实现来说,并没有所谓的“病态”的正则表达式。看到上边的两张图我们不禁会问“为什么Perl没有使用Thompson NFA这种实现方式?”Perl本来可以,也应该。而接下来的文章则会向你揭示Thompson NFA的秘密。
从历史的角度看,在计算机科学众多闪耀的典范中,正则表达式是其中一个展示了怎样将好的理论运用到程序中,并创造出好的程序的例子。它们最初是由理论学家所建立起来的一个简单的计算模型,但是Ken Thompson则把它们引入到了自己在CTSS上的文本编辑器QED中。Dennis Ritchie使用同样的理论在GE-TSS中实现了自己的QED。Thompson和Ritchie随后便创造出了Unix,同时也将正则表达式保留了下来。在二十世纪七十年代晚期,正则表达式成为了Unix环境中的一个重要的特性,在许多工具例如ed,sed,grep,egrep,awk,和lex中都有它的身影。
而今天,正则表达式也同样向我们展示了忽略一个好的理论是怎样导致人们的程序变得十分糟糕的。如今的许多流行的工具中使用的正则匹配的实现方法比三十年前的Unix中的工具中的方法还要来得更加缓慢。
这篇文章回顾了由Ken Thompson在二十世纪六十年代中期提出的一系列理论:正则表达式,有限自动机,正则表达式搜索算法。同时该文章也将这些理论运用到实践当中,描述了Thompson算法的一个简单实现。而这个不到四百行C代码的完整实现,却将Perl远远地甩在了后边。这一实现Perl,Python,PCRE以及其他语言使用的实现方法要来得更好。而文章的最后我们会来探讨一些已经被实际运用的好的理论。














 1292
1292











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









