







FMS2015是一个充满技术干货的平台,各领域技术大拿在峰会上分享的技术和产品都影响甚至主导着闪存下一阶段的发展。此次Memblaze的工程师团队也是从存储系统、PCIe SSD以及闪存控制器三个层次做了技术演讲,并在现场引发了一波讨论热潮。
Memblaze架构师吴忠杰发表了主题为《Methods to achieve low latency and consistent performance》,他从存储系统的角度阐述了Memblaze为解决闪存系统性能瓶颈而研发的MemOS以及RISL软件架构。

图1:Memblaze架构师吴忠杰
首先他从低延迟和持续的高性能阐述了存储系统设计过程中的挑战。

图2:架构设计中的挑战
图2可以看出,他认为要做低延迟需要从三个方面进行考虑。首先是写操作的低延迟;然后是读写操作的相互影响;最后是系统带宽和延迟之间需要取得一个平衡。而持续的高性能方面,则需要从OS、控制器架构以及高IOPS性能的同时保障低延迟。
接下来他从Linux系统的读写路径分析了系统瓶颈所在。(如图3和图4)
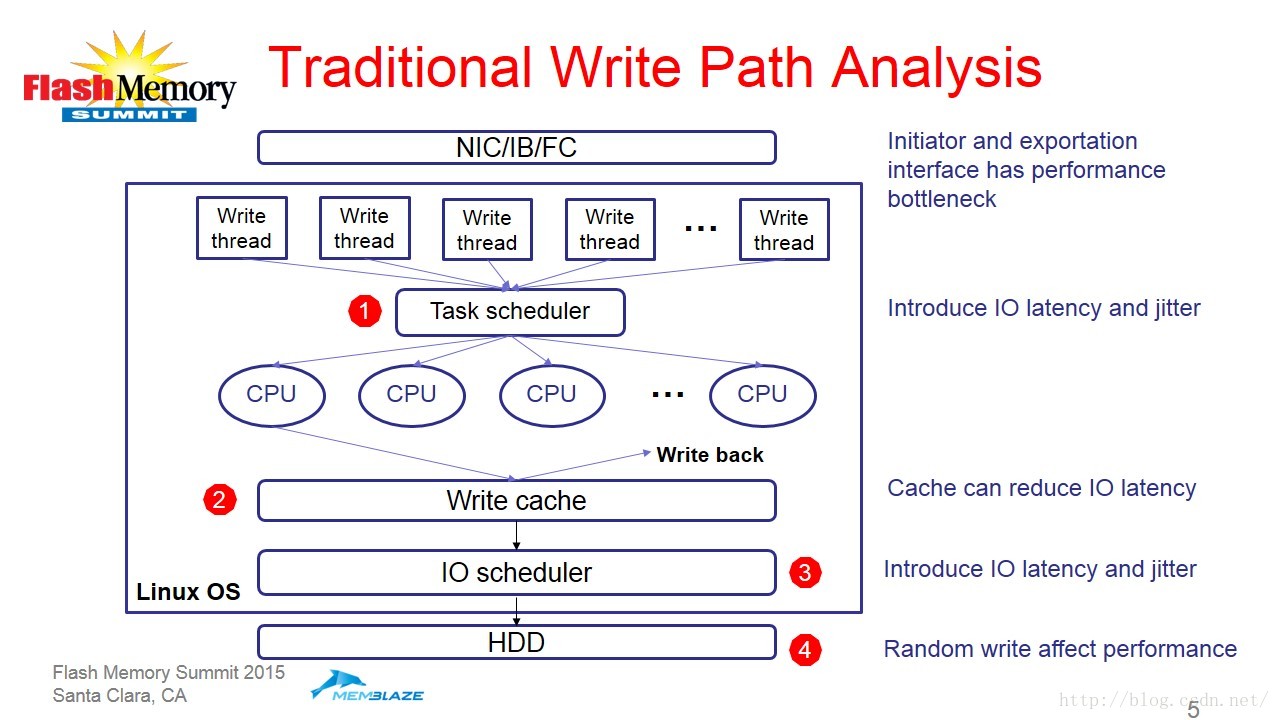
图3
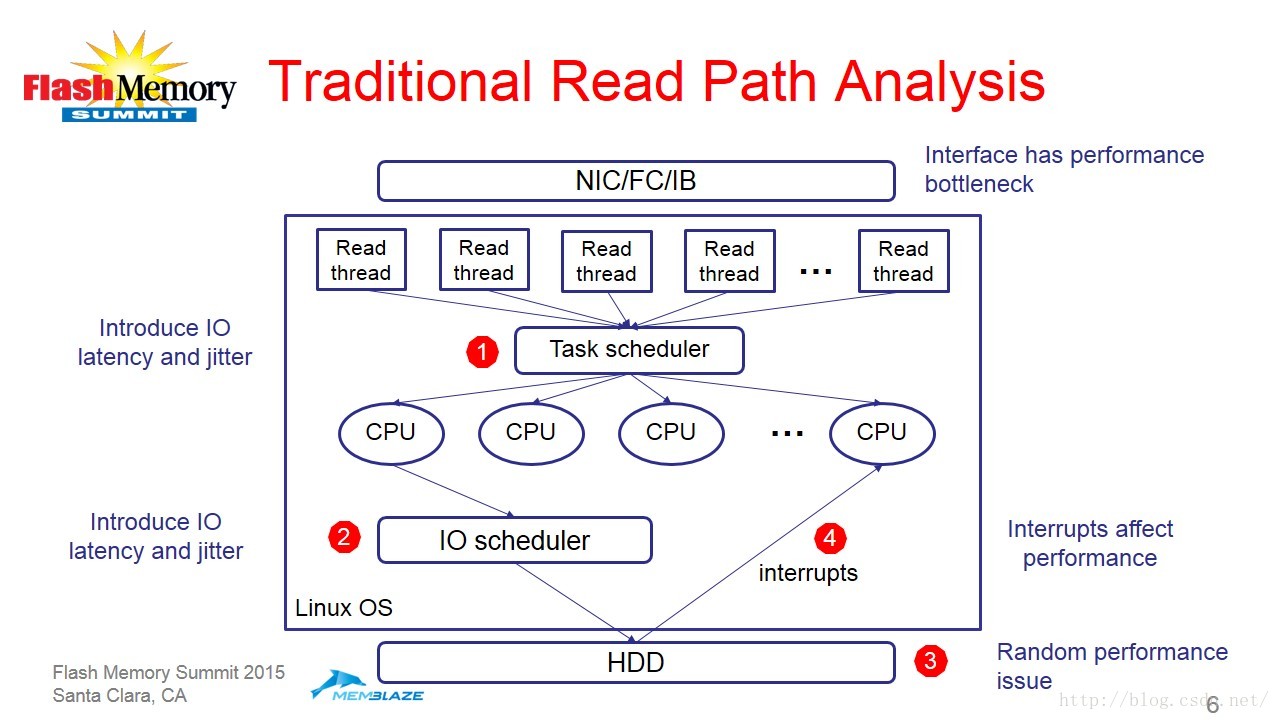
对于SSD来讲,其有三个比较明显的特点,首先是随机写会产生大量的mapping信息并且需要经常进行垃圾回收;第二是极高的随机读性能;最后是写/擦除操作会影响度性能。Memblaze研发了RISL(Random Input Stream Layout)软件架构。RISL的特点包括下面四个方面:
- 非易失性写缓存(BlazeArray使用NVDIMM做缓存)。将任意的写操作转换为顺序写;
- 将读写操作分离到不同的容器(storage object)中进行;
- 基于Pipeline和run-to-complete两种IO模式处理写操作;
- 基于run-to-completeIO模式处理读操作。
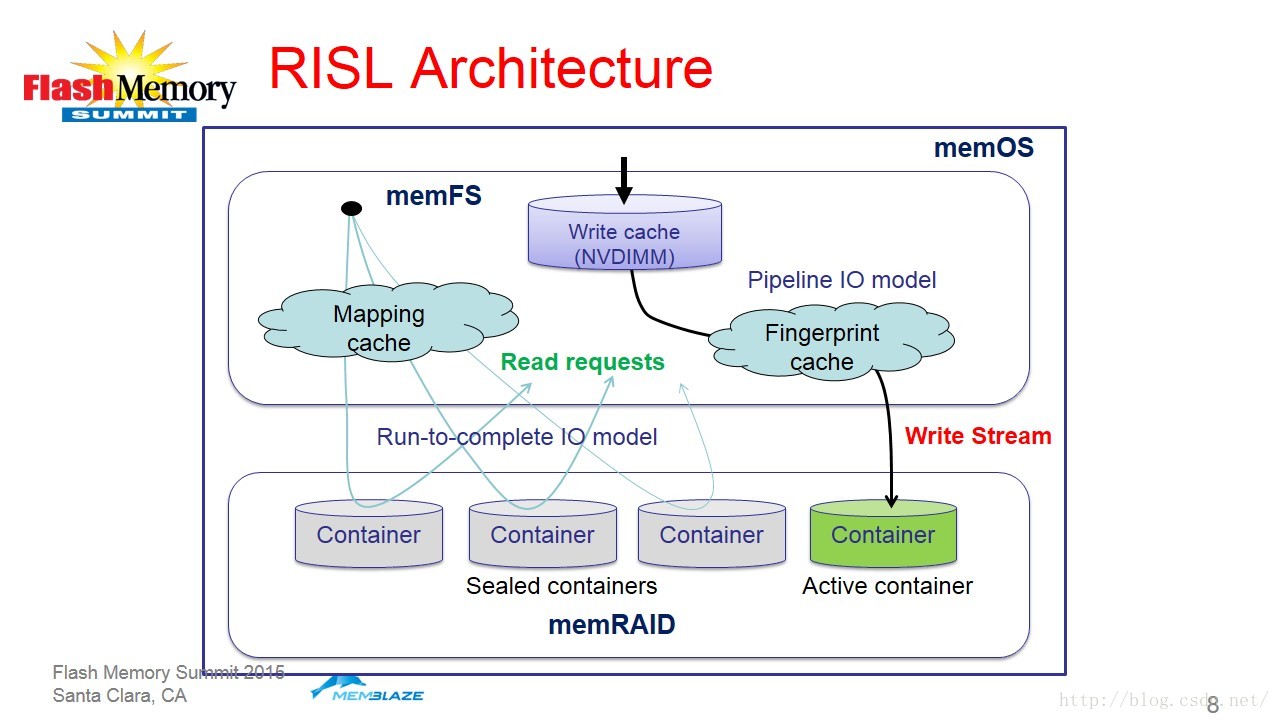
这里需要解释一下RISL中的IO处理模型。如图6:

具体到读写两个操作的具体实现,展示如下图:
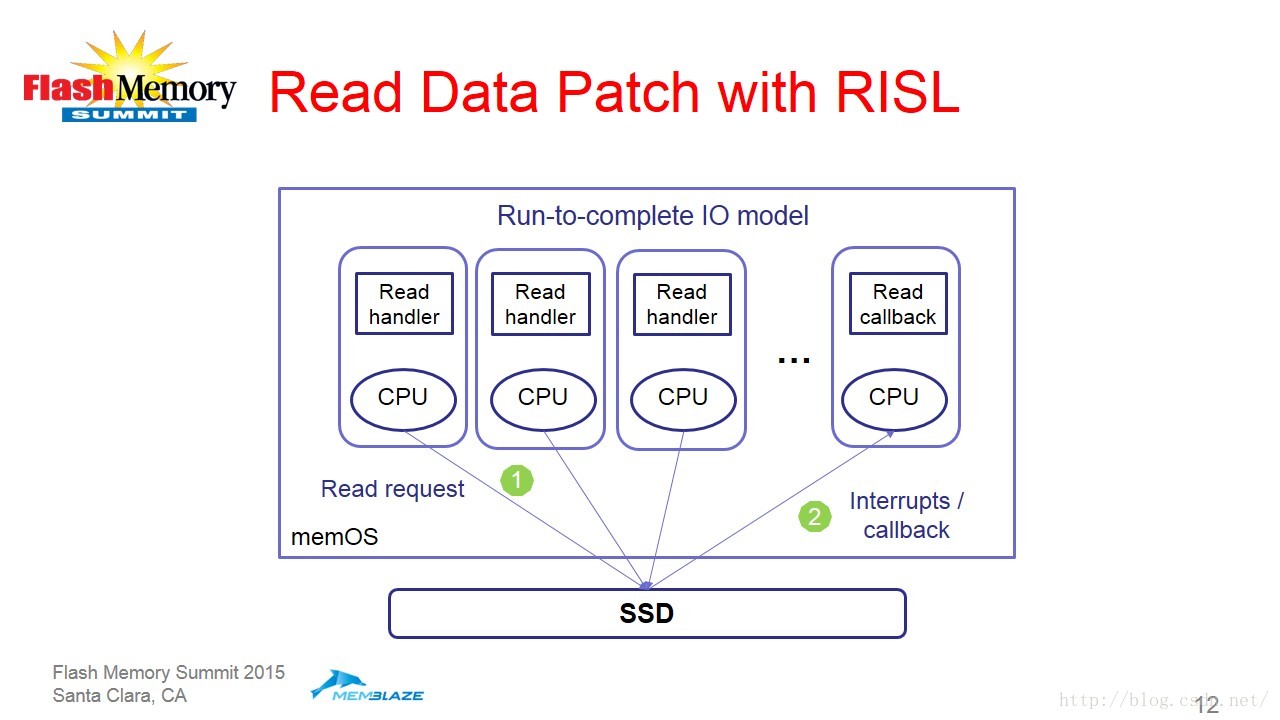
上图可以看到读操作比较,直接通过Run-to-complete IO模式就能完成。
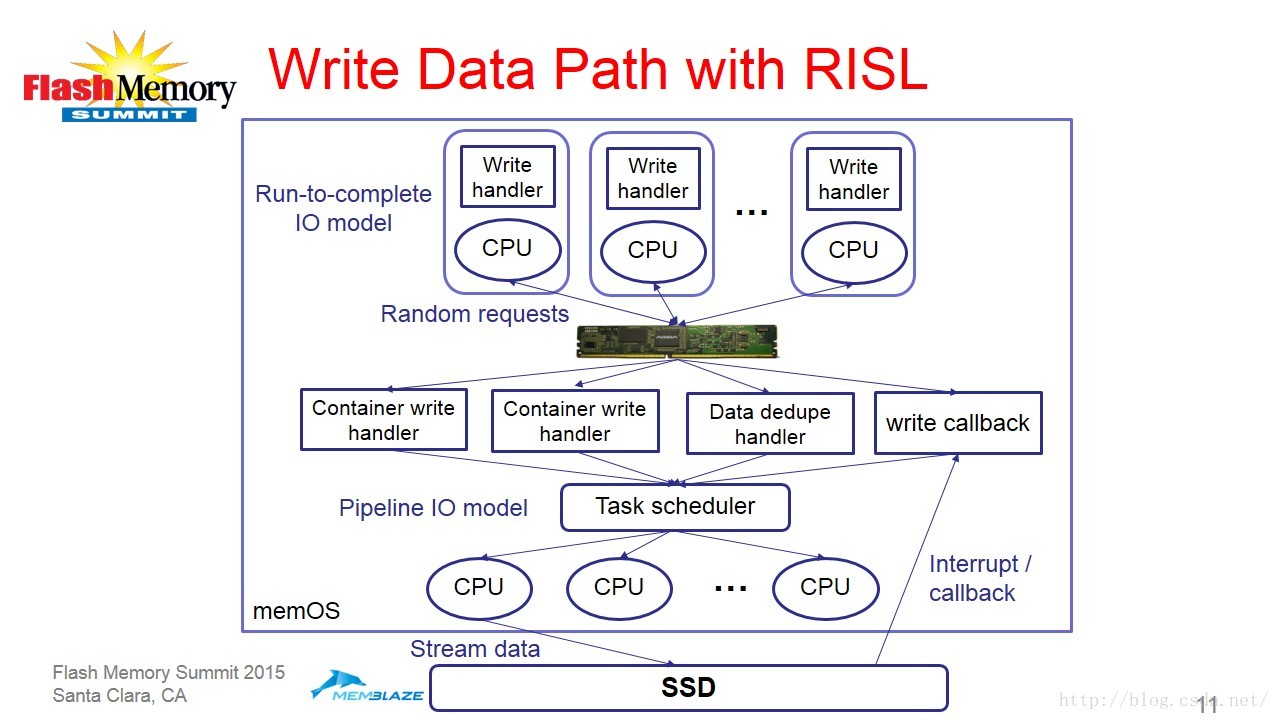
以上是对RISL软件架构一个基本的解读。需要补充说明的是,为了降低存储系统的写延迟,Memblaze使用了NVDIMM充当读写缓存,特别是在写操作中,NVDIMM对于提高系统性能起到了非常关键的作用。关于NVDIMM的优势以及使用后的优势,图9做了一个总结。

图9:NVDIMM做Blaze Array的非易失性缓存
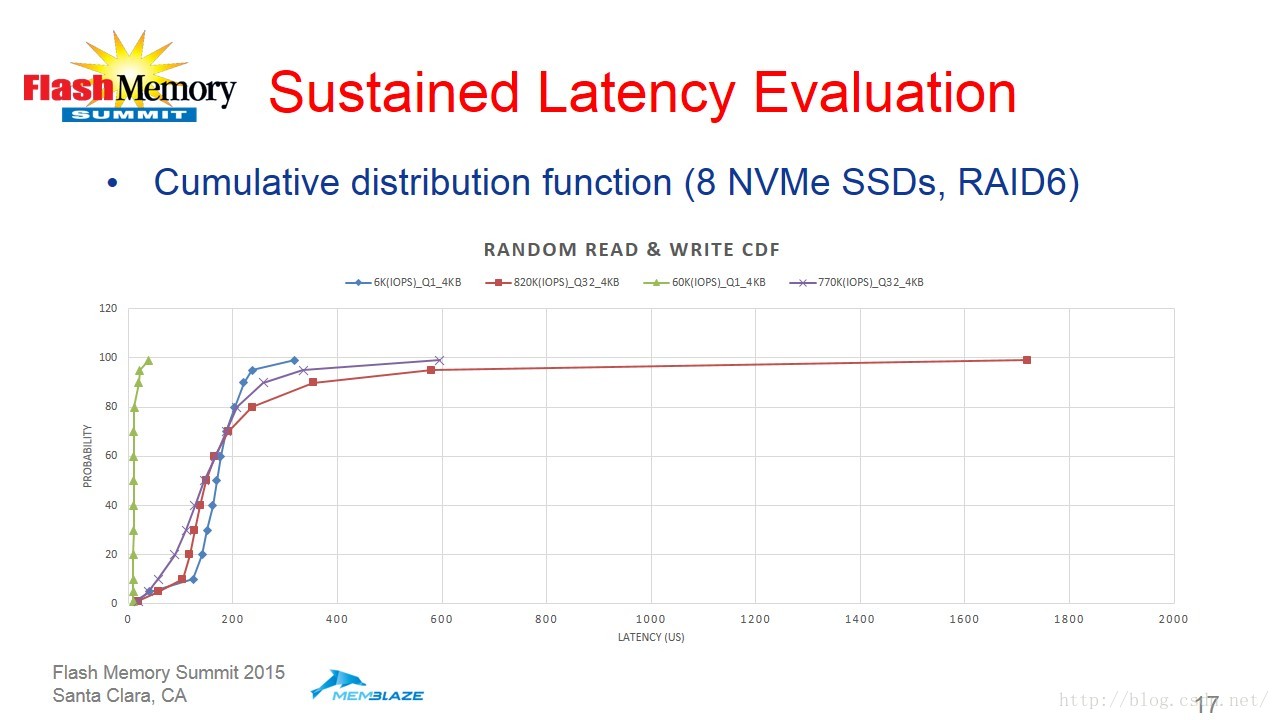
最后吴忠杰介绍了RISL架构的性能效果。实际的测试结果展示如下:
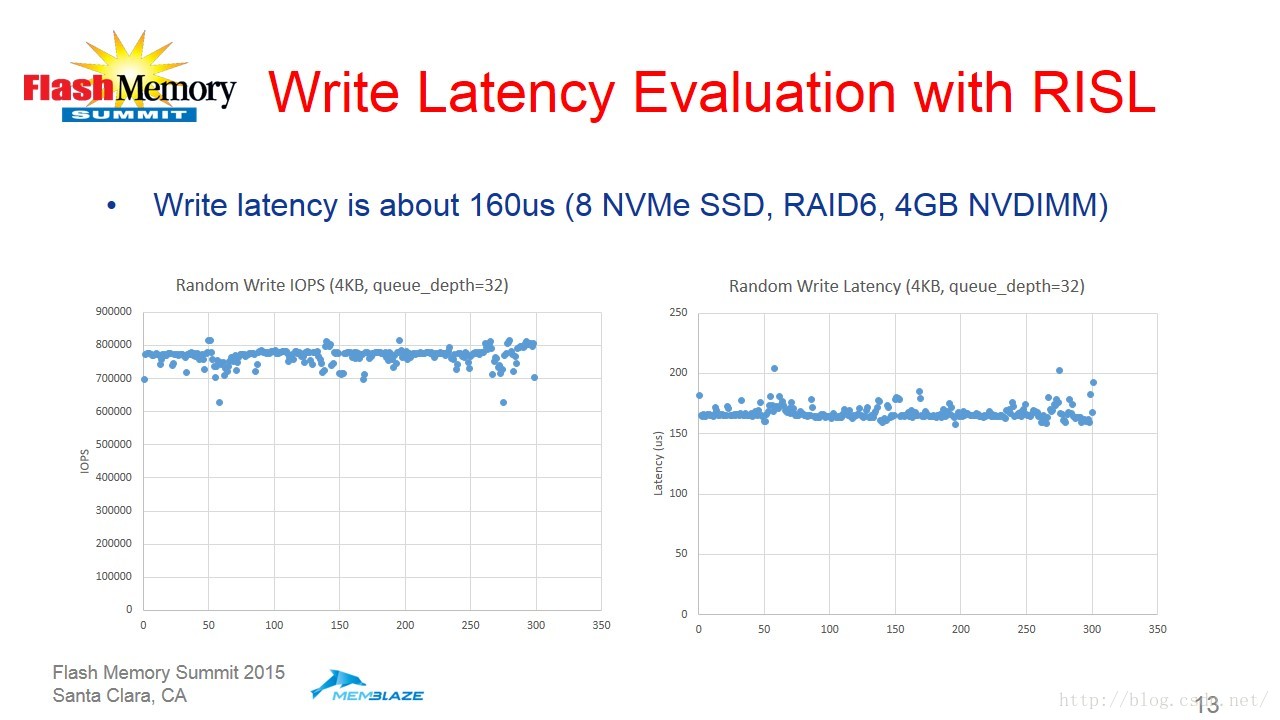
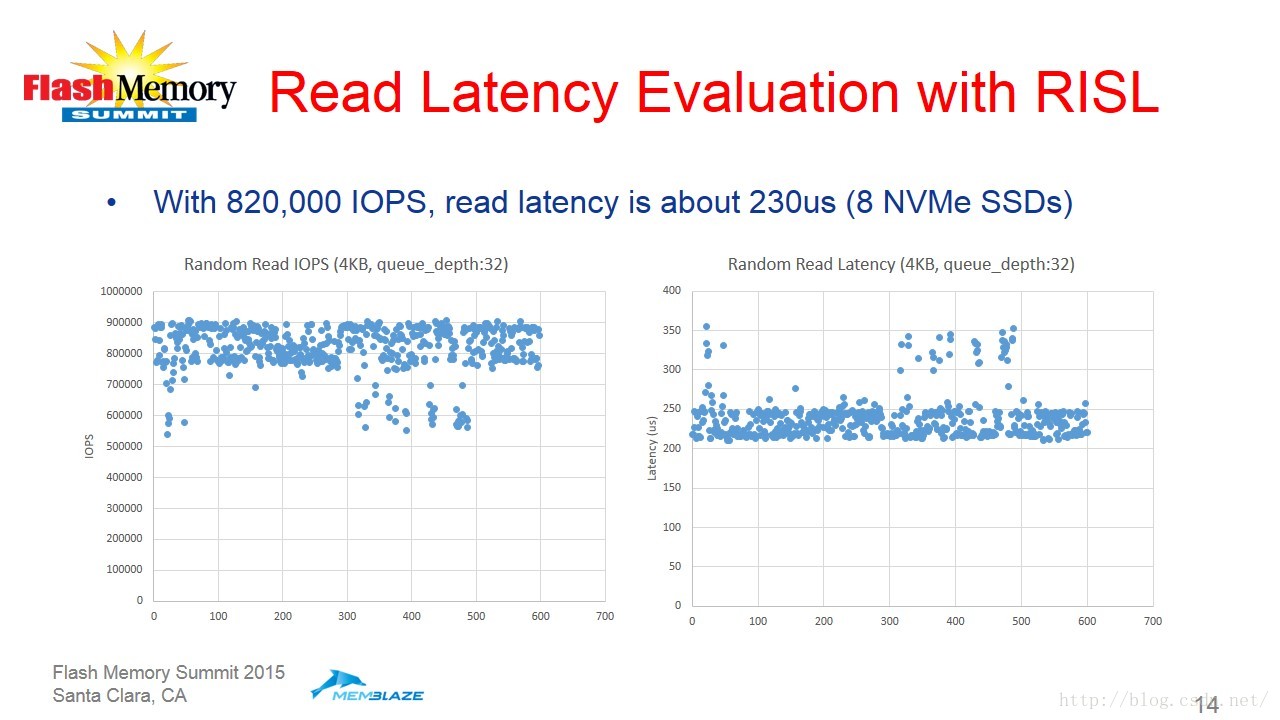
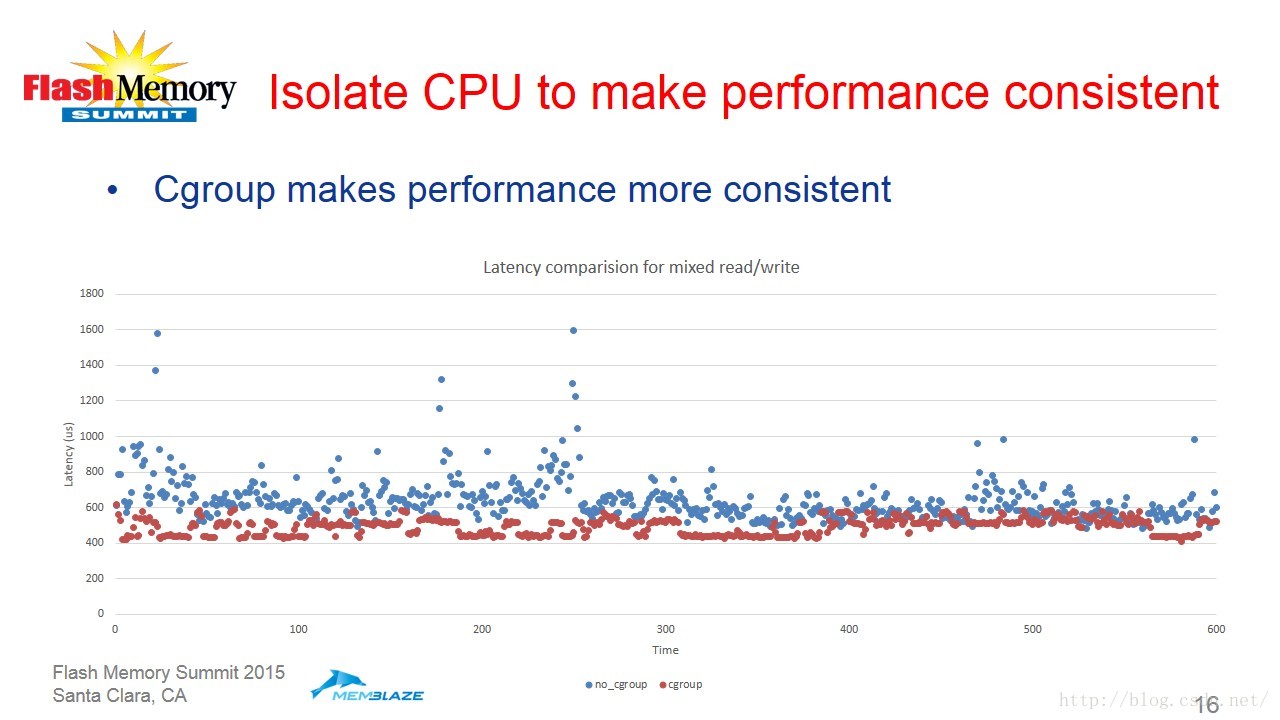














 1356
1356











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









