







- HiveQL 查询 _1 (翻译于 《Programing Hive》):http://flyingdutchman.iteye.com/blog/1869472
- HiveQL 查询 _2 (翻译于 《Programing Hive》):http://flyingdutchman.iteye.com/blog/1869621
- HiveQL 查询 _3 (翻译于 《Programing Hive》):http://flyingdutchman.iteye.com/blog/1869687
关于 Hive 的基本查询这边我也就不再多说了,大家可以参考上面提供的链接。这里主要跟大家讨论一下 Hive 的查询优化。
Hive 提供了简单的语法以及可伸缩性让我们能够方便的进行数据处理,以至于我们忽略了在 Hive 中的优化操作。通过对表的精确设计和查询能够大大提高查询效率以及降数据低处理的成本。在这里将跟大家讨论一下在做 ETL 的时候,我们可以通过哪些途径来优化 Hive 的查询。
我们可以通过以下三种方式进行优化:
- 数据格式 -- 分区表 & 桶表
- 数据抽样 -- 桶表抽样 & 块抽样
- 数据处理 -- 桶表的 Map Join 和 并行处理
首先介绍一下我们的测试数据:我们有三张表的数据,第一张 机票预订 表含有2.76亿条完整记录从出发地到目的地的航空旅行线路信息,其中行程标识作为主键;第二张 机票语句来源 包含了旅行中的第一站信息;最后一张表是美国人口每个州的普查信息。
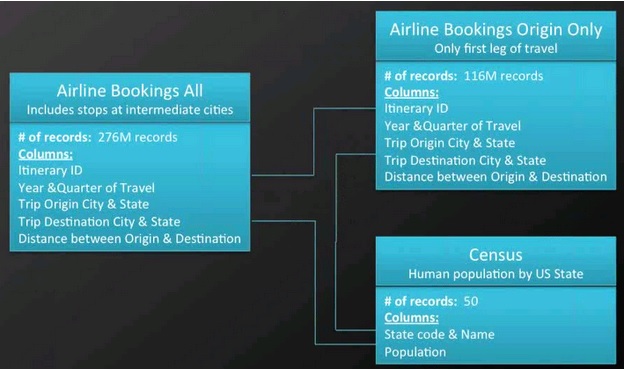
接下来让我们看看如何利用这些示例数据进行优化 Hive 查询。
1. Hive 分区表
默认情况下,Hive 的查询(select) 和 过滤(过滤) 会遍历整张表。当遇到大表是,查询性能会变得非常缓慢。
在 Hive 中,每个分区表都关联一个预分区的列来存储这张表在 HDFS 路径下的子目录。当查询分区表的时候,只会查询所需要的分区路径下的数据,这样使得 I/O 和 查询时间变得更加高效。 需要注意的是,分区不会自动 enabled。 我们需要使用 ALTER TABLE ADD PARTITION 语句为一张表添加分区。 ADD PARTITION 会更改表的元数据,但是不会加载数据。如果分区位置不存在数据,查询就不会返回任何结果。如果你希望擅长分区表的数据和元数据,可以使用:ALTER TABLE DROP PARTITION 语句。具体详解可以参考:Hive_3.DDL -- 分区表 & 桶表 & 视图:http://blog.csdn.net/mike_h/article/details/50121135

并不是说分区越多就越好,我们也需要考虑可能分区列的基数,避免出现太多的数据碎片。对行程 ID 分区显然是一个非常笨拙的方案,因为会导致 HDFS 下生产大量的小文件,因为就算每个文件中只有几个字节的数据量,HDFS通常也会使用一个大于等于64MB的块(文件)来进行存储。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









