







SVM算法的效果是非常好的。对于一个线性可分的数据集(假设是二分类),以前的感知器算法就是找一条线将其分开就可以了,线的最终方程是随机的,它与分割线的初始化情况,与遇到训练点的顺序有关,因为它是遇到一个训练点,如果错误才改正。而现在的支持向量机算法就是能够在如此多的看似成功的线中找出一条最好的线,结果是唯一的。
那这个线是什么线呢?
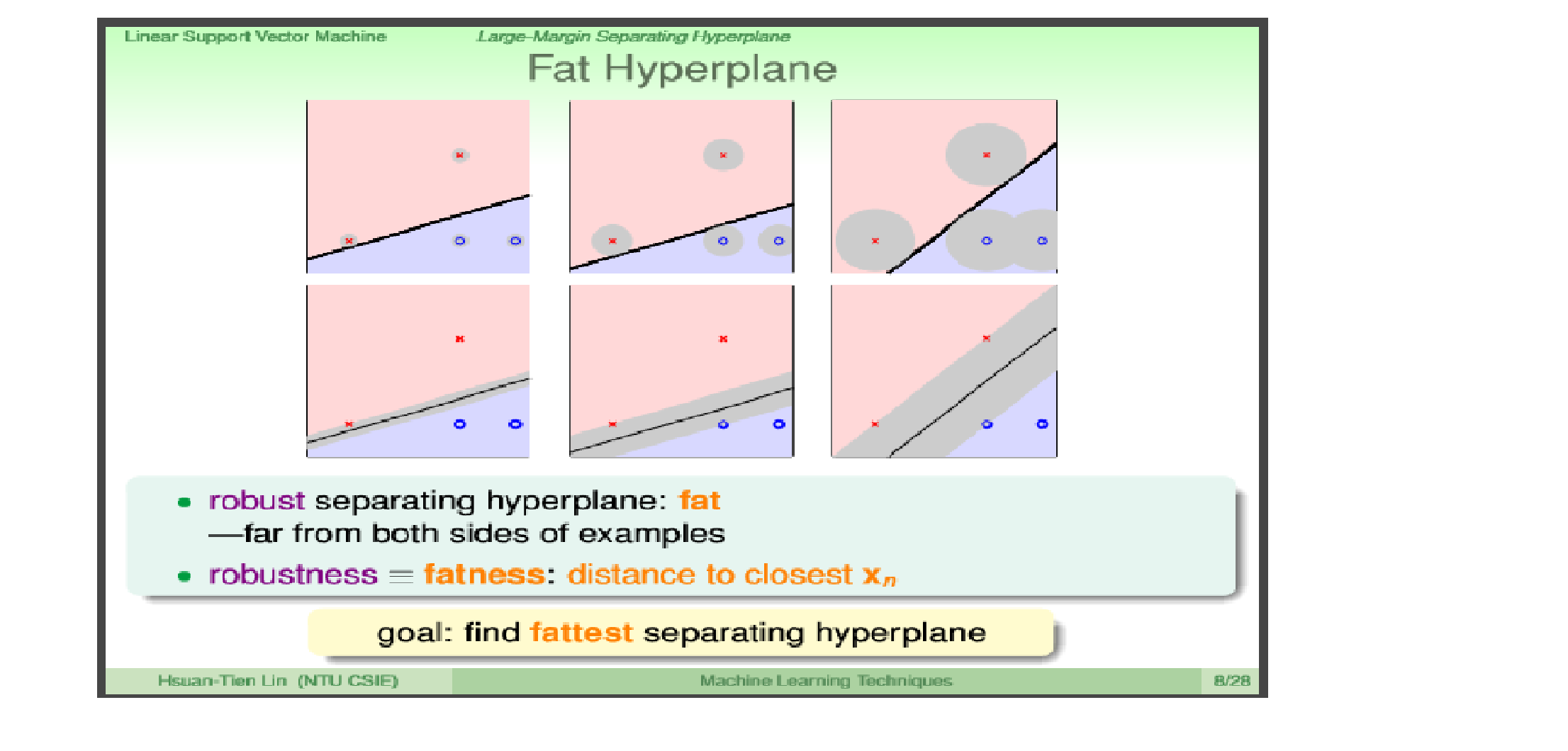
定义距离分隔线的最近的点称为支持向量,距离支持向量距离最大的线就是我们的分割线。如上图所示,就是第三条。
为什么这条线最好呢?
很简单,所有的模型都是用来预测未知数据的。如果有一个未知数据点,它与支持向量非常相近,仅仅因为测量误差等原因有一点点波动。如果这个支持向量是‘x’,那么我们肯定这个未知数据的标签也为‘x’.但是如果放在第一个图中,支持向量几乎就在分隔线上面,未知数据有一点点波动,就会由’x’,变成‘o’。而第三个图的分割线,就会好很多,即他的泛化性能远比第一个图好。所以,支持向量到分割线的距离越大,模型的泛化性能越好,我们越有自信确定未知数据点的标签。
定义:
1.
函数距离
函数边界:就是最小的函数距离
几何距离
几何边界:就是最小的函数距离
其中 γ = γˆ||w||
推导几何距离公式:
令点A的坐标为 xi ,分割线的单位法向量为 w||w|| ,点A到该分割线的距离为 γi ,做点A到分割线的垂线,交点为B ,坐标为 c ,则
- 我们最终目的是让函数边界大,还是让几何边界大呢?
其实,真正目的应该是让函数边界大,但是最终还是转化为让几何边界大。对于函数距离 γiˆ=yi(wTx+b) ,我们最终希望的是,当 yi =1时, (wTx+b) >>0,当 yi =-1时, (wTx+b) <<0。即最终是要函数距离 γiˆ=yi(wTx+b) >>0。但是,如果我们要想达到这个目的,让w和b都成倍的增加就可了,但这样显然是错误的,所以我们必须要对w和b进行正规化。即将w,b变成 w||w|| , b||w|| ,再代入函数距离上,就变成了几何距离。所以最大化几何距离是没有错的。
现在我们开始求最优边界!
目标:最大化几何边界
γ
条件:
γ
应为支持向量,即其他所有的几何距离都大于几何间距。
则
目标:
maxγ,w,b
γ
条件1:
γˆ
=1 既然是约束条件,那么||w||=1,和
γˆ
=1都可以。(我认为是这样的,如果不是,还请告知)
条件2:
γi=yi((w||w||)Tx+b||w||)
>=
γ
化简条件
yi((w||w||)Tx+b||w||)
>=
γˆ||w||
去掉||w||,即得
yi(wTx+b)
>=
γˆ
则可化简为
目标:
maxγ,w,b
γˆ||w||
条件1:
yi(wTx+b)
>=
γˆ
条件2:
γˆ
=1
条件2
γˆ
=1的作用?
正规化,作用同||w||,其值为1,或2,什么的都可以。
则最终优化问题为:
目标:
12
minγ,w,b
||w||2
条件1:
yi(wTxi+b)
>=1
正是一个二次规划问题,可用商业软件求出答案。比如LINGO软件。














 721
721











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









