










Python 2.7
IDE Pycharm 5.0.3
具体Selenium和PhantomJS配置及使用请看调用PhantomJS.exe自动续借图书馆书籍
我一直以为,PhantomJS就是无界面的浏览器而已,用Selenium调用PhantomJS和调用Firefox并没有区别
起因
今天想写个爬豆瓣高分电影及评论的小爬虫,刚开始一直调用浏览器进行模拟登陆测试,之后换成调用PhantomJS之后,竟然奇迹般的不好使了!换回浏览器,又正常了!WTF,说好的只是无界面浏览器呢!怎么和导演说的不一样啊!
引用
这是两段网上和书上都有的话,应该没有什么问题
PhantomJS是一个服务器端的 JavaScript API 的WebKit(开源的浏览器引擎)。其支持各种Web标准: DOM 处理, CSS 选择器, JSON, Canvas 和 SVG。PhantomJS可以用于页面自动化,网络监测,网页截屏,以及无界面测试等。
因为脚本好像是一个Web浏览器上运行的一样,标准的DOM脚本和CSS选择器可以很好的工作。这使得PhantomJS适合支持各种页面自动化任务。
Selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7、8、9)、Mozilla Firefox、Mozilla Suite等。这个工具的主要功能包括:测试与浏览器的兼容性、测试系统功能,它ThoughtWorks专门为Web应用程序编写的一个验收测试工具。
参考这种资料来看,个人认为,PhantomJS完全可以模拟正常浏览器,简单说就是个无界面轻量级浏览器,不知我理解的可对。
实例分析
目的
根据用户输入,列出豆瓣高分TOP(用户自定义)的电影,链接,及热评若干。(后面几篇博文会更加完善这一想法,这里只是针对豆瓣高分电影)
方案
使用PhantomJS+Selenium+Firefox实现
实现过程
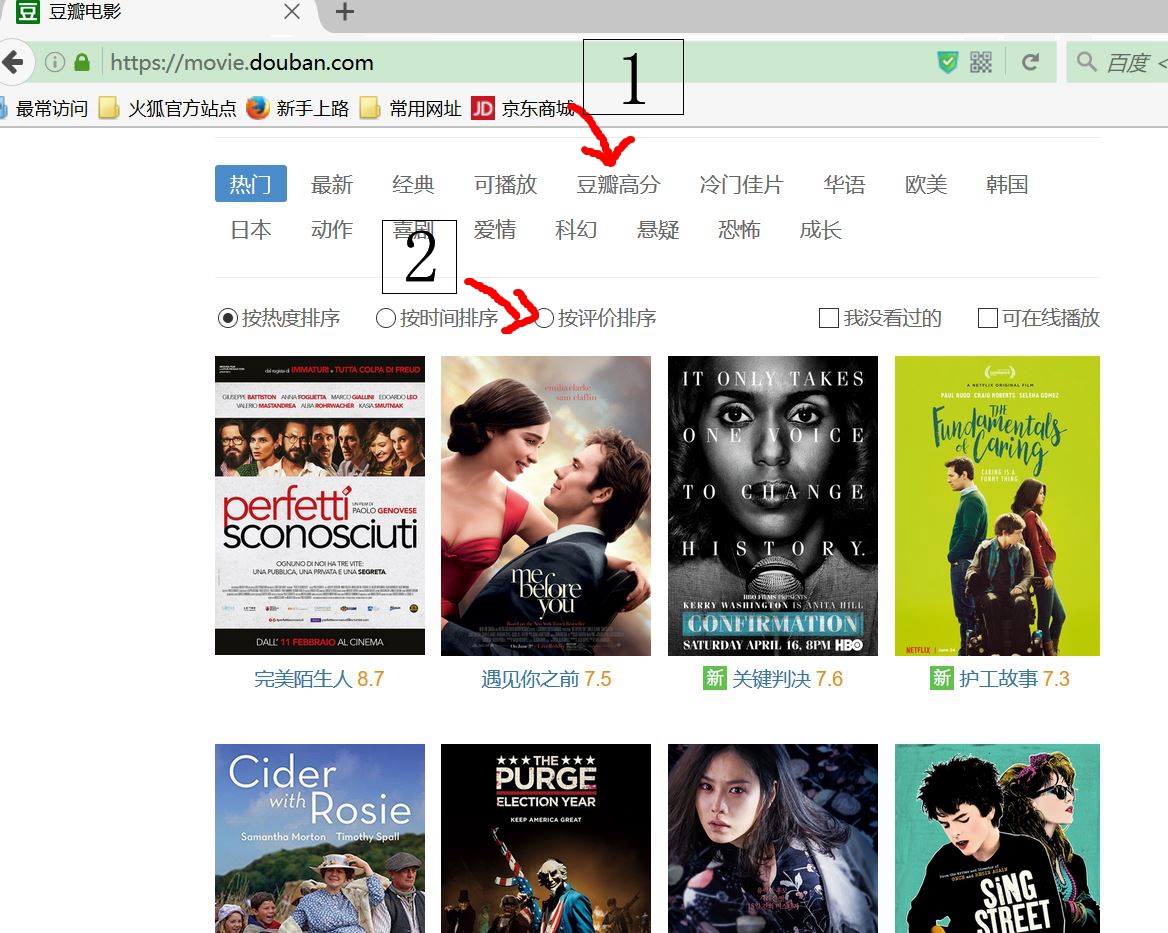
1.get到首页后,先点击豆瓣高分,然后点击按照评分,进行排序
2.抓取每个电影及超链接,进入超链接后,抓取当前电影的热评
3.当用户所要求TOP数目大于第一页的20个时候,点击加载更多,再出现20个电影,重复2操作。
点击过程
实现代码
# -*- coding: utf-8 -*-
#Author:哈士奇说喵
#爬豆瓣高分电影及hot影评
from selenium import webdriver
import selenium.webdriver.support.ui as ui
import time
SUMRESOURCES = 0 #全局变量,计数
driver_detail = webdriver.PhantomJS(executable_path="phantomjs.exe")
#driver_item=webdriver.PhantomJS(executable_path="phantomjs.exe")
driver_item=webdriver.Firefox()
url="https://movie.douban.com/"
wait = ui.WebDriverWait(driver_item,15)
wait1 = ui.WebDriverWait(driver_detail,15)
#获取URL和文章标题'''
def getURL_Title(num):
global SUMRESOURCES
#先对豆瓣高分进行点击,然后再选择按照评价排序,不然元素隐藏,看不见的
driver_item.get(url)
wait.until(lambda driver: driver.find_element_by_xpath("//div[@class='fliter-wp']/div/form/div/div/label[5]"))
driver_item.find_element_by_xpath("//div[@class='fliter-wp']/div/form/div/div/label[5]").click()
wait.until(lambda driver: driver.find_element_by_xpath("//div[@class='fliter-wp']/div/form/div[3]/div/label[3]"))
driver_item.find_element_by_xpath("//div[@class='fliter-wp']/div/form/div[3]/div/label[3]").click()
time.sleep(2)
#打开几次“加载更多”
num_time = num/20+1
wait.until(lambda driver: driver.find_element_by_xpath("//div[@class='list-wp']/a[@class='more']"))
for times in range(1,num_time):
time.sleep(1)
driver_item.find_element_by_xpath("//div[@class='list-wp']/a[@class='more']").click()
wait.until(lambda driver: driver.find_element_by_xpath("//div[@class='list']/a[%d]"%num))
print '点击\'加载更多\'一次'
#driver_item.find_element_by_xpath("//div[@class='list']/a[35]").click()
#使用wait.until使元素全部加载好能定位之后再操作,相当于try/except再套个while把
#wait.until(lambda driver: driver.find_element_by_xpath("//div[@class='list']/a"))
#time.sleep(2)
for i in range(1,num):
wait.until(lambda driver: driver.find_element_by_xpath("//div[@class='list']/a[%d]"%num))
list_title=driver_item.find_element_by_xpath("//div[@class='list']/a[%d]"%i)
print 'No' + str(SUMRESOURCES +1)
print u'电影名: ' + list_title.text
print u'链接: ' + list_title.get_attribute('href')
SUMRESOURCES = SUMRESOURCES +1
try:#获取具体内容和评论。href是每个超链接也就是资源单独的url
getDetails(str(list_title.get_attribute('href')))
except:
print 'can not get the details!'
def getDetails(url):
driver_detail.get(url)
wait1.until(lambda driver: driver.find_element_by_xpath("//div[@id='link-report']/span"))
drama = driver_detail.find_element_by_xpath("//div[@id='link-report']/span")
print u"剧情简介:"+drama.text
for i in range(1,5):
try:
comments = driver_detail.find_element_by_xpath("//div[@id='hot-comments']/div[%s]/div/p"%i)
print u"最新热评:"+comments.text
except:
print 'can not caught comments!'
def main(num):
getURL_Title(num)
#看TOP前几的电影?
num = input("TOP ?:")
main(num+1)上述代码是我最后调试出来可行的,比如说我输入22,那么最后结果输出是:
TOP ?:22
点击'加载更多'一次
No1
电影名: 肖申克的救赎 9.6
链接: https://movie.douban.com/subject/1292052/?tag=%E8%B1%86%E7%93%A3%E9%AB%98%E5%88%86&from=gaia_video
剧情简介:20世纪40年代末,小有成就的青年银行家安迪(蒂姆·罗宾斯 Tim Robbins 饰)因涉嫌杀害妻子及她的情人而锒铛入狱。在这座名为肖申克的监狱内,希望似乎虚无缥缈,终身监禁的惩罚无疑注定了安迪接下来灰暗绝望的人生。未过多久,安迪尝试接近囚犯中颇有声望的瑞德(摩根·弗里曼 Morgan Freeman 饰),请求对方帮自己搞来小锤子。以此为契机,二人逐渐熟稔,安迪也仿佛在鱼龙混杂、罪恶横生、黑白混淆的牢狱中找到属于自己的求生之道。他利用自身的专业知识,帮助监狱管理层逃税、洗黑钱,同时凭借与瑞德的交往在犯人中间也渐渐受到礼遇。表面看来,他已如瑞德那样对那堵高墙从憎恨转变为处之泰然,但是对自由的渴望仍促使他朝着心中的希望和目标前进。而关于其罪行的真相,似乎更使这一切朝前推进了一步……
本片根据著名作家斯蒂芬·金(Stephen Edwin King)的... (展开全部)
最新热评:有种鸟是关不住的.
最新热评:这无疑是我看得最多的一部经典,爱死
最新热评:Hope is a good thing, and maybe the best thing of all.
最新热评:越狱我感觉就是改编自这个
(中间省略。。。)
No22
电影名: 龙猫 9.1
链接: https://movie.douban.com/subject/1291560/?tag=%E8%B1%86%E7%93%A3%E9%AB%98%E5%88%86&from=gaia
剧情简介:小月的母亲生病住院了,父亲带着她与四岁的妹妹小梅到乡间的居住。她们对那里的环境都感到十分新奇,也发现了很多有趣的事情。她们遇到了很多小精灵,她们来到属于她们的环境中,看到了她们世界中很多的奇怪事物,更与一只大大胖胖的龙猫成为了朋友。龙猫与小精灵们利用他们的神奇力量,为小月与妹妹带来了很多神奇的景观,令她们大开眼界。
妹妹小梅常常挂念生病中的母亲,嚷着要姐姐带着她去看母亲,但小月拒绝了。小梅竟然自己前往,不料途中迷路了,小月只好寻找她的龙猫及小精灵朋友们帮助。
最新热评:人人心中都有个龙猫,童年就永远不会消失,爱是最美的拥有~ ★★★★★
最新热评:日本的动画总是能触碰心灵和温情
最新热评:宫崎骏最感人的一部,初看平平无奇,回味一下痛彻肺腑。
最新热评:永远的豆豆龙
上面的代码是可以实现的,但需要Firefox的配合,因为我其中一个引擎调用了Firefox,另一个抓评论的用了PhantomJS。
出现问题
driver_item=webdriver.PhantomJS(executable_path="phantomjs.exe")当我driver_item使用PhantomJS而不是Firefox的时候,奇怪的事情出现了,21个电影,又重新回了第一个!
就像这样!
No1
电影名: 肖申克的救赎 9.6
链接: https://movie.douban.com/subject/1292052/?tag=%E8%B1%86%E7%93%A3%E9%AB%98%E5%88%86&from=gaia_video
剧情简介:20世纪40年代末,小有成就的青年银行家安迪(蒂姆·罗宾斯 Tim Robbins 饰)因涉嫌杀害妻子及她的情人而锒铛入狱。在这座名为肖申克的监狱内,希望似乎虚无缥缈,终身监禁的惩罚无疑注定了安迪接下来灰暗绝望的人生。未过多久,安迪尝试接近囚犯中颇有声望的瑞德(摩根·弗里曼 Morgan Freeman 饰),请求对方帮自己搞来小锤子。以此为契机,二人逐渐熟稔,安迪也仿佛在鱼龙混杂、罪恶横生、黑白混淆的牢狱中找到属于自己的求生之道。他利用自身的专业知识,帮助监狱管理层逃税、洗黑钱,同时凭借与瑞德的交往在犯人中间也渐渐受到礼遇。表面看来,他已如瑞德那样对那堵高墙从憎恨转变为处之泰然,但是对自由的渴望仍促使他朝着心中的希望和目标前进。而关于其罪行的真相,似乎更使这一切朝前推进了一步……
本片根据著名作家斯蒂芬·金(Stephen Edwin King)的... (展开全部)
最新热评:不需要女主角的好电影
最新热评:Hope is a good thing, and maybe the best thing of all.
最新热评:hope is a good thing
最新热评:有那么好吗?????No21
电影名: 肖申克的救赎 9.6
链接: https://movie.douban.com/subject/1292052/?tag=%E8%B1%86%E7%93%A3%E9%AB%98%E5%88%86&from=gaia_video
剧情简介:20世纪40年代末,小有成就的青年银行家安迪(蒂姆·罗宾斯 Tim Robbins 饰)因涉嫌杀害妻子及她的情人而锒铛入狱。在这座名为肖申克的监狱内,希望似乎虚无缥缈,终身监禁的惩罚无疑注定了安迪接下来灰暗绝望的人生。未过多久,安迪尝试接近囚犯中颇有声望的瑞德(摩根·弗里曼 Morgan Freeman 饰),请求对方帮自己搞来小锤子。以此为契机,二人逐渐熟稔,安迪也仿佛在鱼龙混杂、罪恶横生、黑白混淆的牢狱中找到属于自己的求生之道。他利用自身的专业知识,帮助监狱管理层逃税、洗黑钱,同时凭借与瑞德的交往在犯人中间也渐渐受到礼遇。表面看来,他已如瑞德那样对那堵高墙从憎恨转变为处之泰然,但是对自由的渴望仍促使他朝着心中的希望和目标前进。而关于其罪行的真相,似乎更使这一切朝前推进了一步……
本片根据著名作家斯蒂芬·金(Stephen Edwin King)的... (展开全部)
最新热评:不需要女主角的好电影
最新热评:策划了19年的私奔……
最新热评:越狱我感觉就是改编自这个
最新热评:看完让人很振奋可以看到,评论都是不一样的,说明抓取的是动态网页而且进行了二次抓取,我不明白为什么我代码没有改变,只是调用的引擎不一样,会产生两个不同的结果,难道是js渲染问题么?
首选我分析了一下我的“加载更多”是否合理
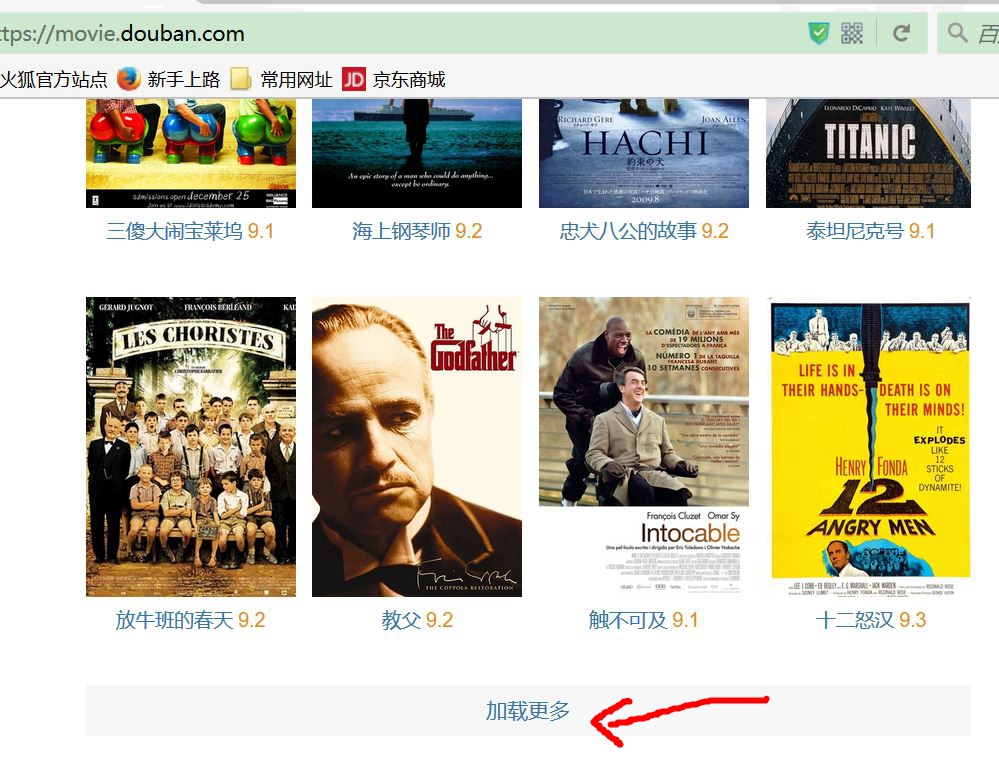
我采用的方法是,建立一个循环,当用户需求数大于页面存在元素数目就点击一下操作,然后再进行获取
经过观察,我写下如下一个循环,觉得应该算简便(其实是错误的,抱歉)
num_time = num/20+1
wait.until(lambda driver: driver.find_element_by_xpath("//div[@class='list-wp']/a[@class='more']"))
for times in range(1,num_time):
time.sleep(1)
driver_item.find_element_by_xpath("//div[@class='list-wp']/a[@class='more']").click()
wait.until(lambda driver: driver.find_element_by_xpath("//div[@class='list']/a[%d]"%num))
print '点击\'加载更多\'一次'也就是说,如果用户想看TOP22的,那第一页的20个电影已经不能满足了,需要点击加载更多,隐藏的元素才会被捉到,不然会出现无法定位元素的老问题。
↑补充↑,我犯了个严重的错误
上述那个循环是错误的!我测试到41时候才发现,点击一次之后,查询num=41元素是否存在是不合理的,肯定是不会存在的!,我当时只想着需要查询21的时候,点击一次“加载更多”之后,会出现40个元素,那么我要的21肯定在其中的,所以,我犯了想当然的错误,根本没有考录40以上情况,所以经过改进,应该是这样的,
#选择多打开一次进行加载
num_time = num/20+2
wait.until(lambda driver: driver.find_element_by_xpath("//div[@class='list-wp']/div/a[20]"))
for times in range(1,num_time):
driver_item.find_element_by_xpath("//div[@class='list-wp']/a[@class='more']").click()
wait.until(lambda driver: driver.find_element_by_xpath("//div[@class='list-wp']/div/a[%d]"%(20*(times+1))))
#点击一次,应该加载到40,点击两次,应该加载到60,同理我是分步分模块来测试的,这个完全没有问题的,只要设置一下休眠时间,等待缓冲完成,一点毛病没有。那问题真的出在调用引擎的问题上么?我来回测试过十多次,每次只要我换引擎了,那么一定出错,电影循环被抓,其中的奥秘我现在还不知道,如果有谁知道,请麻烦留言告诉我一声,我捉摸了半下午还没有头绪。。。
Pay Attention
暂且不说刚才的问题,解决方案找到了暂且能用还是好的,这里说一下我写这个爬虫遇到的问题
1.元素无法定位问题
1.解决方案,首先查看是不是隐藏元素,其次再看自己的规则有没有写错,还有就是是不是页面加载未完成,详见解决网页元素无法定位(NoSuchElementException: Unable to locate element)的几种方法
2.只采集自己需要的数据,剔除无用数据,比如说,刚开始我用
driver_detail.find_elements_by_xpath然后写个取出list中元素的方法,但是这样的话,一个便签下内容未必太多,并不是我想要的如图:
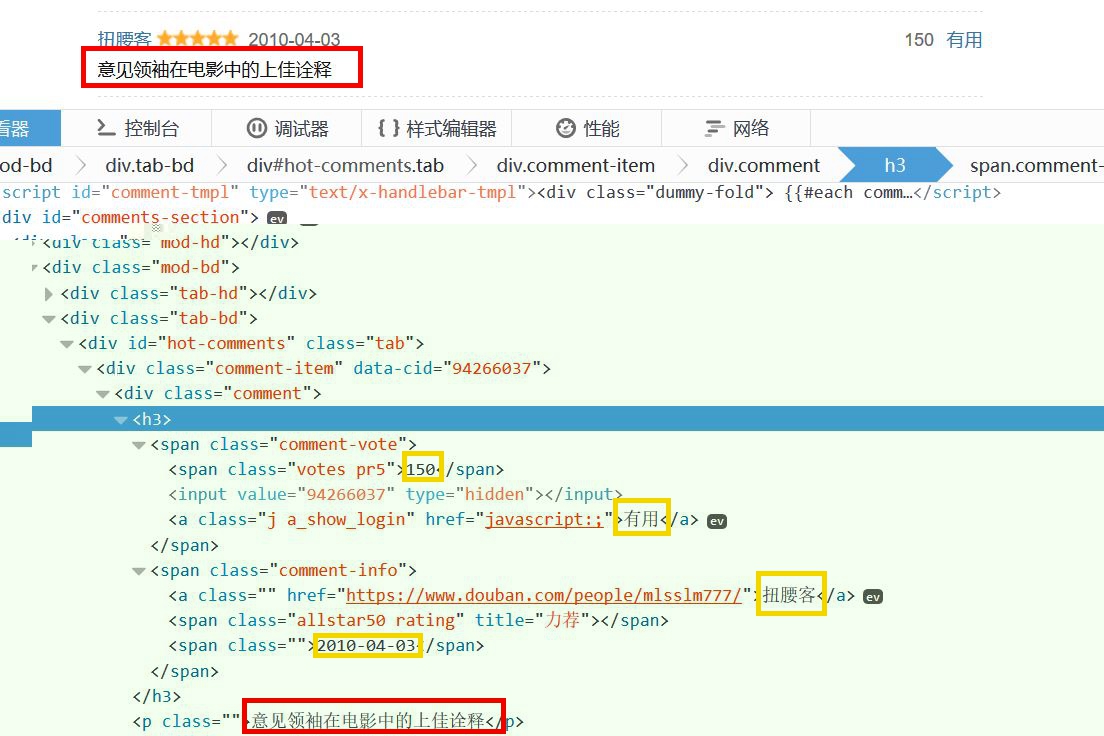
比如说,我只想要红色的部分,那么,采取elements就不太好处理。
2.解决方案,我采用的方法是格式化字符串!这个方法我在Selenium+PhantomJS自动续借图书馆书籍(下)也用过,根据元素的特性,可以发现,每个热评的正文标签不一样的,其余标签一样,只要格式化正文标签即可,像这样
for i in range(1,5):#取了前四条热评
try:
comments = driver_detail.find_element_by_xpath("//div[@id='hot-comments']/div[%s]/div/p"%i)
print u"最新热评:"+comments.text
except:
print 'can not caught comments!'3.一个引擎干有个事!我现在没办法,只有将第一个需要处理的页面用Firefox来处理,之后评论用PhantomJS来抓取,之后可以用quit来关闭浏览器,但是启动浏览器还是会耗费好多资源,而且挺慢,虽然PhantomJS也很慢,我12G内存都跑完了。。。。。。看样子是给我买8x2 16G双通道的借口啊。
4.备注不标准也会导致程序出错,这个是我没想到的,我一直以为在”’备注”’之间的都可以随便来,结果影响程序运行了,之后分模块测试才注意到这个问题,也是以前没有遇到过的,切记!需要规范自己代码,特别是像Python这样缩进是灵魂的语言。。。。
最后
耗费好多时间整这个,特别是调用引擎的问题折磨了我半下午,还有就是等待页面加载的问题,代码很简单,但是调试的时间却很久,差不多这个小爬虫花了我五六个小时!!主程序没啥问题,但是调试和修BUG花了好多时间!还是不够成熟啊技术。。。。
PS
科四一点没看,得停下来看看科四啦,我还想暑假回家开挖掘机呢——-0.0买了本Python的数据结构的书和网络数据采集的书,看来得好好的补补基础!
致谢
@MrLevo520–解决网页元素无法定位(NoSuchElementException: Unable to locate element)的几种方法
@Eastmount–[Python爬虫] Selenium+Phantomjs动态获取CSDN下载资源信息和评论
@Eastmount–[Python爬虫] 在Windows下安装PIP+Phantomjs+Selenium














 1400
1400











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









