







激活函数的作用:
为了增加神经网络模型的非线性,将一个很大范围的实数,映射到一个很小的范围之内。
为什么引入非线性激励函数?
如果不用激励函数(其实相当于激励函数是f(x) = x),在这种情况下你每一层输出都是上层输入的线性函数,很容易验证,无论你神经网络有多少层,输出都是输入的线性组合,与 没有隐藏层效果相当,这种情况就是 最原始的感知机(Perceptron)了。正因为上面的原因,我们决定引入非线性函数作为激励函数,这样深层神经网络就有意义了(不再是输入的线性组合,可以逼近任意函数)。
激活函数的比较:
Sigmod函数:
公式:
图像:
优劣:
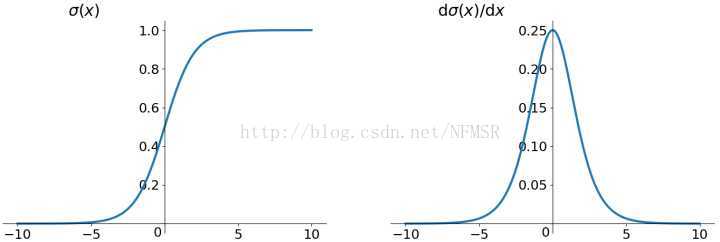
Sigmoid 非线性激活函数,sigmoid函数输入一个实值的数,然后将其压缩到0~1的范围内。特别地,大的负数被映射成0,大的正数被映射成1。
而现在sigmoid已经不怎么常用了,主要是因为它有两个缺点:
- Sigmoids saturate and kill gradients. (Sigmoid饱和and 梯度消失情况)Sigmoid容易饱和,并且当输入非常大或者非常小的时候,神经元的梯度就接近于0了,从图中可以看出梯度的趋势。这就使得我们在反向传播算法中反向传播接近于0的梯度,导致最终权重基本没什么更新,我们就无法递归地学习到输入数据了。另外,你需要尤其注意参数的初始值来尽量避免saturation(饱和)的情况。如果你的初始值很大的话,大部分神经元可能都会处在saturation的状态而把gradient kill掉(导数为0,梯度消失,梯度下降非常慢),这会导致网络变的很难学习。
- Sigmoid outputs are not zero-centered. Sigmoid 的输出不是0均值的(不是以0为中心),这是我们不希望的,因为这会导致后层的神经元的输入是非0均值的信号,这会对梯度产生影响:假设后层神经元的输入都为正(e.g. x>0 elementwise in
f=wTx+b
),那么对w求局部梯度则都为正,这样在反向传播的过程中w要么都往正方向更新,要么都往负方向更新,导致有一种捆绑的效果,使得收敛缓慢。 (这里有点不太理解)
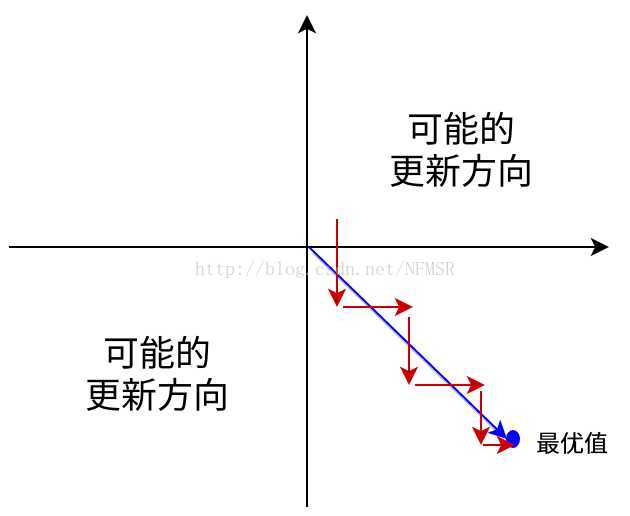
这会导致如下图红色箭头所示的阶梯式更新,这显然并非一个好的优化路径。深度学习往往需要大量时间来处理大量数据,模型的收敛速度是尤为重要的。所以,总体上来讲,训练深度学习网络尽量使用zero-centered数据 (可以经过数据预处理实现) 和zero-centered输出。
当然了,如果你是按batch去训练,那么每个batch可能得到不同的符号(正或负),那么相加一下这个问题还是可以缓解。因此,非0均值这个问题虽然会产生一些不好的影响,不过跟上面提到的 kill gradients 问题相比还是要好很多的。
tanh函数:
公式:
以上两种表现形式等价
图像:
优劣:
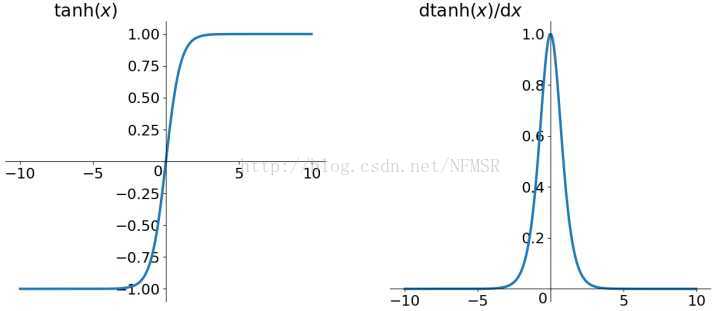
Tanh和Sigmoid是有异曲同工之妙的,不同的是它把实值得输入压缩到-1~1的范围,因此它基本是0均值的,也就解决了上述Sigmoid缺点中的第二个,所以实际中tanh会比sigmoid更常用。但是它还是存在梯度饱和的问题(问题一),从公式上我们可以看出tanh函数就是sigmod函数的一个变形。
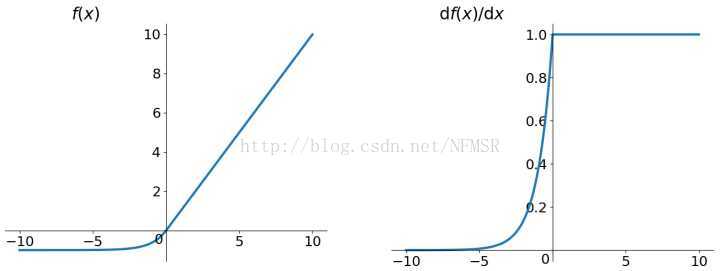
ReLu函数:
公式:
图像:
优劣:
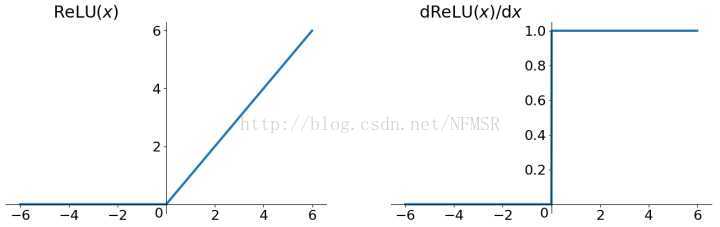
- 优点1:发现使用 ReLU 得到的SGD(随机梯度下降法)的收敛速度会比 sigmoid/tanh 快很多(如上图右)。有人说这是因为它是linear,而且梯度不会饱和
- 优点2:相比于 sigmoid/tanh需要计算指数等(幂运算相对耗时),计算复杂度高,ReLU 只需要一个阈值就可以得到激活值,如果 x<0,f(x)=0 ,如果 x>0,f(x)=x 。加快了正向传播的计算速度。
- 优点3:Relu会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生。
- 缺点1:ReLU的输出不是zero-centered
- 缺点2:Dead ReLU Problem: ReLU在训练的时候很”脆弱”,一不小心有可能导致神经元”坏死”。举个例子:由于ReLU在x<0时梯度为0,这样就导致负的梯度在这个ReLU被置零(置零后,神经元传播,以后的值均为0,无法再次被激活),而且这个神经元有可能再也不会被任何数据激活。如果这个情况发生了,那么这个神经元之后的梯度就永远是0了,也就是ReLU神经元坏死了,不再对任何数据有所响应。实际操作中,如果你的learning rate 很大,那么很有可能你网络中的40%的神经元都坏死了。 当然,如果你设置了一个合适的较小的learning rate,这个问题发生的情况其实也不会太频繁。
Leaky ReLU函数:
公式:
reLU 中当 x<0 时,函数值为 0。而 Leaky ReLU 则是给出一个很小的负数梯度值,比如 0.01。
图像:
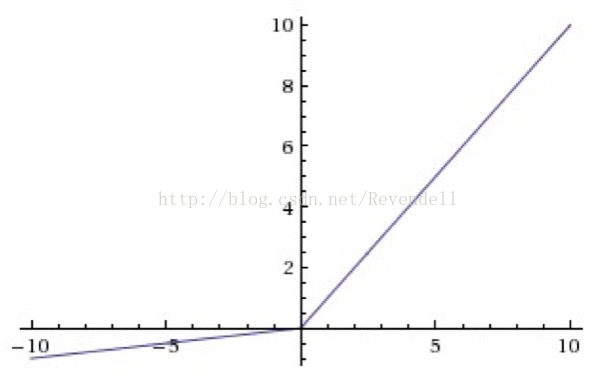
优劣:
-
- 优点1:解决Dead ReLU Problem,既修正了数据分布,又保留了一些负轴的值,使得负轴信息不会全部丢失
- 缺点:性能不稳定,众说纷纭,没有清晰的定论。有些人做了实验发现 Leaky ReLU 表现的很好;有些实验则证明并不是这样。
ELU (Exponential Linear Units) 函数
公式:
图像:
优劣:
- 优点1:不会有Deal ReLU问题
- 优点2:输出的均值接近0,zero-centered
- 缺点:计算量稍大,理论上虽然好于ReLU,但在实际使用中目前并没有好的证据ELU总是优于ReLU。
Parametric ReLU函数:
对于 Leaky ReLU 中的 α ,通常都是通过先验知识人工赋值的。
然而可以观察到,损失函数对 α alpha的导数我们是可以求得的,可不可以将它作为一个参数进行训练呢?
Kaiming He的论文《Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification》指出,不仅可以训练,而且效果更好。公式非常简单,反向传播至未激活前的神经元的公式就不写了,很容易就能得到。对 α 的导数如下:
δyiδα=0,(ifyi>0),else=yi原文说使用了Parametric ReLU后,最终效果比不用提高了1.03%.
Randomized ReLU函数:
Randomized Leaky ReLU 是 leaky ReLU 的random 版本 ( α alpha 是random的).
它首次试在 kaggle 的NDSB 比赛中被提出的。核心思想就是,在训练过程中, α 是从一个高斯分布 U(l,u) 中 随机出来的,然后再测试过程中进行修正(有点像dropout的用法)。
数学表示如下:

在测试阶段,把训练过程中所有的 αij 取个平均值。NDSB 冠军的 α 是从 U(3,8) [Math Processing Error] 中随机出来的。那么,在测试阶段,激活函数就是就是:
yij=xijl+u2
Maxout函数:
Maxout出现在ICML2013上,作者Goodfellow将maxout和dropout结合后,号称在MNIST, CIFAR-10, CIFAR-100, SVHN这4个数据上都取得了start-of-art的识别率。
Maxout 公式如下:
fi(x)=maxj∈[1,k] zij
假设 w 是2维,那么有:
f(x)=max(wT1x+b1,wT2x+b2)
可以注意到,ReLU 和 Leaky ReLU 都是它的一个变形(比如, w1,b1=0 的时候,就是 ReLU).
Maxout的拟合能力是非常强的,它可以拟合任意的的凸函数。作者从数学的角度上也证明了这个结论,即只需2个maxout节点就可以拟合任意的凸函数了(相减),前提是”隐隐含层”节点的个数可以任意多.
所以,Maxout 具有 ReLU 的优点(如:计算简单,不会 saturation),同时又没有 ReLU 的一些缺点 (如:容易 go die)。不过呢,还是有一些缺点的嘛:就是把参数double了。其他激活函数:
















 7190
7190











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









