








优化指标和满足指标
这是组合多个评估指标的另一种方法。
假设你同时关心算法的准确率和运行时间。你需要在下面三个分类器中进行选择:
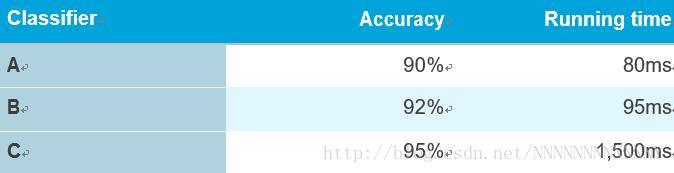
这里如果将准确率和运行时间组合为单个评估指标会看起来不太自然,例如:
Accuracy−0.5∗RunningTime
这里你可以替代为这样:首先,定义一个“可接受”的运行时间。例如我们说任何运行时间在100ms以内的算法都是可接受的。这里,运行时间就是一个“满足度量(satisficing metric)”——你的算法只需要在这个指标上表现地“足够好(good enough)”就行,在这个意义上它应该满足最多100ms。准确率是一个“优化度量(optimizing metric)”。
如果你正在权衡N个不同的标准,例如模型的二进制文件大小(这对于移动app很重要,因为用户不想要下载很大的程序),运行时间和准确率等。你可以考虑设置其中N-1个标准为“满意(satisficing)”指标,也就是说你只需要他们满足特定的值即可。然后将最后一个定义为“优化(optimizing)”指标。例如,为二进制文件大小和运行时间设定可接受的阈值,并尝试在这些约束条件下不断优化准确率。
作为最后一个例子,假定你正在构建一个硬件设备,该设备使用麦克风监听用户说出的某个特定的“唤醒语(wakeword)”,从而唤醒系统。例如:Amazon Echo监听“Alexa”;苹果Siri监听“Hey Siri”;Android监听“Okay Google”;或百度app监听“你好百度(Hello Baidu)”。你同时关心假正例的比率(the false positive rate, 即当没有人说唤醒语时系统唤醒的频率)和假反例的比率(the false negative rate, 即当有人说出唤醒语时系统没有唤醒的频率)。对这个系统表现性能的一个合理的目标是最小化假反例的比率(优化指标,optimizing metric),同时满足每24小时操作出现不超过一个假正例即可(满足指标,satisficing metric).
一旦你的团队对评估指标进行优化,他们将能够更快地取得进步。














 607
607











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









