







欢迎转载,转载注明原文地址:
http://blog.csdn.net/neighborhoodguo/article/details/47174415
又开始新一课的札记啦!最近Project Proposal也快到了,时间还是比较紧的。不过课程已经过半了还是挺开心的。stanford开放这么有技术含量的课程,还是很钦佩stanford的开放精神。
这一课是对Recurrent NN for MT做了一个简要的介绍。个人认为这种方法比较靠谱耶,想想我们人类对于母语的学习,对于母语的理解,从来都不是先分析语法,再分析语义的,而是直接就从前到后听或看久直接理解了。RNN对于语言的理解表示我个人认为比较类似人类的思维方式(如果有朋友看到我这篇文章有不同见解,欢迎讨论)。而这门课的Project我就做这个好啦,哈哈。使用RNN的MT!
先梳理一下这一讲的脉络哦。首先是对Bidirectional及deep RNNs for opinion labeling的wrapping up,然后是现今MT的pipeline,再最后就是Recurrent NN实现MT的大体思路及方法,再往后就是几个Recurrent NN实现MT的改进措施。
1.Wrapping up
Deep Bidirectional RNNs这个结构上一课讲得很详细了,这次就不表了。
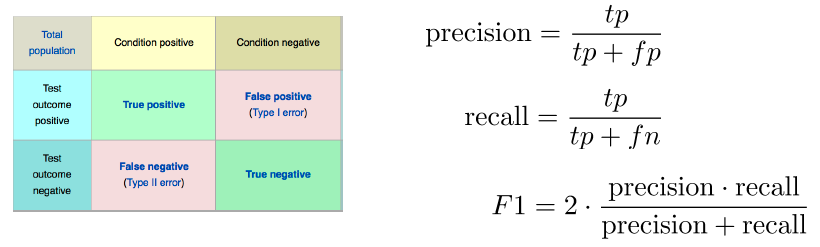
F1 score这个东西的解释这次给了个图,非常好呢。十分直观清楚。
Parallel corpora的例子:欧盟的议会文件,埃及出土的大石头(- -)
2.现今tranditional MT的pipeline
第一步是Alignment顾名思义就是source language里的词对应到target language是哪个词。
这个东东真的是很复杂呀,最简单的情况是一对一的,但是还有zero fertility,一对多的,多对一的,多对多的,好烦躁有木有。
Alignment之后还没完,还得reordering这些词,使其在target language里表达的很“正确”。
本来Alignment就很复杂,还得从中选出最适合的词,还得reordering这个可真是。。。说不下去了。怎么办?RNN闪亮登场!
3.RNN model for MT
首先是最简单的例子
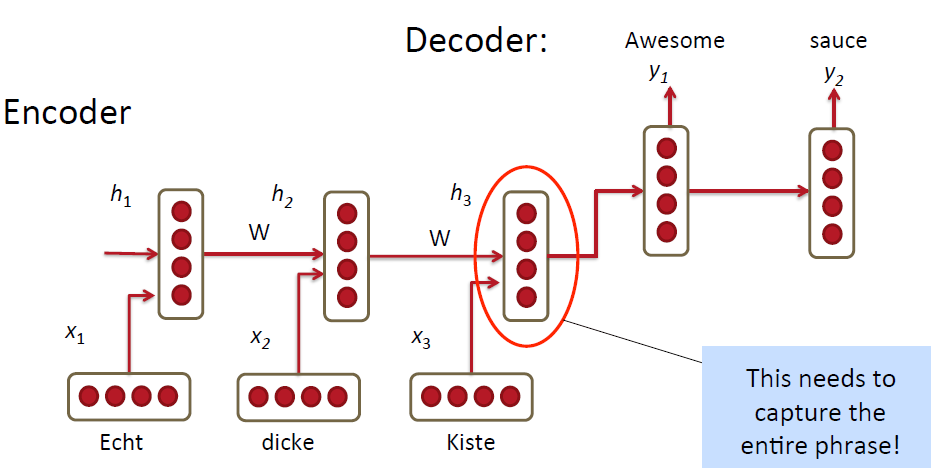
使用RNN把source language的单词一个一个的输入到model里,最终把这一整句话用一个vector表示出来,也就是encoder的过程;然后得到最终的vector之后再decoder将原始的句子用target language表示出来。看起来挺诱人挺高效的有木有!但是其实米有这么简单呀!
于是就duang推出了第一种加强改良版
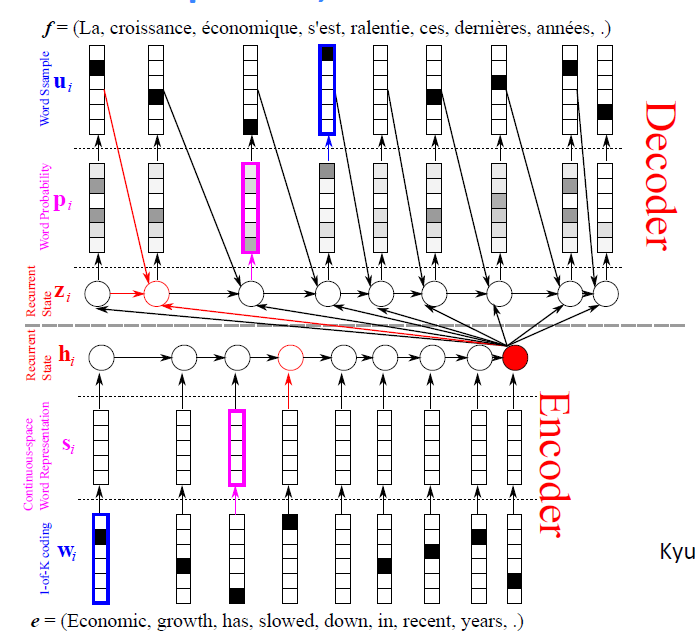
decoder的过程不仅仅是从最后一个hidden node(以下简写为C)中提取信息,还从前一个decoder出来的单词及前一个hidden node里提取信息。这样有什么好处我也不造(- -)据老师说很棒。
还有几个一是改良方法是使用stacked/deep RNNs;二是使用bidirectional encoder,而不是使用最简单的一层的encoder;三是把单词的顺序倒个个,原因说的是第一个单词的信息能很容易保留下来,然后target language就能很容易从中提取出信息,做出有效的翻译(说实话没搞明白为啥有用)
最后有两个超级改良版:GRU和LSTMs
4.GRU
main ideas: 1.keep around memories to capture long distance dependencies
2.allow error messages to flow at different strengths depending on the inputs
推荐阅读里有有两篇讲GRU的,讲得挺好的,受益匪浅。Paper里还将LSTM和GRU进行了对比。
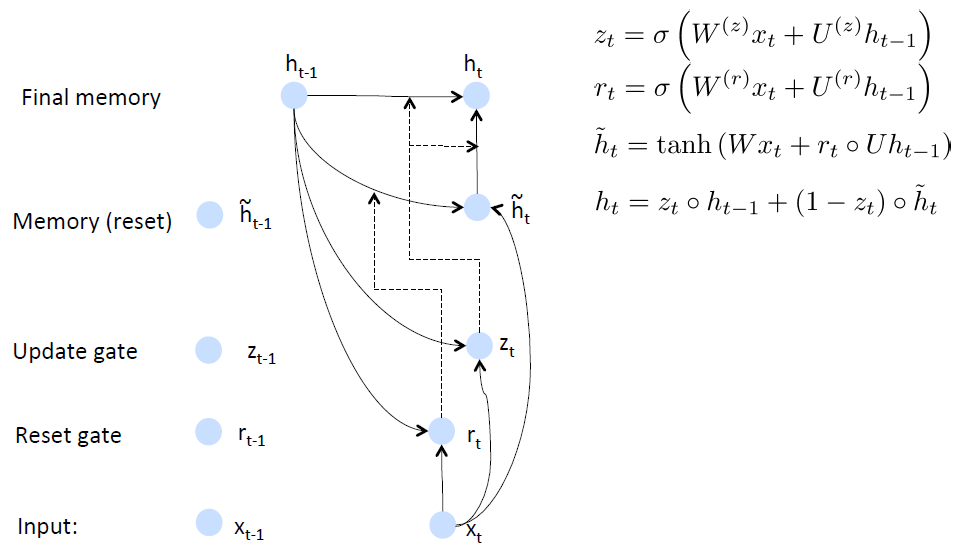
GRU的思路是首先根据当前word vector及前一个hidden state计算出update gate和reset gate;再根据reset gate、当前word vector及前一个hidden state计算出new memory content。
reset gate的用处很明确了,就是当reset gate为1的时候,new memory content忽略之前所有的memory。最终的memory是之前的hidden node及new memory content的综合体
数学公式表示就是:
5.LSTMs
这个东西有很长时间的历史了不过据说很有用。直接上公式吧,公式很清晰:

6.GRU和LSTMs的区别
说实话GRU和LSTMs其实是很像的先上个对比图吧:
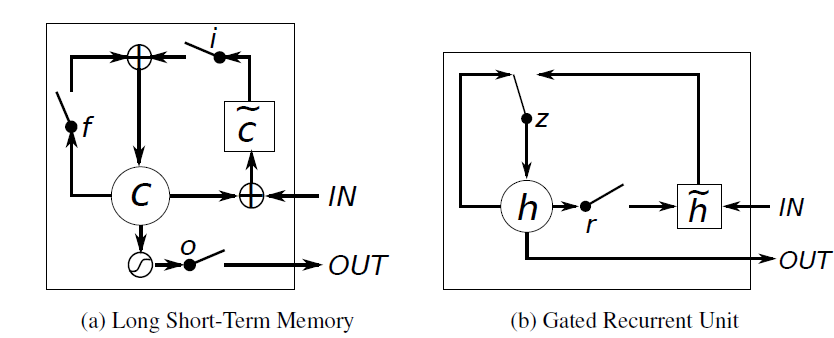
以下说说他们之间的相同与不同:
1.new memory的计算方法都是根据之前的state及input计算,但是GRU有一个R gate控制之前state的进入量,在LSTM里没有这个gate
2.产生新的state的方式不同,LSTM有两个不同的gate分别是f gate和i gate;GRU只有一个gate就是z gate
3.LSTM对新产生的state有一个o gate可以调节大小;GRU直接输出无任何调节。
参考网址:
http://www.ubi.com/
https://github.com/jych/librnn.git














 242
242











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









