







考虑到在CSDN,没有搜索到很多关于javacc的东西,绝对干货。
javacc概述
javacc概述
JavaCC 是一个词法分析生成器和语法分析生成器。 词法分析和语法分析是处理输入字符序列的软件构件, 编译器和解释器协同词法分析和语法分析来“解密” 程序文件。
javacc的获取:https://java.net/projects/javacc/downloads从此处下载了javacc 5.0 然后解压并在path环境变量中添加 解压后的bin目录即可。
词法分析器可以将字符串解析为一个一
个的标识符(Token), 并且可以把这些标识符归类。 看一段 C 语言代码:
int main() {
return 0 ;
}经过C语言的词法分析会将代码分为如下的一些标识符
“int” , “ ” , “main” , “(” , “ )” ,“ ” , “{” , “ \n” ,“ \t” ,
“return” “ ” , “0” , “ ” , “;” , “ \n” ,“ }” , “ \n” , “ ” 还会进行分类,C语言的词法分析器会将其分为如下:
KWINT, SPACE, ID, OPAR, CPAR,
SPACE, OBRACE, SPACE, SPACE, KWRETURN,
SPACE, OCTALCONST, SPACE, SEMICOLON, SPACE,
CBRACE, SPACE, EOF。EOF代表文件的结束。经过词法分析,将这些标识符传给语法分析器。在C语言中 SPACE(空格) 是不需要的。
语法分析器将生成语法树:
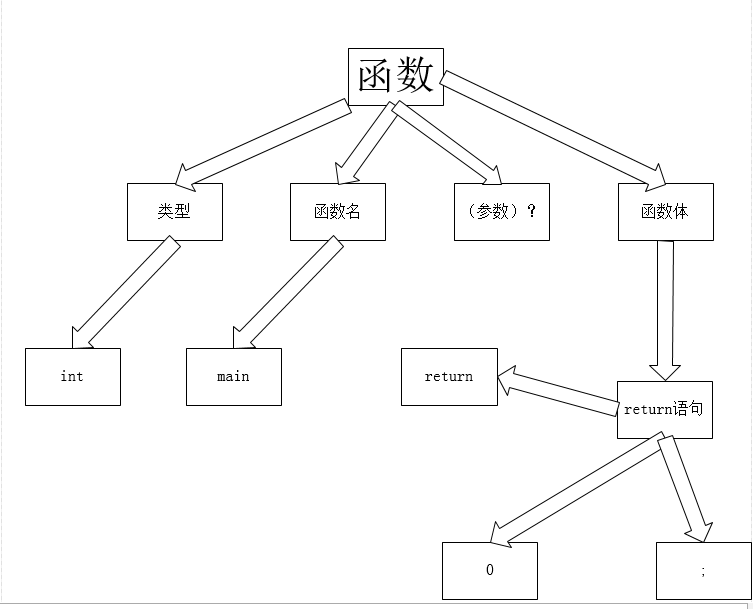
javacc的特性
javacc有几个重要的特性需要记住的:
使用递归下降语法解析,LL(k)。其中,第一个L表示从左到右扫描输入;第二个L表示每次都进行最左推导(在推导语法树的过程中每次都替换句型中最左的非终结符为终结符。类似还有最右推导);k表示的是每次向前探索(lookahead)k个终结符
词法规则,语法规则定义在同一文件中,就是.jj文件。
jjTree可以帮助更好的语法分析(因为好像没用过,不好说啊)
可定制生成的行为,如对字母的大小写是否敏感。不如设计数据库sql语句的时候应该使用关键字大小写不敏感。
更向前一步解决移进规约。当文法本身存在二义性的时候有时候通过设置lookahead为k能解决问题,带来的问题就是增加编译时间,所以最好的方法是修改二义性文法为无二义性文法。
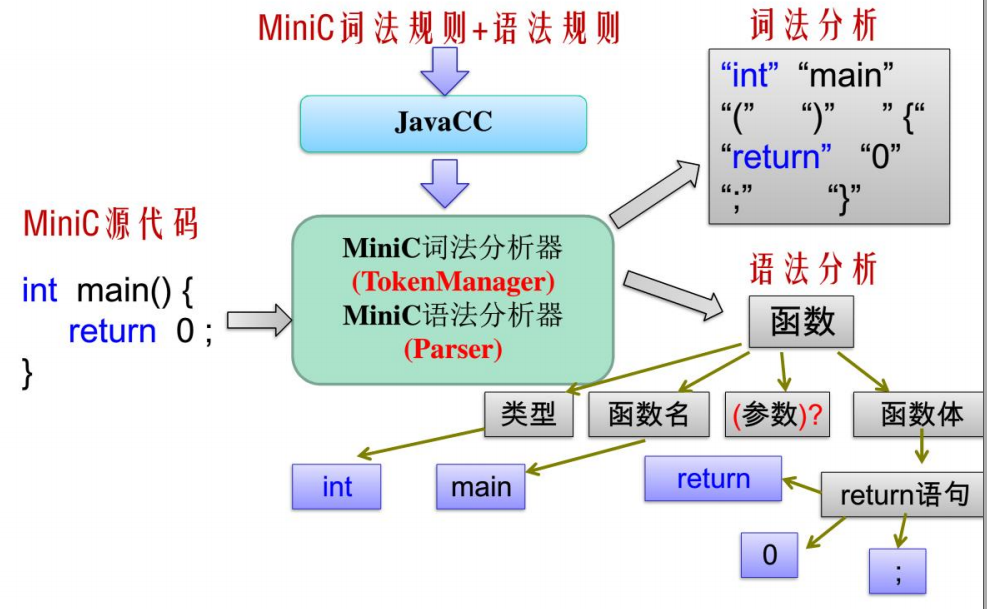
执行的流程如下图所示:
javacc生成的类
通过执行javacc Adder.jj命令以后(如果没有错误的话)生成了这个的七个java文件。
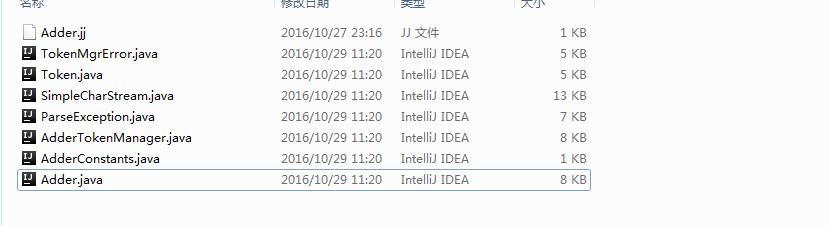
他们是:
TokenMgrError:
简单的错误类,词法错误,实现了Throwable接口。
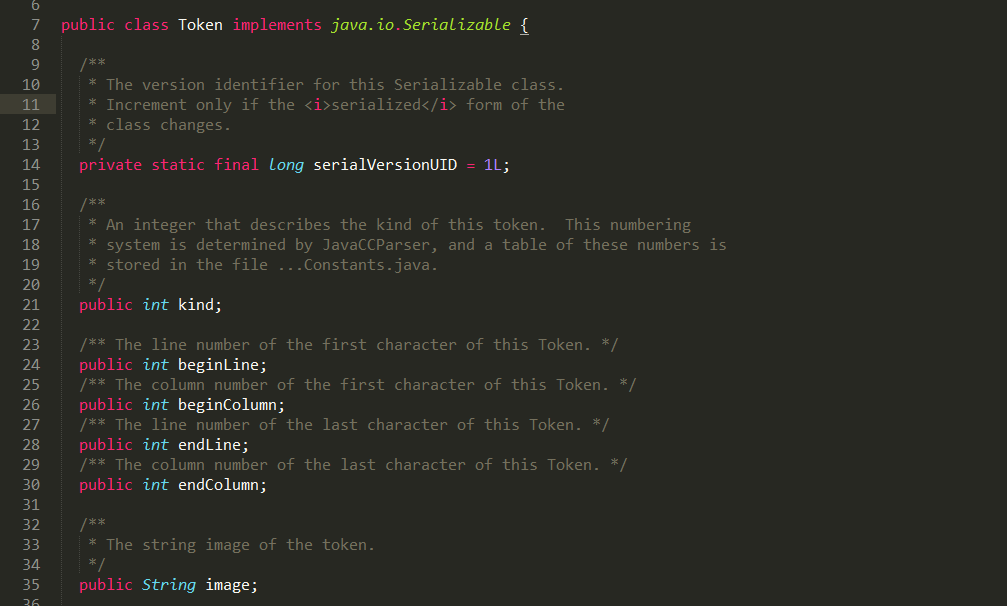
Token 类:
单词定义处;每个单词至少由一个int型的kind变量来标识单词的”ID” 和一个String类型的image变量来标识单词的具体内容。
ParseException:
语法异常类,实现Exception接口,通常出现这种情况就是解析器罢工了。
SimpleCharStream:
辅助类,用于输入字符串。可以接受InputStream类型和Reader类型的输入流。
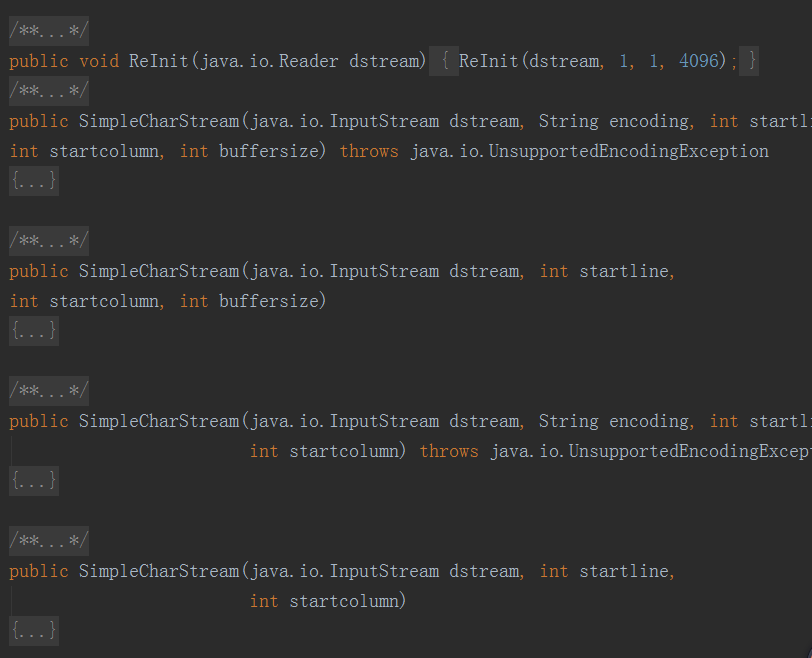
AdderTokenManager:
Adder的词法分析器。
词法分析器有三个重要成员变量和方法:
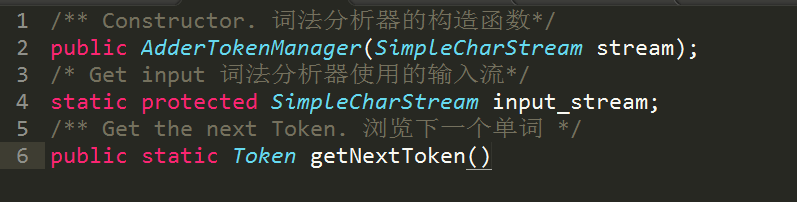
AdderConstants:
含常量的辅助性接口。
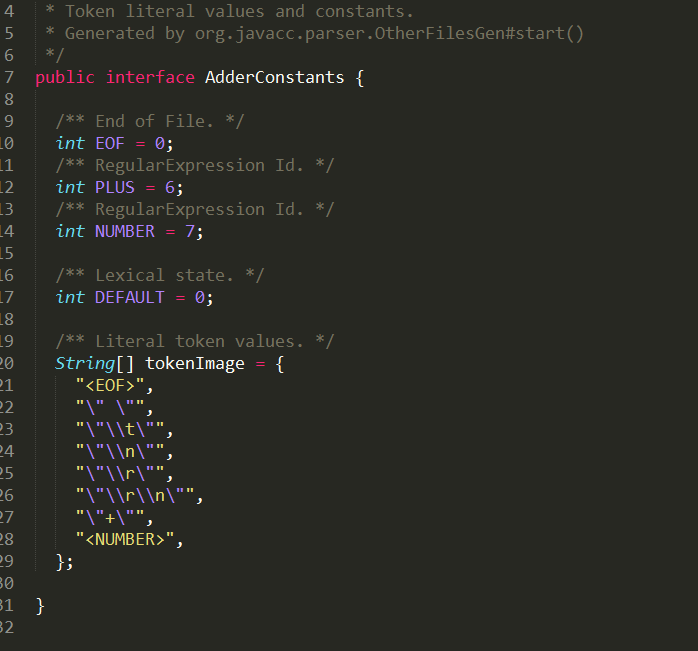
Adder:
语法分析器。其中Adder中的方法来源于三个地方
写在PARSER_BEGIN和PARSER_END中的部分,即类声明部分的方法
写在语法结构部分的方法。
- 写在JavaCC中的方法。
贴出Adder.jj的代码
PARSER_BEGIN(Adder)
public class Adder{
public static void main(String[] args) throws ParseException, TokenMgrError{
Adder adder= new Adder(System.in);
System.out.println(adder.start());
}
}
PARSER_END(Adder)
SKIP:{
" "
| "\t"
| "\n"
| "\r"
| "\r\n"
}
TOKEN:{
<PLUS :"+">
|<NUMBER:(["0"-"9"])+>
}
int start() throws NumberFormatException:
{
Token a;
int i;
int value;
}
{
value=primary()
(
<PLUS>
i=primary()
{value += i;}
)*<EOF>
{return value;}
}
int primary() throws NumberFormatException:
{
Token t;
}
{
t=<NUMBER>
{return Integer.parseInt(t.image);}
}
则在Adder.java中则存在这样的几个函数:
如何组织.jj文件
如何写javacc语法文件,将在未来的另外博客中体现,这个部分是实现的过程中最重要的部分了。
主要有4个方面需要注意
语法分析器的属性设置
语法分析器的类声明
词法规则声明
语法规则实现
语法分析器的属性设置
options{
JDK_VERSION=1.5; //jdk版本
LOOKAHEAD=1;//LL(1)文法
static=true;//语法分析器是否为静态
}关于这个option有很多内容可以讲,由于一下子找不到资料,将在未来补充或者在另外一篇博客说明。
语法分析器的类声明
PARSER_BEGIN(Adder)
public class Adder{
public static void main(String[] args) throws ParseException, TokenMgrError{
Adder adder= new Adder(System.in);
System.out.println(adder.start());
}
}
PARSER_END(Adder)
注意此处PARSER_BEGIN和PARSER_END应该与类声明一致即Adder
词法规则声明
/*跳过的字符*/
SKIP:{
" "
| "\t"
| "\n"
| "\r"
| "\r\n"
}
/*单词*/
TOKEN:{
<PLUS :"+">
|<NUMBER:(["0"-"9"])+>
}
语法规则实现
int start() throws NumberFormatException:
{
Token a;
int i;
int value;
}
{
value=primary()
(
<PLUS>
i=primary()
{value += i;}
)*<EOF>
{return value;}
}
int primary() throws NumberFormatException:
{
Token t;
}
{
t=<NUMBER>
{return Integer.parseInt(t.image);}
}
词法规则注意事项(举例)
局部词法分析

在词法声明部分,以#号开头的token只是在词法分析时使用,而不能做法语法分析的输入,也就是说。它相对词法分析是局部的,内部的。

防止词法定义失效
具有包含关系的词法定义,必须防止实现的情况,如果对于Key的声明必须定义在IDENTIFIER之前。这个问题最常见!!

举例:
Encountered "not ( employee" at line 3, column 43.Was
expecting one of:
<EOF>
<rpath> ...
"not" "(" ...
"not" "(" <rpath> ...(1) Token定义:
<string:(["A"-"Z","a"-"z","0"-"9"])+>
<not:"not"> 看上去,句子遇到 not 应该解析成 TOKEN not,其实不然,它会
被解析 TOKEN string.因为字符串 not 是符合 TOKEN string 的定义的,并
且在顺序上 TOKEN string 在前,所以先被匹配成 TOKEN string.如果将两
者的顺序更换一下,就能正确的解析成 TOKEN not 了
(2) 自定义变量导致的:
void test(): {int not=0;}
{
<not><leftb>key=<rpath><rightb>
{
not=1;
}
}在这里,有一个自定义的变量名和 TOKEN not 名称一样。将 JJ 文件生成JAVA 类之后,你会发现,对于 TOKEN not显示的颜色,会跟其它的 TOKEN 不一样。这就是由于在 JAVA 类中,两个变量not 和 TOKEN not 二者冲突了。如果将这个变量名改为 no 或者其它的,TOKEN not 就能被正常解析了。
语法规则注意事项
语法部分决定了编译器的功能是否强大。
文法中没有每一个非终结符对应一个函数,函数调用表示非终结符之间的组成关系。
明确编译器的主要功能
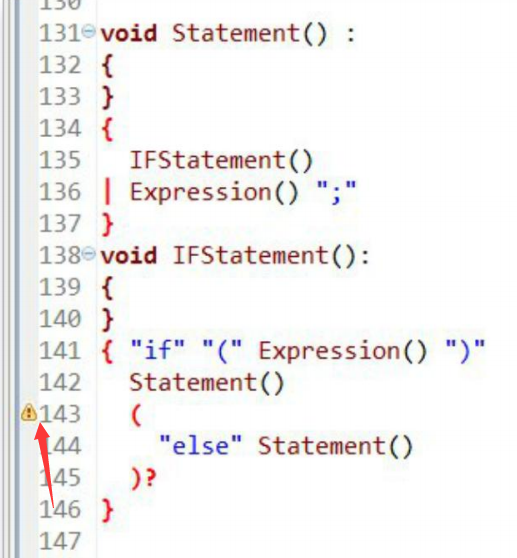
语法分析阶段会存在二义性文法,在Eclipse代码中会有小黄三角,解决办法是个别冲突可以实现LOOKAHEAD(K)解决问题,比如在143行后加一个
LOOKAHEAD(1),最好的方法是修改为非二义性文法,具体看编译原理书吧。
添加语义规则
JavaCC采用自顶向下的语法分析,所以可以在文法的任意位置添加语义子程序
只需要在需要添加语义子程序的地方使用花括号即可;

需要注意的是在1处添加的语义子程序,往往是用来实例化变量的,这些变量将在语法分析过程中被使用。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









