









R语言(三)数据的导入,包括以下几个部分的内容:
1.数据类型介绍
2.数据导入
3.抓取网络数据
一.数据类型
1)Excel、Spreadsheet数据:.csv格式数据
2)文本文件数据(非结构化数据,每一行长度不同):.txt格式数据
3)delim 格式读取
R语言直接读取网络数据——通过R语言内置的具有网络通讯packages,分析金融数据
4)xml包抓取网络数据
5)RCurl语言包爬取
R可以处理的数据类型(模式)包括数值型、字符型、逻辑型(TRUE/FALSE)、复数型(虚数)、原生型(字节)。
存储数据的对象类型:
标量:只含有一个元素的向量.用于保存常量
f <-3 , g <-"US" , h <- TRUE
向量: 1.只能包含一种数据类型
通过在方括号中给定元素所处位置的数值,可以访问向量中的元素。a[c(2,4)]访问向量a中的第二个和第四个元素。
>a <-c(1,2,2,4)
>a
[1] 1 2 24
> a <- c(1:10) #生成数值序列
>a
[1] 1 2 3 4 5 6 7 8 9 10
> a[2] #取单个向量
[1] 2
> a[c(3,7,8)] #取多个向量
[1] 3 7 8
矩阵matrix: 1.二维数组
2.只能包含一种数据类型,每个元素拥有相同的模式(数值型、字符型或逻辑型)
mymatrix <- matrix (vector矩阵元素,nrow=行数,ncol=列数,dimnames=list(以字符型向量表示的列名和行名),byrow=T矩阵按行填充,默认情况下按列填充)
##Example1 of setting row and column names
mdat<- matrix(c(1,2,3,11,12,13), nrow = 2, ncol = 3, byrow = TRUE, dimnames =list(c("row1", "row2"),c("C.1", "C.2","C.3")))
##Example2 of setting row and column names
> cells <- c(1,26,24,68)
>rnames <- c ("R1","R2") #给行取名
>cnames <- c("C1","C2") #给列取名
> mymatrix <-matrix(cells,nrow=2,ncol=2,byrow=T,dimnames=list(rnames,cnames))
> mymatrix
C1 C2
R1 1 26
R2 24 68
> x <-matrix(1:20,nrow=4) #nrow确认,ncol默认
>x
[,1] [,2] [,3] [,4] [,5]
[1,] 1 5 9 13 17
[2,] 2 6 10 14 18
[3,] 3 7 11 15 19
[4,] 4 8 12 16 20
> x[1,] #取第二行
[1] 1 5 9 13 17
>x[3,] #取第三行
[1] 3 7 1115 19
> x[,2] #取第二列
[1] 5 6 78
>x[,4] #取第四列
[1] 13 1415 16
>x[2,3] #取第(2,3)元素
[1] 10
>x[1,c(4,5)] #取第一行,第四、第五列第元素
[1] 13 17
数组 array: 1 .维度超过2时用数组,数组中的数据只能拥有一种模式
2.数组是矩阵的一个自然推广,2维的数组相当于矩阵A two-dimensional array is the same thing as a matrix.
3.一维数组看起来像向量One-dimensionalarrays often look like vectors, but may be handled differently by somefunctions: str does distinguishthem in recent versions of R.
myarray <- array(vector数组中的数据, dimensions=c(1,2,3……)各个维度下标的最大值, dimnames各个维度名称标签的列表)
>dim1 <-c("A1","A2")
>dim2 <-c("B1","B2","B3")
> dim3 <-c("C1","C2","C3","C4")
> z <-array(1:24,c(2,3,4),dimnames=list(dim1,dim2,dim3))
>z
数据框: 1.多种模式数据(数值型、字符型等)时,使用数据框。不同的列可以包含不同模式的数据。等价于SAS、SPSS、Stata中看到
的数据集
2.由于数据有多种模式,无法将此数据集放入一个矩阵,这种情况下,使用数据框是最佳选择
mydata<- data.frame (col1,col2,col3,……) #其中的列向量col1,col2,col3……可为任何类型,每一列的名称可由函数names指定
> patientID<- c(1,2,3,4) #每一列的数据模式必须唯一
> age <-c(25,34,28,52)
> diabetes <-c("Type1","Type2","Type1","Type1")
> status <-c("Poor","Improved","Excellent","Poor")
> patientdata <-data.frame(patientID,age,diabetes,status) #每一列的数据模式必须唯一,但可以将多个模式的不同列放到一起组成数据框
> patientdata
patientID age diabetes status
1 1 25 Type1 Poor
2 2 34 Type2 Improved
3 3 28 Type1 Excellent
4 4 52 Type1 Poor
> patientdata[1:2] #选取数据框中的元素
patientID age
1 1 25
2 2 34
3 3 28
4 4 52
>patientdata[c("diabetes","status")] #选取数据框中的元素
diabetes status
1 Type1 Poor
2 Type2 Improved
3 Type1 Excellent
4 Type1 Poor
> patientdata$age #$被用来选取一个给定数据框中的某个特定变量
[1] 25 3428 52
> table(patientdata$diabetes,patientdata$status) #生成糖尿病类型变量diabetes和病情变量status的列联表
Excellent Improved Poor
Type1 1 0 2
Type2 0 1 0
列表
二.小容量批处理数据
R语言是基于内存的数据统计和分析软件,的内存会影响R的运行处理速度。当需要处理T级、Z级数据时,解决方法为算法优化或利用R的packages函数处理大数据,具体实现方法会在后面的博客中介绍给大家。
1.read.命令读取数据
【此处引用数据来自: https://figshare.com 开放数据平台】
【方法一】RConsole
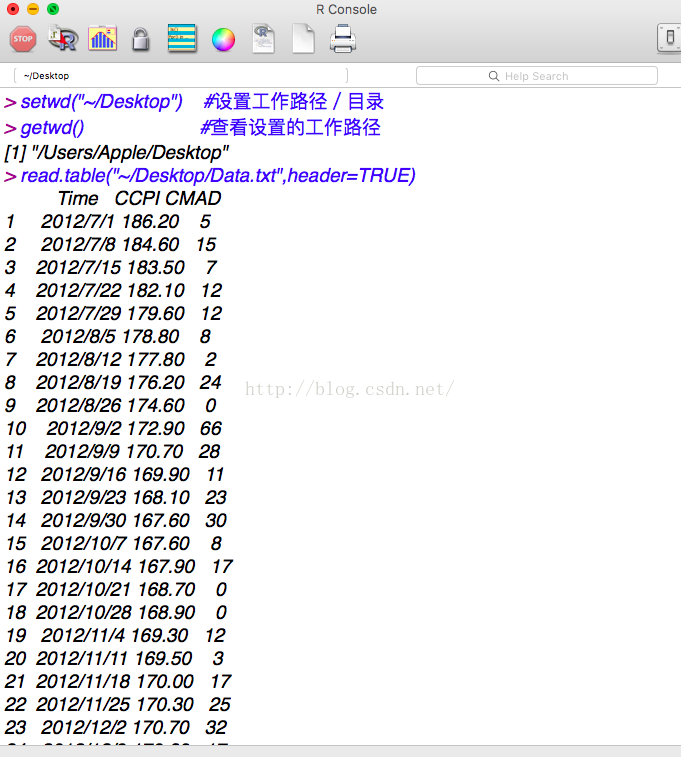
>setwd("~/Desktop") #设置工作路径/目录
>getwd() #查看设置的工作路径
1) txt数据读取
>read.table("~/Desktop/Data.txt",header=TRUE)
2)csv数据读取
>read.csv("~/Desktop/Data.csv",header=TRUE) #读取excel/Spreadsheet中的数据
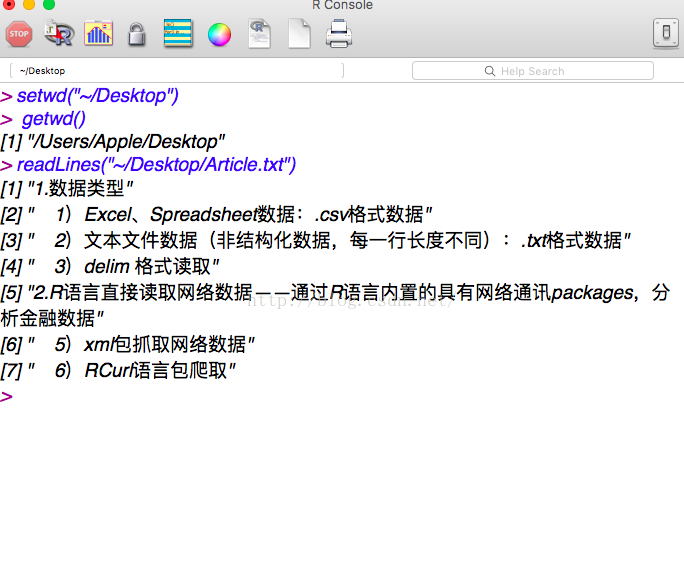
3)非结构化文本数据的读取
>readLines("~/Desktop/Article.txt") #非结构化文本格式的读取,按行进行数据读入
4)Excel文件的读入
excel文件的读入,依赖的扩展packages,很多是需要Java才能安装,如果是普通的excel文件,可以转换为.csv格式,可以先将excel文件转化为.csv格式的文件再进行读取。
直接读取excel文件的方法:
(packages的安装方法见 本系列博客Mac版R语言入门(一)R语言入门操作http://blog.csdn.net/nicolelovesmath/article/details/53244337第四部分)
方法I:RODBC包
RODBC依赖于ODBC的驱动程序管理器,安装完RODBC之后,需要配置ODBC的驱动程序,实现连接之后,才能调用RODBC的包。此处需要注意SQL的版本和R版本的兼容。
方法II:XLSX包
XLSX包,需要安装rJAVA的程序包。与电脑环境有关,电脑安装rJava难度很大,不建议使用
方法III:XLConnect包
XLConnect安装
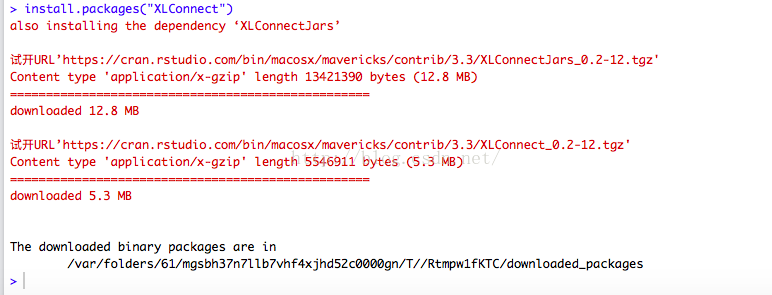
package安装完成
5)网络数据的访问
>read.csv("https://figshare.com/articles/Data_xlsx/4233182")
【方法二】RStudio














 3362
3362











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









