







1采用命令行操作时,所创建进程的pid编号、进程运行、撤销过程;
为实现此部分要求,我们编写一小段程序。它的设计想法是,接收用户的输入,直到得到我们需要的输入,才退出。当我们完成程序代码编写,并成功编译,运行这段可执行程序时,就创建了一个进程。进程创建后,可以通过ps命令查看到该进程的信息。该程序在接收到需要的输入后正常退出,当然,也可以通过终端强制结束,这也就是进程的撤销过程。
按照上述的思路,设计的程序代码如下:
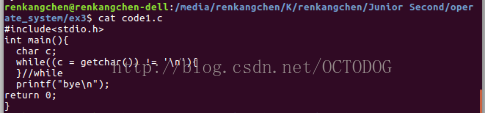
图1:code1 程序代码
编译运行该程序

图2:code1 程序的运行
通过在命令行启动该程序,我们创建了一个进程,此时,通过ps命令来查看该进程的信息。

图3:code1 进程信息
这里,我们用到ps命令来进行进程的查看,这个命令和top命令的区别在于:ps命令像为系统进程信息拍了张快照,而top命令则像是”现场直播“,也就是说ps得到的是静态的结果,而top得到的是实时的,动态的结果。
ps命令有许多的参数,常用的参数如下:
| 参数 | 含义 |
| a | 显示当前终端机下所有程序 |
| u | 以用户为主的格式来显示程序状况 |
| x | 显示所有的程序,不以终端机为区分 |
| e | 显示程序的环境变量 |
| f | 以ascii字符显示树状结构,显示程序间的相互关系 |
| l | 显示详细信息 |
| c | 显示程序真正的指令名称,而不包含路径,参数等标示 |
表格1:ps命令参数
常用的组合为ps aux ,ps ef,这里我们使用了ps aux来查看刚才创建的进程的信息。使用管道和grep命令结合,以方便查看。从图3可以看到,我们创建的进程的pid编号为16588。

图4:code1的正常运行和退出
从图4可以看到,我们连续的输入一串字符,在输入回车后,程序正常退出,此时再查看进程信息

图5:code1正常退出
从图5可以看到,程序正常退出后,再次查看此时系统的进程信息,此时已经没有名为code1的进程。
再次运行该code1程序,这次我们使用终端强制终止的方法来结束创建的进程。
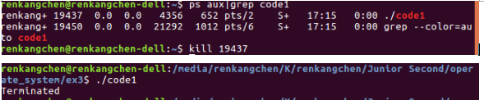
图6:code1 终结
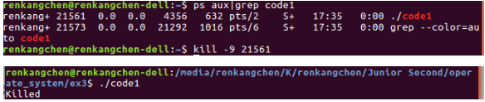
图7:code1 强制退出
和之前介绍的类似,我们使用ps命令来查看code1进程的信息。通过kill命令来强制终止该进程。
Kill命令可以用来强制终结一个进程,它包含很多可以使用的信号,但我们一般只会用到15 和 9,通过kill -l可以查看所有的信号。信号15,SIGTERM,这个信号用来请求停止运行一个进程,但并不是强制停止,进程可以有时间来完成资源释放等工作后,再停止。和信号15不同的,信号9,SIGKILL,这个信号强制进程立刻停止。Kill命令的使用格式为kill [信号/选项] PID,默认的信号是15,如果无效时,可以使用信号9。
从图6可以看出,我们使用了kill命令(信号15)来终结code1,程序提示Terminated,而我们使用带信号9的kill命令时,程序提示为,killed。
2采用系统函数调用时,进程的pid号、子进程创建前后的变化;
根据实验指导的提示,编写此部分的程序。其中关键之处为fork()函数的使用。fork()函数通过系统调用来创建一个和原进程几乎一样的进程。由fork()函数创建的新进程称为子进程。子进程是父进程的克隆(副本),它可以获得父进程的数据空间、栈、堆等资源的副本。fork()函数调用一次,能够返回两次,返回值有以下的三种情况
a 在父进程中返回创建的子进程的PID
b 在子进程中返回0
c 错误情况下,返回负值
编译运行编写的代码,通过查看执行情况来加深对上述fork()函数相关内容的理解。
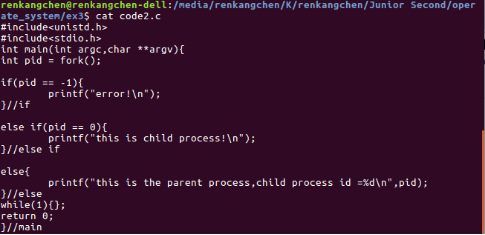
图8:code2.c

图9:code2执行情况
从图9可以看出,在执行code2后,输出了两条结果,根据我们之前的学习,这里显示了一条父进程的输出和子进程的输出。分析这个简单的程序,不难知道,在我们调用fork()函数以前,只有一个进程(父进程)在执行这段代码,而在调用结束后,这时便由父进程创建了一个新的子进程。子进程和父进程共享代码段,在子进程中,fork()返回的值为0,故输出“this is child process!”。在父进程中,fork()返回的值为子进程的PID,故输出为“..child process id = 9617”。
在这里,最开始比较难于理解的便是这个程序的执行结果。因为else if{}和else这是两句互斥的选择语句,怎么也不可能在一个程序执行过程中同时被执行。虽然我们根据实验指导书知道,该函数调用一次,返回两次,但怎么返回的,为什么会输出两句,其中的具体细节,请我们还是很模糊。在学习了书中的相关理论后,我们在code2的基础上增加两句话。
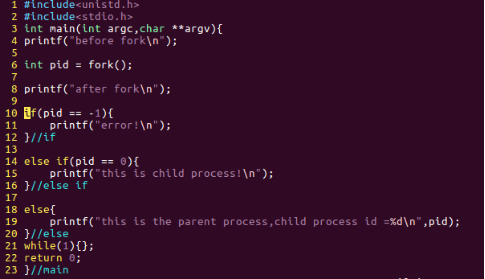
图10:code2 new
即是如图10所示中的第4 和第8行处的句子。可以推断,这个运行code2的结果应该是:
before fork
after fork
this is the parent process,child process id=***
after fork
this is child process!
推出这样的结果的根据是:在fork()函数之前,是父进程在执行,会输出一句“before fork”,而一旦执行到fork(),系统会创建和父进程几乎一样的子进程,这个时候,父进程和子进程谁先执行就不得而知了,要看系统的调度策略。特别注意的是,fork()创建的子进程是针对父进程执行到fork()时的当前的状态创建的,也就是说,在这个函数以前的代码,是不关子进程的事的。就像儿子没法时光倒流去干涉父亲十几岁的事,因为那个时候儿子都还没出生。而一旦子进程产生,父子俩就分道扬镳(如图12所示),各干各的,这也就是fork()函数为什么叫fork的原因了。所以,至此,我们最开始的疑惑也就明白了,这不是程序的一次执行,而是对应着两次执行过程——父子进程,在父进程中选择分支选择了else{},而在子进程中选择分支选择了else if{}。
图12:fork示意
我们运行一下修改后的code2:

图13:code2 new执行结果
从执行结果来看,我们的推断基本正确。
除了这种方式外,我们还可以通过GDB来进程多进程的调试。为了使用gdb调试,我们需要在编译时候加入调试选项-g,然后根据实验指导书的提示,设置多进程调试模式,并进行相应的调试工作。
通过ps命令来查看进程的情况。

图14:code2进程
可以看到PID为9617的子进程和它的父进程。
3父进程与子进程并发执行(父子进程完成相同计算量的任务,单个任务计算时间大于3秒),分两种情况:进程数量少于空闲cpu数目、进程数量大于空闲cpu数目两种情况,比较一个进程完成时间,给出时间差别的解释。
首先分析第三步我们需要做的事情,首先需要父子进程并发执行,我们知道fork()产生的子进程和父进程就是并发执行的;而在需要完成的计算任务设计上,参考上学期的算法设计课程,选取一个较为耗时的算法即可,比如某种排序算法;我们知道在单处理器上,多进程并发就是实际上就是时间片的轮换利用,而这个轮换也是需要需要时间的,也就是我们的处理机资源只有一个,不能做到“真正的并发”,而在多处理器机器上,多任务的多进程并发优势可以得到很好的体现,因为可以将多个进程分配到不同的处理器上,从而可以提交运行效率,这应该也是为什么实验指导中需要我们考虑进程数量和空闲处理器的缘故。在对要求有了一定的了解后,下面开始此部分的实验。
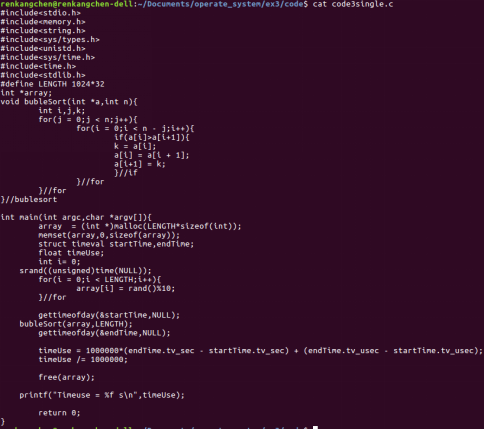
图15:code3single
图15展示了一个简单的排序程序,为了达到单个任务计算时间超过3s的要求,我们使用了较大的数据规模,并用了最简单也是效率最低的简单冒泡排序。

图16:code3single运行结果
图16展示了我们编写的code3single的运行时间结果,可以看到,程序完成1024*32个数据的排序,共用时约3.7s。
根据实验指导书的提示,我们将上面的代码修改为父进程创建一个子进程,然后父子进程完成相同计算任务的代码。
伪代码如下:
//code3.c
begin
pid = fork();
if pid == -1 then
return error;
else if pid == 0 then
sort();
else then
sort();
end
因为程序较为简单,就不展示完整的代码,code3.c和code3signal.c的区别仅仅在于,我们创建了一个子进程,并在父进程和子进程都进行了排序工作。
在运行code3前,查看cpu的使用情况:
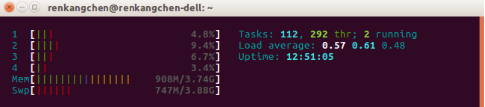
图17:CPU使用情况
我们通过htop工具来查看cpu的使用情况,可以看到,实验机器为4核处理器,且均未完全使用。
接着我们运行code3,也就是此时,空闲cpu数是多于我们的创建的进程数(父进程和子进程,两个)的。

图18:code3执行结果
code3的执行结果显示,不论是父进程还是子进程,执行和code3single同样的计算任务,时间差别并不是很大,当同时在两个终端下运行code3和code3single,两者得到的时间差更小。再来看看,如果我们的创建的进程数多余空闲的cpu数时,程序执行的情况。
可以通过减少空闲cpu数和增加进程的方法来满足实验要求的条件,我们先选择减少空闲的cpu数,即用其他的计算任务来占据空闲的CPU资源。
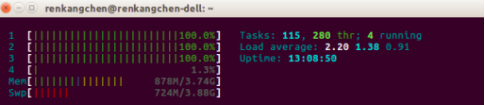
图19:CPU使用情况2
从图19可以看到,我们通过执行其他的计算任务,使得,空闲的cpu数为1,也就是图中看到的,1,2,3号均达到了100%的使用率,这时候,我们再执行code3,看看结果如何。

图20:code3执行结果2
从图20的结果来看,此时父进程和子进程的执行时间大概是图18展示的code3在cpu有较多空闲的情况下的执行时间的三倍。
我们再尝试增加进程数,比如增加到五个(超过空闲cpu数,4个)。这里为了增加结果的可靠性,我们并发执行五个子进程,它们完成相同的计算任务,而在父亲进程中,我们利用waitpid方法来进行阻塞,父亲进程在所有进程完成后,再进行子进程相同的计算任务。
//code3more.c
Begin
int pid1 = fork();
if pid1 == 0 then
sort();
exit();
int pid2 = fork();
if pid2 == 0 then
sort();
exit();
...
waitpid(pid1,NULL,0);
waitpid(pid2,NULL,0);
.....
sort();
End
code3more.c的伪代码如上,我们创建了五个子进程,它们会并发执行,多于空闲的cpu数4,而父进程等待子进程完成后,再完成计算任务,当然,此时进行我们计算的进程数(只有父进程)少于空闲CPU数。值得注意的是,我们没有让子进程和父进程并发,这里和题目要求略有差别

图21:code3more运行结果
如果我们让父子进程并发,即注释掉waitpid部分,运行结果如下:
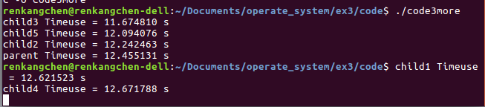
图22:code3more运行结果2
可以看出,和图21所示的结果相比较,最大的区别在于,父进程会出现先于子进程完成,子进程变成了孤儿进程,当然,这是我们不太希望看到的,所以,此处根据实际情况,只让几个子进程进行并发。
再来看图21的结果,和图18cpu空闲状态下,父子进程并发执行的时间相比,几个子进程耗费的时间均在9~10s大于图18中的4s。分析可能的原因是,当cpu空闲数较多的时候,我们的这几个计算进程不需要进行过多的进程调度,因而完成计算任务花费时间较少,和单个进程的时间几乎相同,而当我们的计算进程多于空闲cpu数时,发生了较多的进程调度,而进程调度是需要较大的时间开销的,所以,此时完成计算任务所需的时间就会多些。图20的结果也说明了这一点,图20的结果是在我们用其他计算任务占用cpu,使得空闲cpu数为1的时候得到的,此时会发生的调度会更多,因而时间开销也略会更大一些。
4父进程等待子进程完成(可以使用阻塞的wait()调用),观察记录父子进程的就绪和阻塞状态变化过程(用/proc查看进程的状态);
首先使用搜索引擎查阅wait()函数相关的知识。
#include<sys/types.h>
#include<sys/wait.h>
pid_t wait(int *status);
pid_t waitpid(pid_t pid,int * status,int options);
提到wait函数就不得不谈到waipid函数,从系统的角度看,两个函数的功能是一样的(只是waitpid多了两个供用户选择的参数),那就是分析当前进程的某个子进程是否已经退出,如果已经子进程退出,wait(或者waitpid)就会收集这个子进程的信息,并且把它销毁,然后返回,如果没有这样一个子进程,wait(或者waitpid)就会一直阻塞当前进程,直到出现一个这样的子进程。
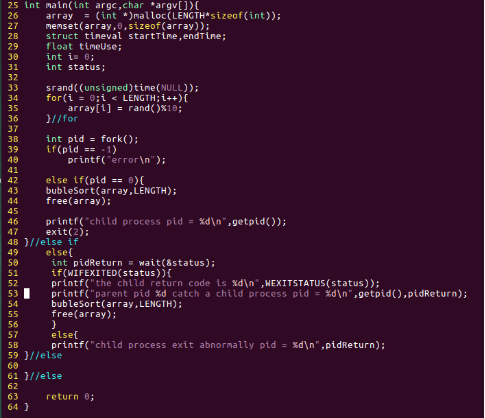
图23:code4.c代码片段
我们直接在code3.c的基础上,稍微了修改一下,用作本部分的实验代码,所以,仅仅给出主函数部分。在父进程中,调用wait()方法,阻塞父进程,此时父进程只有等待子进程完成后,才能就绪,执行。为了便于观察,我们让父进程在输出子进程返回信息后,继续执行一段计算代码。也就是说,我们看到父进程打印出了子进程的返回信息时,就知道子进程已近执行完毕,这时父进程应该不再是阻塞状态了。在子进程的退出时,返回2,在父进程中利用去得到子进程退出时的返回值。这里用到了两个宏,WIFEXITED(int status),当子进程正常退出("exit"或"_exit"),此宏返回非0;WEXITSTATUS(int status),获得子进程exit()返回的结束代码。

图24:code4执行结果1
从执行结果可以看到,父进程只有等到子进程执行完成后(获得了子进程退出时返回的结束代码),才能就绪,执行。

图25:code4 ps结果
我们可以在code4运行时候,使用ps命令简单地查看一下父子进程的状态,可以看到pid号为29270的进程(也就是父进程),是处于S状态的,而子进程正在运行。当然我们也可以通过/proc来查看进程的详细信息。
运行code4,然后使用命令cat /proc/[pid]/status来查看对应进程的状态信息。
这条命令会返回pid对应的进程(如果存在的话)的详细信息,这里整理处几个常用的信息。
| 参数 | 含义 |
| Name | 应用程序或命令的名字 |
| State | 任务的状态,运行/睡眠/僵死/ |
| Tgid | 线程组号 |
| Pid | 任务ID |
| Ppid | 父进程ID |
| VmRSS(KB) | 应用程序正在使用的物理内存的大小 |
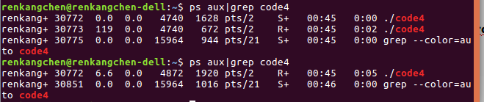
图26:code4执行2
我们利用ps命令来查看code4的进程号,这里也可以看到,在code4刚开始运行时,有两个进程,进程号分别为30772和30773,其中30772为我们的父进程,此时,它被wait()阻塞,所以是S状态,子进程30773正处于运行状态,等到子进程结束后,父进程结束阻塞状态,就绪,执行,所以,我们可以看到,此时,30772状态变为R。再来看看,由/proc得到的结果。
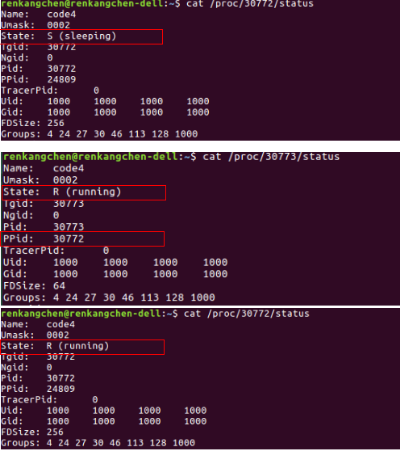
图27:code4 /proc状态查看结果
从图25可以看出,30772(父进程)刚开始处于S状态,而此时的子进程30773处于R状态,图中圈出,30773的Ppid,也就是是父进程pid为30772。而等到子进程执行完毕,再次查看30772的状态,可以看到,变为了R状态。
5父子进程执行不同的可执行文件(需要利用exec()调用),完成不同功能;
先查阅相关的资料。
Linux中并没有一个名为“exec”的函数,而是六个以exec开头的函数族,它们是:
| 头文件 | #include<unistd.h> |
| 函数原型 | int execl(const char *path, const char *arg, ...) |
| int execv(const char *path, char *const argv[]) | |
| int execle(const char *path, const char *arg, ..., char *const envp[]) | |
| int execve(const char *path, char *const argv[], char *const envp[]) | |
| int execlp(const char *file, const char *arg, ...) | |
| int execvp(const char *file, char *const argv[]) | |
| 返回值 | 成功:不返回 |
| 失败:返回-1 |
表中前四个函数以完整的文件路径进行文件查找,后两个以p结尾的函数,可以直接给出文件名,由系统从$PATH中指定的路径进行查找。这里不同的函数后缀,代表着的含义是:
| 后缀 | 含义 |
| l | 接收以逗号分隔的参数列表,列表以NULL指针作为结束标志 |
| v | 接收到一个以NULL结尾的字符串数组的指针 |
| p | 是一个以NULL结尾的字符串数组指针,函数可以通过$PATH变量查找文件 |
| e | 函数传递指定参数envp,允许改变子进程的环境,无后缀e时,子进程使用当前程序的环境 |
值得注意的是:这六个函数中真正的系统调用只有execve(),其他的都是库函数,它们最终都会调用到execve();exec函数常常会因为找不到文件,或者没有对应文件的运行权限等原因而执行失败,所以,在使用是最好加上错误判断语句。
fork()函数产生的子进程和父进程几乎一样,也就是父子进程完成相同的工作,而exec()函数则可以让子进程装入或运行其他的程序,也就是可以做和父进程不一样的事。根据对查阅的资料理解,结合前面部分的实验,得到本部分的实验代码:
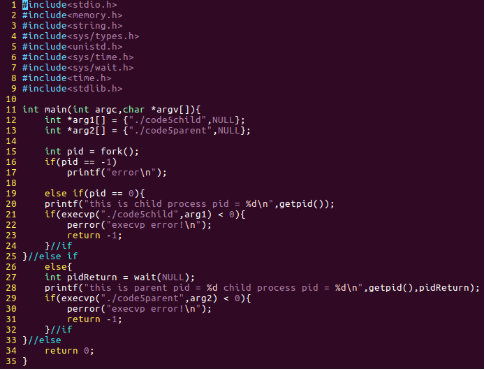
图28:code5.c代码片段
我们在子进程中调用了execvp()函数,根据前面的资料,这个函数的第一个参数就是我们调用的shell命令或者是要执行的文件;第二个参数表示这个函数希望接收一个
NULL结尾的字符串数组的指针,我们这里定义了char *arg1[] = {"./code5child", , NULL},char *arg2[] = {"./code5parent", , NULL};为了便于观察,我们使用wait()函数,使得子进程执行完毕,父进程再继续执行。
code5child,code5parent为两个我们的测试文件,它们的执行结果为:

图29:code5child,code5parent执行结果
编译运行code5

图30:code5:执行结果
从图27可以看到,我们让子进程执行了“./code5child”,打印了一句“this is child here!”;而父进程则没有做这项工作,它执行了“./code6parent”,打印了一句“this is parent here!”。可以看出,我们通过exec()函数调用来实现父子进程执行不同可执行文件的目的。
当然,我们也可以让子进程执行一条shell命令,比如下面的图28所示的结果:
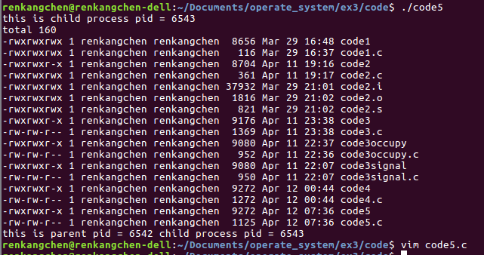
图31:子进程执行shell命令
6生成3层或以上的父子进程树,用/proc文件查看它们的父子关系。
当父进程调用fork()函数的时候,便创建了一个子进程,而父子进程是相对的,也就是子进程中再调用fork()时,子进程就创建了它自己的子进程,它是该子进程的父进程。
本部分的实验代码如下:
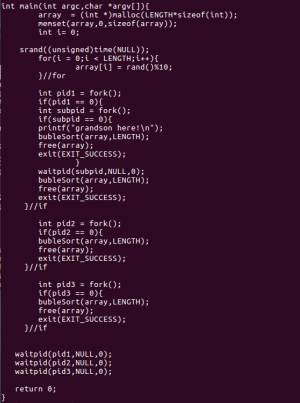
图32:code6.c代码片段
从图32的代码片段可以看出,我们在一个父进程下创建了三个子进程,pid1,pid2,pid3,然后,在pid1下,又创建了一个子进程subpid,它是pid1的子进程,父进程的“孙进程”。
我们先使用pstree命令来查看树状的进程关系。

图33:pstree得到的进程树
从图33的结果可知,我们创建了五个进程,21244有3个子进程,它们是21245,21246,和21248,而21247为21245的子进程。当然,我们也可以使用/proc来查看进程之间的父子关系,如图27中展示的那样。
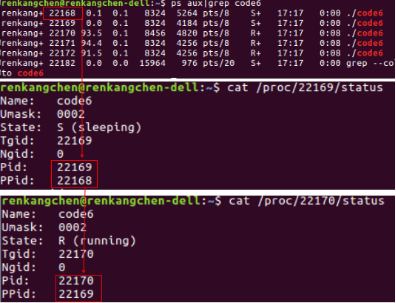
图34:/proc查看code6
从图34可以看出,22168为父进程,它是22169的父进程,22169又是22170的父进程(图中PPid表示父进程pid号的意思)。
实验源码:链接: https://pan.baidu.com/s/1kV7Jfq3 密码: itiz














 196
196











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









