







一:MNIST数据集的获取
1.获取MNIST数据集
cd data/mnist/
./get_mnist.sh
tree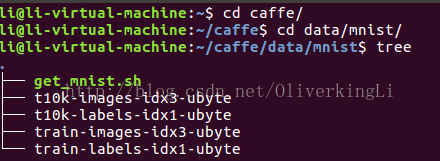
2.此时可以查看一下caffe下get_mnist.sh脚本的内容
#!/usr/bin/env sh
# This scripts downloads the mnist data and unzips it.
DIR="$( cd "$(dirname "$0")" ; pwd -P )"
cd "$DIR"
echo "Downloading..."
for fname in train-images-idx3-ubyte train-labels-idx1-ubyte t10k-images-idx3-ubyte t10k-labels-idx1-ubyte
do
if [ ! -e $fname ]; then
wget --no-check-certificate http://yann.lecun.com/exdb/mnist/${fname}.gz
gunzip ${fname}.gz
fi
done3.目前下载下来的是压缩形式的bin二进制文件,需要转换为LEVELDB或者LMDB形式才能被caffe所识别
执行:
./examples/mnist/create_mnist.sh
ls -l examples/mnist/mnist_train_lmdb/
ls -l examples/mnist/mnist_test_lmdb/examples/mnist/convert_mnist_data.cpp
二:跑lenet-5模型
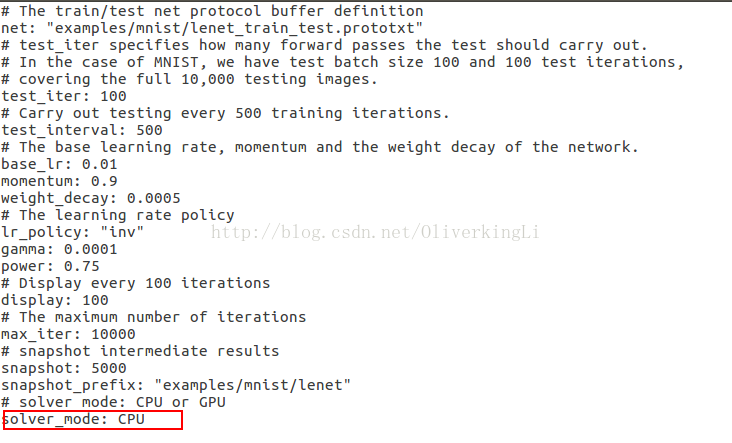
1.查看lenet-5模型描述文件
gedit examples/mnist/lenet_train_val.prototxt
gedit examples/mnist/lenet_solver.prototxt
执行:
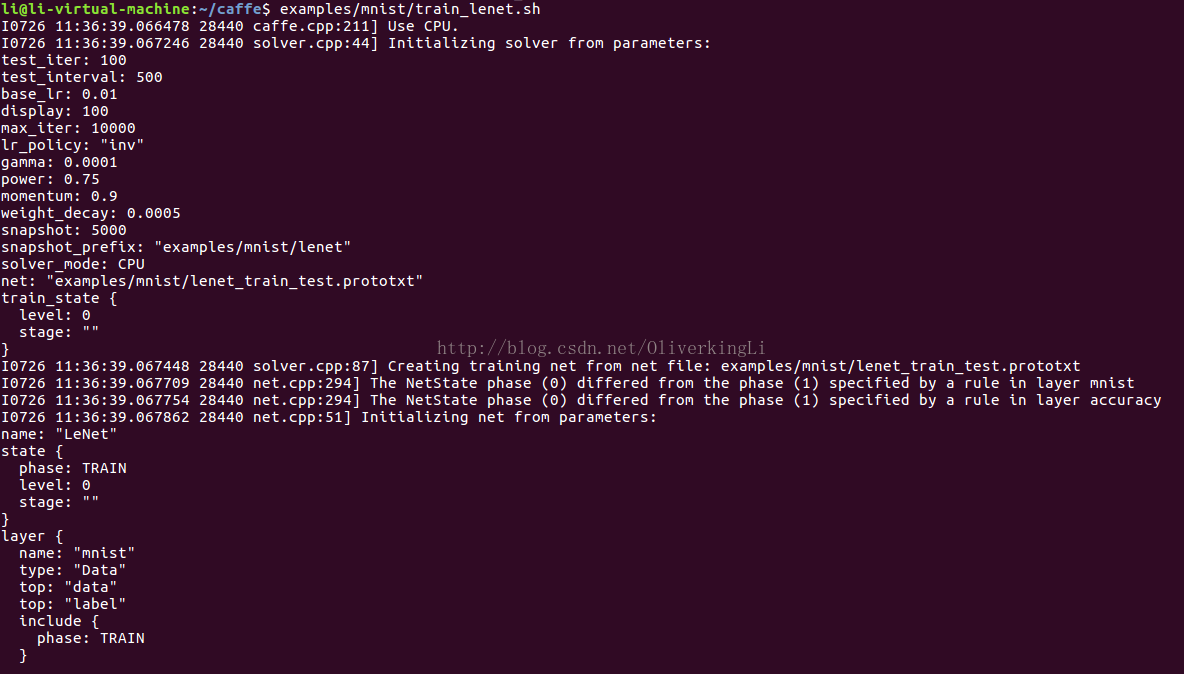
examples/mnist/train_lenet.sh
模型描述
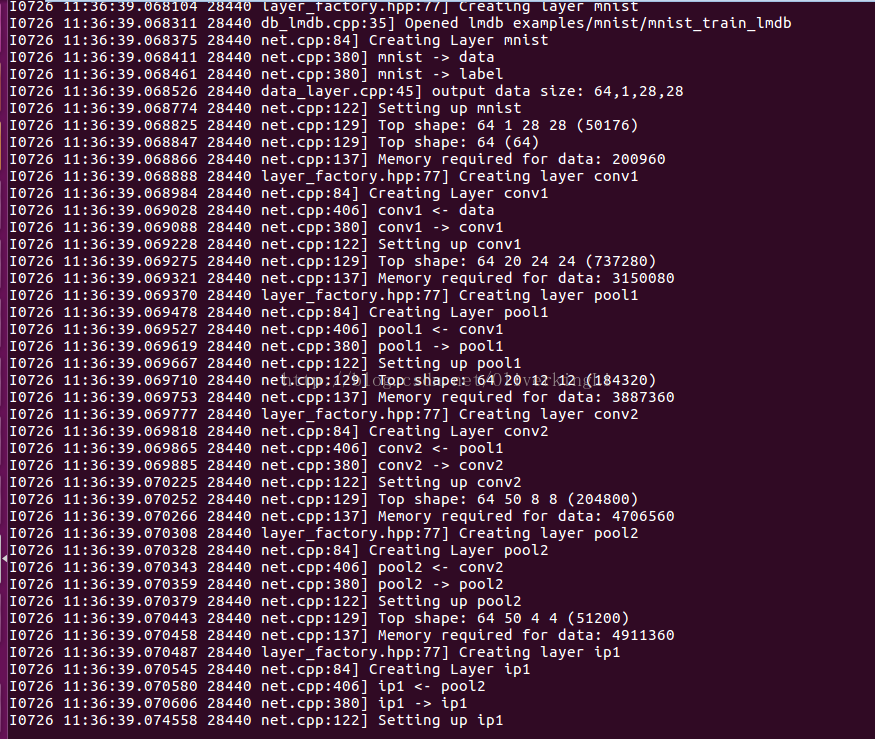
name: "LeNet"
state {
phase: TEST
}
layer {
name: "mnist"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST
}
transform_param {
scale: 0.00390625
}
data_param {
source: "examples/mnist/mnist_test_lmdb"
batch_size: 100
backend: LMDB
}
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 20
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "conv2"
type: "Convolution"
bottom: "pool1"
top: "conv2"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 50
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "pool2"
type: "Pooling"
bottom: "conv2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "ip1"
type: "InnerProduct"
bottom: "pool2"
top: "ip1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
inner_product_param {
num_output: 500
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "relu1"
type: "ReLU"
bottom: "ip1"
top: "ip1"
}
layer {
name: "ip2"
type: "InnerProduct"
bottom: "ip1"
top: "ip2"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
inner_product_param {
num_output: 10
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "accuracy"
type: "Accuracy"
bottom: "ip2"
bottom: "label"
top: "accuracy"
include {
phase: TEST
}
}
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "ip2"
bottom: "label"
top: "loss"
}
最终训练模型结果是保存在examples/mnist/lenet_iter_10000.caffemodel,训练状态保存在
examples/mnist/lenet_iter_10000.solverstate中,均是protobuffer二进制格式文件。
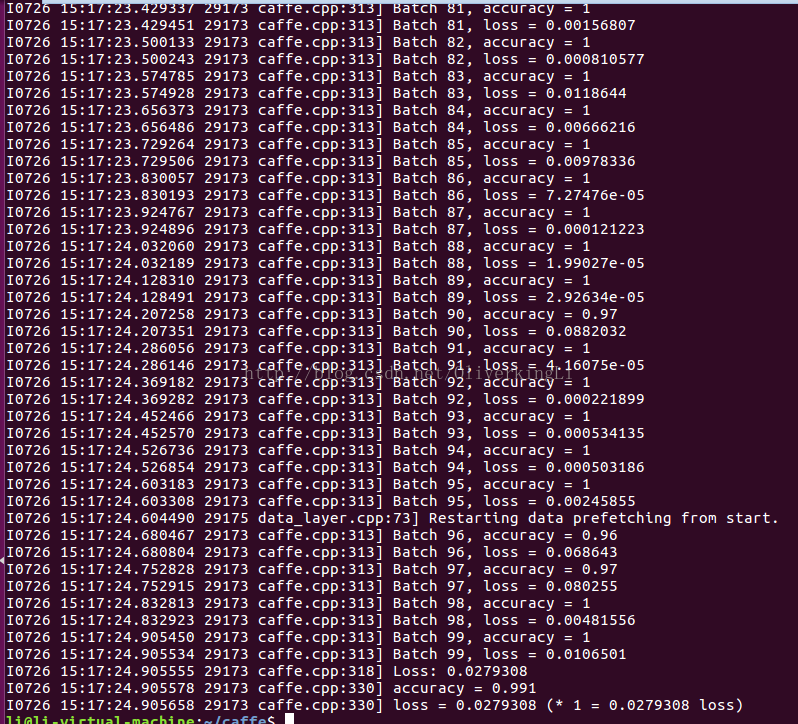
3.测试模型
./build/tools/caffe.bin test -model examples/mnist/lenet_train_test.prototxt -weights examples/mnist/lenet_iter_10000.caffemodel -iterations 100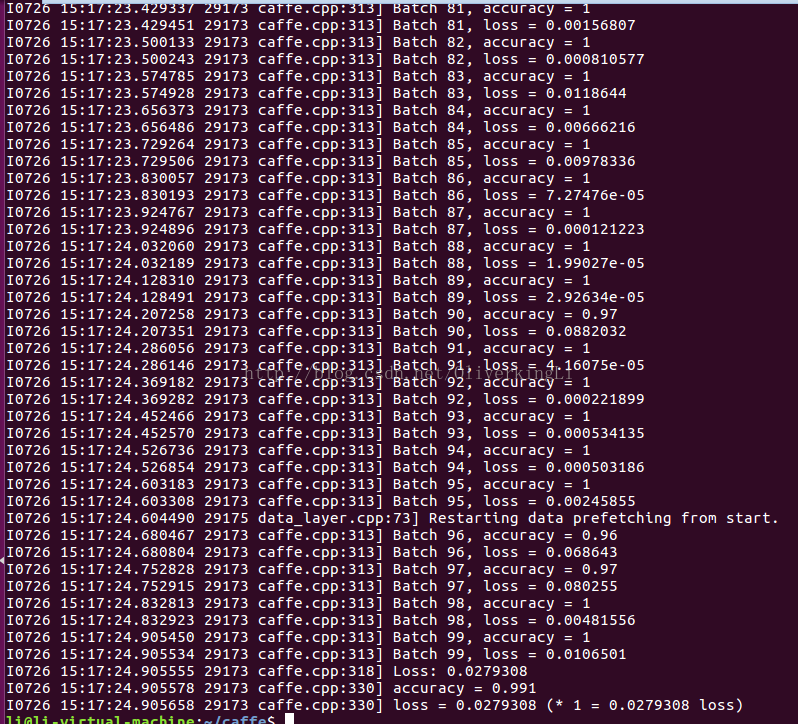














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









