






前两课都是铺垫,终于来到正题。
先说的数据并行性,这个概念对所有并行计算开发都是非常有用的。
应用程序可以使用两种(或者其中一种)基本形式,在这里被称作“数据并行”和“处理并行”。数据并行指同时对许多数据对象执行相似的计算。这种并行的原型(尤其对于计算科学应用)是对一个数组的所有元素同时进行操作——例如,用一个给定值去除数组的每个元素(比如在矩阵归约时将主元行基准化)
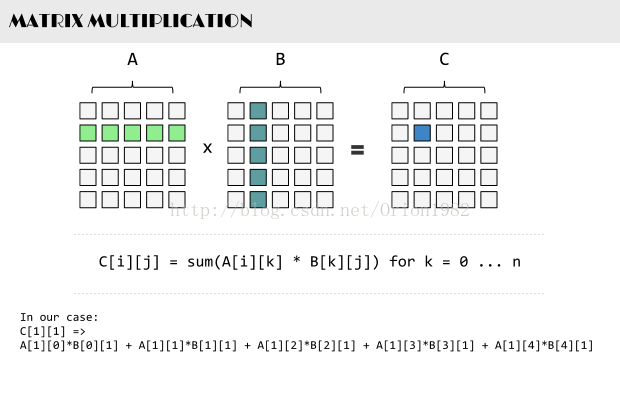
书中提到一个矩阵相乘的例子,也就点积运算,用它来帮助理解数据并行性。
复习一下线代的知识:
点积 :指 数量积 (也称为 标量积 、 点积 、 点乘 或 内积 )是接受在实数 R 上的两个 向量 并返回一个实数值 标量 的 二元运算 。它是 欧几里得空间 的标准 内积 。
--------------------
定义:
点积:
CUDA 6 Code with Unified Memory ( 简化的内存管理代码)
顺便提一下,下代GPU Maxwell将会支持统一虚拟内存,但它要到2015年才会发布。
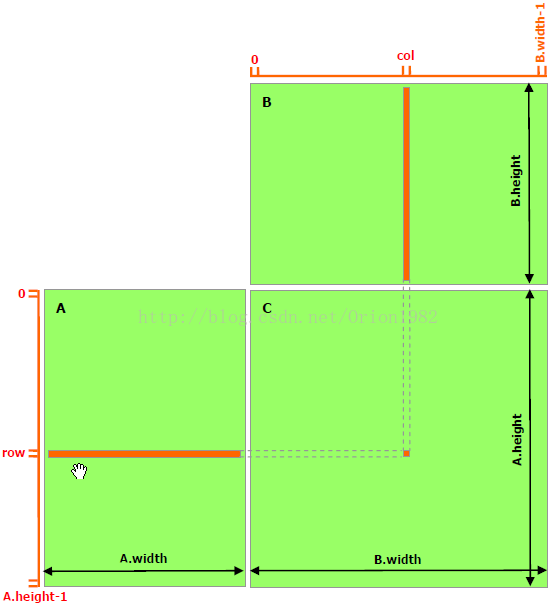
矩阵乘法示例,先把CPU 那断代码拿过来看一下,很简单三层循环,主要是找到数据并行部分,用来提取Kernel函数。
设备存储器和数据传输
CUDA 使用的内存分配函数是 cudaMalloc() 当然它是在设备上开辟内存,cudaMalloc() 有两个参数一个是输出参数 分配后的地址(要注意的是必需要使用 void **,因为返回的是泛型指针),一个是需要分配的大小,还有一个反回值用来标记成功和失败。使用cudaFree() 来释放设备上的内存空间, cudaFree() 接收一个地址参数。
先说的数据并行性,这个概念对所有并行计算开发都是非常有用的。
应用程序可以使用两种(或者其中一种)基本形式,在这里被称作“数据并行”和“处理并行”。数据并行指同时对许多数据对象执行相似的计算。这种并行的原型(尤其对于计算科学应用)是对一个数组的所有元素同时进行操作——例如,用一个给定值去除数组的每个元素(比如在矩阵归约时将主元行基准化)
书中提到一个矩阵相乘的例子,也就点积运算,用它来帮助理解数据并行性。
复习一下线代的知识:
点积 :指 数量积 (也称为 标量积 、 点积 、 点乘 或 内积 )是接受在实数 R 上的两个 向量 并返回一个实数值 标量 的 二元运算 。它是 欧几里得空间 的标准 内积 。
--------------------
定义:
点积:
两个(来自正交规范向量空间)向量 a = [a1, a2, … , an] 和 b = [b1, b2, … , bn] 的点积定义为:
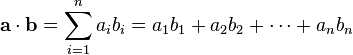
这里的 Σ 指示总和符号。
例如,两个三维向量 [1, 3, ?5] 和 [4, ?2, ?1] 的点积是

使用矩阵乘法并把(纵列)向量当作 n×1 矩阵,点积还可以写为:

这里的 aT 指示矩阵 a 的转置。
使用上面的例子,这将结果一个 1×3 矩阵(就是行向量)乘以 3×1 向量(通过矩阵乘法的优势得到 1×1 矩阵也就是标量):
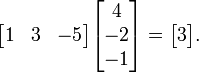
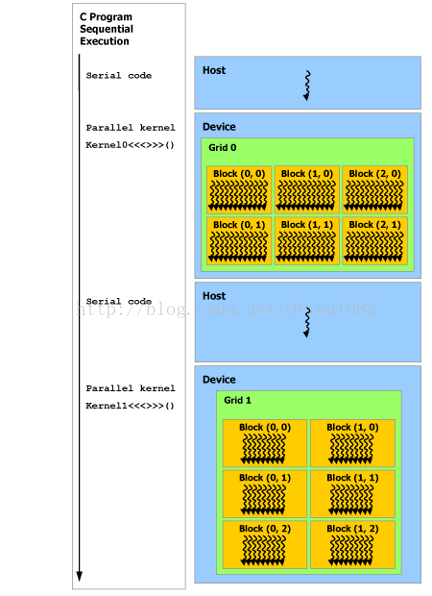
CUDA 的程序结构,是分阶段执行,分为主机阶段和设备阶段,交替执行。
编译器是NVIDIA 研发的 nvcc ,主机阶段是 标准ANSI C ,设备阶段是ANSI C扩展语言编写。
设备阶段执行的是Kernel 函数,Kernel函数通常会产生大量的轻量级线程来利用数据并行性。
CPU Code
void sortfile(FILE *fp, int N){
char *data;
data = (char *)malloc(N);
fread(data, 1, N, fp);
qsort(data, N, 1, compare);
use_data(data);
free(data);
}CUDA 6 Code with Unified Memory ( 简化的内存管理代码)
void sorfile(FILE *fp, int N){
char *data;
cudaMallocManaged(&data, N);
fread(data, 1, N, fp);
qsort<<<...>>>(data, N, 1, compare);
cudaDeviceSynchronize();
use_data(data);
cudaFree(data);
}顺便提一下,下代GPU Maxwell将会支持统一虚拟内存,但它要到2015年才会发布。
矩阵乘法示例,先把CPU 那断代码拿过来看一下,很简单三层循环,主要是找到数据并行部分,用来提取Kernel函数。
void MatrixMultiplication(float* M, float* N, float* P, int Width)
{
for (int i = 0; i < Width; ++i)
for(int j = 0; j < Width; ++j) {
float sum = 0;
for (int k = 0; k < Width; ++k) {
float a = M[i * Width + k];
float b = N[k * Width +j];
sum += a * b;
}
P[i * Width + j] = sum;
}
}设备存储器和数据传输
CUDA 使用的内存分配函数是 cudaMalloc() 当然它是在设备上开辟内存,cudaMalloc() 有两个参数一个是输出参数 分配后的地址(要注意的是必需要使用 void **,因为返回的是泛型指针),一个是需要分配的大小,还有一个反回值用来标记成功和失败。使用cudaFree() 来释放设备上的内存空间, cudaFree() 接收一个地址参数。
float *Md;
int size = Width * Width * sizeof(float);
cudaMalloc((void**)&Md, size);
...
cudaFree(Md);
cudaMemcpy(Md, M, size, cudaMemcpyHostToDevice);
cudaMemcpy(P, Pd, sixe, cudaMemcpyDeviceToHost);Kernel 函数与线程, CUDA 采用的是SPMD,单程序多数据,声明Kernel需要使用关键字 。一个表说明所有问题。
函数名 | 执行位置 | 只能从哪里调用 |
| __device__ floatDeviceFunc() | 设备 | 设备 |
| __global__ void KernelFunc() | 设备 | 主机 |
| __host__ float HostFunc() | 主机 | 主机 |
网格和块是用于管理线程的一种方式。一个Kernel 函数对应一个Grid,一个Grid 包含多个块,块可以是二维的或三维的。
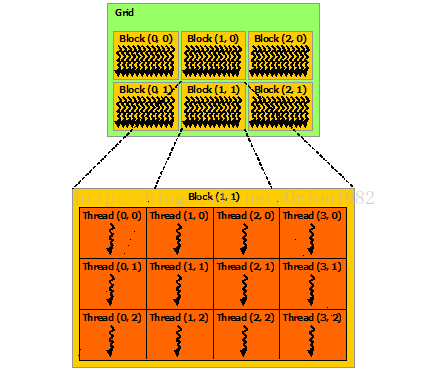
通过声明 dim3 类型的struct 变量,来分配网格和块的维度。
// 设置对应的执行配置参数
dim3 dimBlock(Width, Width);
dim3 dimGrid(1, 1);
// 启动在设备上进行计算的线程
MatrixMulKernel<<<dimGrid, dimBlock>>>(Md, Nd, Pd, Width);














 634
634











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









