







参考
场景
一、上一篇博客将待分析数据影射成JavaBean的字段,然后通过def createDataFrame(data:java.util.List[_],beanClass:Class[_]):DataFrame完成了RDD与DataFrame的转换(即:Inferring the Schema Using Reflection);今天换一种实现方式-Programmatically Specifying the Schema:构建StructType,通过def createDataFrame(rowRDD: RDD[Row], schema: StructType): DataFrame以完成RDD与DataFrame的转换!
二、Programmatically Specifying the Schema
“When case classes cannot be defined ahead of time (for example, the structure of records is encoded in a string, or a text dataset will be parsed and fields will be projected differently for different users), a DataFrame can be created programmatically with three steps.
1、 Create an RDD of Rows from the original RDD;
2、 Create the schema represented by a StructType matching the structure of Rows in the RDD created in Step 1.
3、Apply the schema to the RDD of Rows via createDataFrame method provided by SQLContext.”
实验
java版
package cool.pengych.spark.sql;
import java.util.ArrayList;
import java.util.List;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.sql.DataFrame;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.SQLContext;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.StructField;
import org.apache.spark.sql.types.StructType;
public class RDD2DataFrameProgrammatically
{
public static void main(String[] args)
{
/*
* 1、创建SQLContext
*/
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("RDD2DataFrameByReflection");
JavaSparkContext sc = new JavaSparkContext(conf);
SQLContext sqlContext = new SQLContext(sc);
/*
* 2、在RDD的基础上创建类型为Row的RDD
*/
JavaRDD<String> lines = sc.textFile("file:home/pengyucheng/java/rdd2dfram.txt");
JavaRDD<Row> rows = lines.map(new Function<String, Row>() {
private static final long serialVersionUID = 1L;
@Override
public Row call(String line)
{
String[] splited = line.split(",");
return RowFactory.create(Integer.valueOf(splited[0]),splited[1],Integer.valueOf(splited[2]));
}
});
/*
* 3、动态构造DataFrame的元数据,一般而言,有多少列以及每列的具体类型可能来自于
* Json文件,也可能来自于DB
*/
List<StructField> structFields = new ArrayList<StructField>();
structFields.add(DataTypes.createStructField("id", DataTypes.IntegerType, true));
structFields.add(DataTypes.createStructField("name", DataTypes.StringType, true));
structFields.add(DataTypes.createStructField("age", DataTypes.IntegerType, true));
StructType structType = DataTypes.createStructType(structFields);
/*
* 4、基于以后的MetaData以及RDD<Row>来构造DataFrame
*/
DataFrame personDF = sqlContext.createDataFrame(rows, structType);
/*
* 5、注册临时表供以后SQL使用
*/
personDF.registerTempTable("persons");
/*
* 6、进行数据的多维度分析
*/
DataFrame results = sqlContext.sql("select * from persons where age > 8");
/*
* 7、由DataFrame转换成为RDD
*/
List<Row> listRows = results.javaRDD().collect();
for (Row row : listRows)
{
System.out.println(row);
}
}
}scala版
package main.scala
import org.apache.spark.SparkConf
import org.apache.spark.sql.SQLContext
import org.apache.spark.SparkContext
import org.apache.spark.sql.RowFactory
import org.apache.spark.sql.types.StructField
import java.util.ArrayList
import org.apache.spark.sql.types.DataTypes
object RDD2DataFrameProgrammatically
{
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("DataFram Ops")
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
val lines = sc.textFile("file:home/pengyucheng/java/rdd2dfram.txt")
val rowsRDD = lines.map(line => {
val splited = line.split(",")
val row = RowFactory.create(Integer.valueOf(splited(0)),splited(1),Integer.valueOf(splited(2)))
row
})
val structFields = new ArrayList[StructField]()
structFields.add(DataTypes.createStructField("id", DataTypes.IntegerType, true));
structFields.add(DataTypes.createStructField("name", DataTypes.StringType, true));
structFields.add(DataTypes.createStructField("age", DataTypes.IntegerType, true));
val structType = DataTypes.createStructType(structFields)
val personDf = sqlContext.createDataFrame(rowsRDD, structType)
personDf.registerTempTable("persons")
sqlContext.sql("select * from persons where age > 8").rdd.collect.foreach(println)
}
}执行结果
16/05/26 21:28:20 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
[1,hadoop,11]
[4,ivy,27]
16/05/26 21:28:20 INFO SparkContext: Invoking stop() from shutdown hook总结
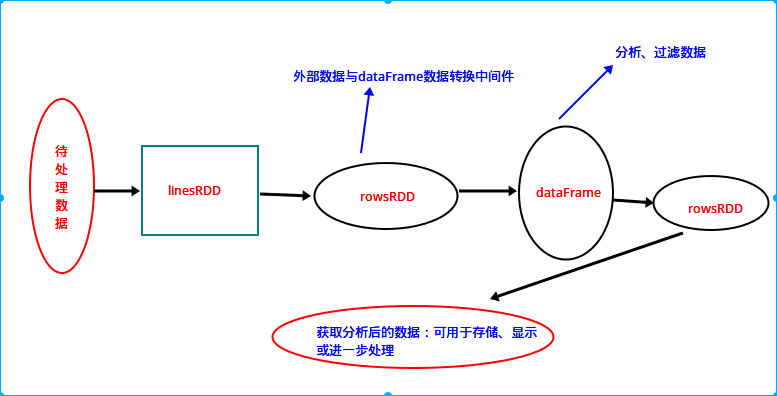
Spark DataFrame处理数据流程图(纯属个人总结,准备性有待后续验证)














 3118
3118











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









