









前面的章节已经介绍了提取文本行的方法。本文主要介绍传统的依赖over segmentation过分割,beam search和字符分类器的识别方法。主要参考文献[1]和opencv contribute中text module中的代码[5]。一般情况下我们会通过二值化,投影、连通域分割,分类器判别这套程序来做文字识别,但是一方面二值化现在还没有一统江湖的方法,另一方面就算某些情况下二值化做的很好,如果有些字连起来,或者像中文单词中这种有偏旁部首的,分割也不是非常好解决。因此,研究人员就提出了过分割。
一过分割
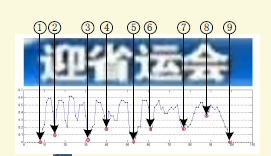
图片摘自参考文献[3]
如上图,核心思想就是过量分割,一个可能只有几个字的图片,我们可以割10刀,20刀,甚至100刀,当然要尽量把真正的分割点包含在其中,然后可以靠beam search来选择最合适的分割组合(下面介绍)。过分割的想法很简单,但是怎么得到过分割点呢?不同的论文中可能采用不同的方法。
如文献[3]用的是一个double edge相关的特征来进行二值化,文献[1]用的是滑窗加二分类器,opencv中用的是滑窗加多分类器,如果某个窗口是个字或者是某个字的概率很大,那么就作为一个潜在的分割点。接下来就是要想方法选择一个合适的分割组合。
二分割评分算法
在进行beam search搜索最优分割组合之前呢,我们需要先知道怎么定义和计算一个分割组合的评分。这里我们挑选opencv中用的滑窗加多分类器的方法来讲解。首先我们有一个英文单词文本行,然后定义一个滑窗,滑窗有两个重要的参数,窗口大小和滑动歩距,窗口的高度一般跟文本行高度一致(比如说是32*32),歩距比如说5个像素(文献1采用的是文本行高度的十分之一),那么Rect(x:0,y:0,width:32,height:32),Rect(5,0,32,32),Rect(10,0,32,32)..就是一些待评估的窗口,每隔一个歩距5就是一个潜在的分割点。如下图,图示中窗口选的稍微有点大,但是意思是差不多的(博主比较懒,不想再画了)。

滑动窗口示意图[6]
接着我们要有已经训练好的一个分类器,输入是一个窗口的图像,输出的是每一个类别的概率,比如a的概率是多少,b的概率是多少,其他类别的概率是多少。文献[1]用的是HOG+ANN,opencv[5]用的是单层CNN[7].
这样呢一个直观的感觉就是选取每一个窗口里面最大的概率求平均,比如一个文本行做了两次分割,那么就有三个窗口,第一个窗口是最大概率的类别是b,概率是0.3,第二个窗口是1的0.2,第三个窗口是s的0.4,那么这样子这个分割的分数就是3个概率的平均值0.3.但是这样有一个缺陷是没有考虑上下文关系,比如前面的例子中,第一个如果是b,虽然第二个的1的概率最大,但是1和l有时候很像,现实中b和l一起出现的概率也比b和1的概率高,所以第二个窗口的类别更有可能是1.那怎么处理这种情况呢?我们在分数里加入转移概率,下图中截取opencv中统计的62个类别(小写字母+大写字母+数字)转移概率
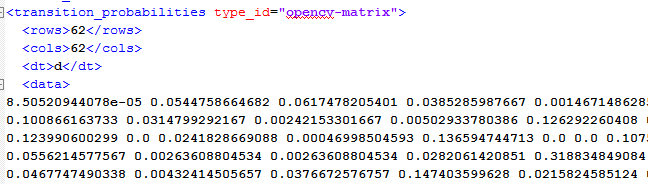
当加入转移概率后,分割的分数计算就会变得相对复杂,这就需要维特比算法[2](Viterbi algorithm),在本人转载的HMM帖子中有些涉及,主要是动态规划的想法,这里不再'赘述',附上opencv的代码作为参考
double score_segmentation(vector<int> &segmentation, string& outstring )
{
// Score Heuristics:
// No need to use Viterbi to know agiven segmentation is bad
// e.g.: in some cases we discard asegmentation because it includes a very large character
// in other cases we do it because the overlapping between two chars is toolarge
// TODO Add more heuristics (e.g. penalize large inter-character variance)
Mat interdist((int)segmentation.size()-1, 1, CV_32F, 1);
for (size_t i=0;i<segmentation.size()-1; i++)
{
interdist.at<float>((int)i,0) =(float)oversegmentation[segmentation[(int)i+1]]*step_size
-(float)oversegmentation[segmentation[(int)i]]*step_size;
if((float)interdist.at<float>((int)i,0)/win_size > 2.25) // TODO explainhow did you set this thrs
{
return -DBL_MAX;
}
if((float)interdist.at<float>((int)i,0)/win_size < 0.15) // TODO explainhow did you set this thrs
{
return -DBL_MAX;
}
}
Scalar m, std;
meanStdDev(interdist, m, std);
//double interdist_std = std[0];
//TODO Extracting start probs fromlexicon (if we have it) may boost accuracy!
vector<double>start_p(vocabulary.size());
for (int i=0;i<(int)vocabulary.size(); i++)
start_p[i] =log(1.0/vocabulary.size());
Mat V =Mat::ones((int)segmentation.size(),(int)vocabulary.size(),CV_64FC1);
V = V * -DBL_MAX;
vector<string>path(vocabulary.size());
// Initialize base cases (t == 0)
for (int i=0;i<(int)vocabulary.size(); i++)
{
V.at<double>(0,i) =start_p[i] + recognition_probabilities[segmentation[0]][i];
path[i] = vocabulary.at(i);
}
// Run Viterbi for t > 0
for (int t=1;t<(int)segmentation.size(); t++)
{
vector<string>newpath(vocabulary.size());
for (int i=0;i<(int)vocabulary.size(); i++)
{
double max_prob = -DBL_MAX;
int best_idx = 0;
for (int j=0;j<(int)vocabulary.size(); j++)
{
double prob =V.at<double>(t-1,j) + transition_p.at<double>(j,i) +recognition_probabilities[segmentation[t]][i];
if ( prob > max_prob)
{
max_prob = prob;
best_idx = j;
}
}
V.at<double>(t,i) =max_prob;
newpath[i] = path[best_idx] +vocabulary.at(i);
}
// Don't need to remember the oldpaths
path.swap(newpath);
}
double max_prob = -DBL_MAX;
int best_idx = 0;
for (int i=0;i<(int)vocabulary.size(); i++)
{
double prob =V.at<double>((int)segmentation.size()-1,i);
if ( prob > max_prob)
{
max_prob = prob;
best_idx = i;
}
}
outstring = path[best_idx];
return (max_prob /(segmentation.size()-1));
}
}
三 Beam search
opencv中第一步做的就是最大值抑制(NMS),如果邻近的框有重合,且判别的是同一个类别,那么较小概率的那个被抑制,然后在从合适的潜在分割点中找到最优的分割组合。从上面的分析知道,如果潜在分割点有10个,那么分割的组合大概有2^10= 1024种,那么搜索的空间还是比较大的。Beam sarch就是在宽度搜索的基础了做了一些剪枝。
比如我们设最大的beam为10,
(1)那么最开始的时候我们把所有的分割数是1的集合加入候选解中
{{分割点1},{分割点2},{分割点3},…,{分割点10}}
(2)候选解按分数从大到小排列,如果候选解超过beam的大小,就删掉末尾的
(3)加入新的分割点形成候选解带有2个分割点的解
{
{分割点1},{分割点2},{分割点3},…,{分割点10},
{分割点1,分割点2},{分割点1,分割点3},…,{分割点1,分割点10},
{分割点2,分割点3},{分割点2,分割点4},…,{分割点2,分割点10},
…
{分割点9,分割点10}
}
(4)候选解按分数从大到小排列,如果候选解超过beam的大小,就删掉末尾的
迭代,直到“遍历”到候选解带有10个分割点的出现,然后分数最大的就是我们想要的分割点。
本文就讲到这,错误与疏漏还请批评和指正。
参考文献
[1]Bissacco A, Cummins M,Netzer Y, et al. Photoocr: Reading text in uncontrolledconditions[C]//Proceedings of the IEEE International Conference on ComputerVision. 2013: 785-792.
[2]统计学习方法[M].清华大学出版社, 2012.
[3]Bai, Jinfeng, et al."Chinese image text recognition on grayscale pixels." Acoustics,Speech and Signal Processing (ICASSP), 2014 IEEE International Conference on.IEEE, 2014.
[4]Xiangyun Ye,M. Cheriet, andC.Y. Suen, “Stroke-model-based character extraction from gray-level documentimages,” Image Processing, IEEE Transactions on, vol. 10, no. 8, pp. 1152 –
1161, aug 2001.
[5]Opencv text module: https://github.com/Itseez/opencv_contrib/tree/master/modules/text
[6]He, Pan, et al."Reading scene text in deep convolutional sequences." arXiv preprintarXiv:1506.04395 (2015).
[7]Coates, Adam, Andrew Y. Ng,and Honglak Lee. "An analysis of single-layer networks in unsupervisedfeature learning." International conference on artificial intelligence andstatistics. 2011.














 1150
1150











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









