







这里主要记录阅读NIPS 2016 Tutorial: Generative Adversarial Networks[1][视频]的一些笔记,还没有很好的理解
导语
GAN应该是这两年深度学习最火热的技术了,虽然不研究这块,但是看看应该没多大坏处。它有很多非常有意思的应用。比如在[4]中的一个应用是我比较喜欢的,就是画画[youtube]
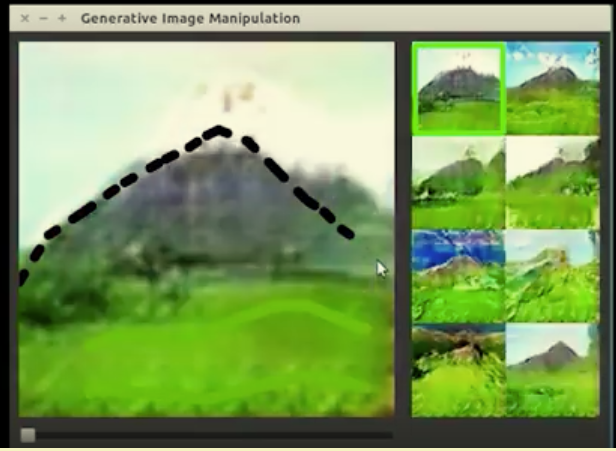
首先第一步我们在底下画了几条绿线,然后系统就会生成一堆带有草的图片,然后第二步我们在上面画了一个黑色的倒三角,系统就会在那部分生成类似一座山的图片
当然还有其他的一些好玩的应用,通过分割图像仿真实际图像,通过素描仿真真实图像等

1 生成模型
GAN属于生成模型,所以得先搞清楚什么是生成模型。监督学习可以细分为判别模型和生成模型。通俗地讲,比如我有一堆猫狗的图片,我要对他们进行分类,判别的模型只是要找到猫狗的差异就可以,比如说狗的体型要大些,所以看到体型大的我都认为是狗;而生成模型是通过学习猫是什么样的,狗是什么样的,它有能力生成新的一张新的猫或狗的图片,就和小孩画画差不多,如果都有这能力了自然会判别什么是猫,什么是狗(但是天下没有免费的午餐,根据研究和实验,在分类问题上,判别模型一般比生成模型做得好[2],因为不一定能画得好啊)。数学上比较形象地讲,判别模型是对P(y|x)进行建模,生成模型对P(x,y)进行建模。但是根据GAN这篇论文,生成模型其实又可以细分,一种是能显式对P(x,y)建模的,另外一种是只能从样本中生成新的样本的。GAN属于后者,当然作者也说了也有可能把GAN设计成前者。
2 为什么研究生成模型
Gan主要是用来生成一些全新的图像,但是在大数据互联网的时代,我们应该是不缺少数据的,为什么还要来研究生成模型呢?
根据作者的理解,有以下几条
1训练生成模型和从生成模型的抽样是一个很好的评估了我们表达(represent)和操作(manipulate)高维概率分布的能力。(翻译的比较拗口,主要是本人不是特别理解。感觉作者把这个定位成有点类似于尖端科技,你能登录火星,也就代表了你在航天这个领域很牛掰了)
2生成模型能以不同的方式融入到强化学习中。第一个是你可以通过生成模型来仿真环境,以此来训练RL,而不需要真正去造出这么一个环境,第二个可以并行处理,你可以生成多个这样的环境,并且训练中的一些错误不会导致真实的损害。这个核心意思应该是模拟环境,比如现在用去训练无人驾驶汽车,你可以去实际中去测试,但是你必须放个司机在上面,而生成模型可以虚拟这些环境,还会带有一些随机性
3可以用于半监督学习中,半监督学习通俗点讲呢,就是有一大堆数据,只有少部分有标注信息,这种数据集上面的训练叫半监督学习
3 其他生成模型
为了弄清楚GAN的精华,我们得对比一下其他的生成模型,作者主要对比了一下在最大似然底下的分支
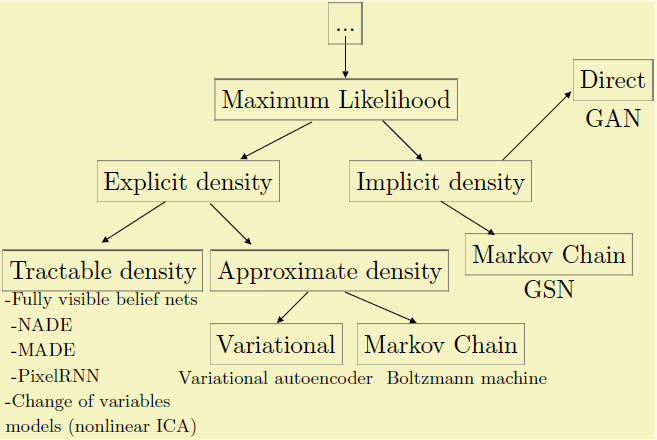
3.1 PixelRNN
tractable density在这个分支底下是有显式的概率密度函数,并且易解析的(翻译可能有问题)。我们来分析其中一个比较新的算法,就是pixelRNN[5],它是ICML2016最佳论文,出自于deepmind。
上面也已经提到了,生成模型可以用来生成新的图片,比如我要生成类似mnist那种28*28的数字图片,那我能想到的最简单的方案就是先生成第一个像素,然后看第一个像素是啥,再生成第二个像素,接着这样一直生成28*28个像素,其实也就是概率论中的条件概率的链式法则
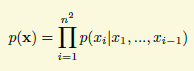
这篇论文的思想也就是这个,非常清楚易懂。(这个小节下面的内容不影响GAN其他部分的理解,不想看的可以直接跳过)
当然最佳论文不是这么好当的,论文提出了三种结构,当然像我这种没菜鸟看了几遍之后还是不太清楚为啥能得最佳论文。应该也是自己没理解到位,所以先把自己理解到的东西跟大家交流,然后希望能有些讨论加深理解。
3.1.1 PixelCNN
对这种高维概率分布的建模作者还是想用CNN深度学习,最简单的方法就是直接用CNN,所以就有了论文的pixelCNN.
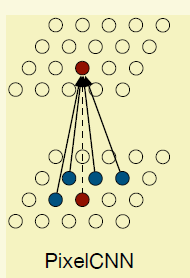
要生成当前点就对其周围的点进行卷积,学习filter,最后用个crossentropy loss进行梯度反馈。但是这个方法在训练的时候是可以的,在测试的时候因为还没产生下三角的像素,所以以当前位置的普通卷积行不通,所以论文搞了一个mask conv,例如5*5的卷积(白色部分是1,黑色部分是0),学到的filter还得跟这个mask进行点位相乘,mask有两种,主要区别在于在多通道图像中,需不需要把当前点前面通道的值考虑上,比如是按RGB生成的,那么G要不要依赖于R是这两种mask的区别。
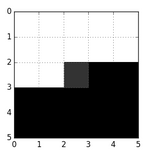
这种速度是最快的,但是这个有些问题。按照链式法则,当前的点是跟前面所有的点都有依赖,但是卷积网络的依赖主要靠感受野,而要增加感受野只能靠加深网络架构或者增大卷积核,这样一方面呢是增加训练的难度,另外一个方面是感受野一般也不像理论上那么大[7],跟激活函数什么的都有关系。
3.1.2 Row LSTM
所以呢就很自然的过渡到需要显式添加上下文依赖,这就到了LSTM出场。LSTM部分可以参考网上比较好的博客或者本人的另外一篇博客[8],当然这篇论文使用LSTM的方式是我比较喜欢的,跟普通的不太一样,后面会提到。作者首先提出了第一种架构Row LSTM,提出这个的另外一个初衷应该是如果按照链式法则一个一个的训练太慢了,作者想一行一行并行地训练。
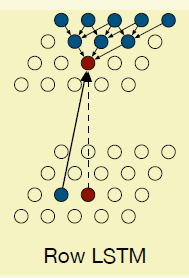
Row LSTM跟pixelCNN的差别是卷积的操作对象不再是普通的Feature map,而是LSTM的输出,这样就有显 式的上下文依赖关系。另外卷积的范围不再是一个上三角,而是一个行卷积(1*3,列在前),并且行卷积操作在当前点的上一行并以其为中心的一定范围内,比如行卷积是3*1,当前点的坐标是(x,y),那么卷积的对象是(hx-1,y-1),(hx,y-1),(hx+1,y-1), h是lstm输出的结果
现在我们来稍微探讨一下里面的LSTM。LSTM一般会有几个门,input gate,forget gate, output gate ,这些门在普通的LSTM里面一般都是以全连接这么个形式存在,只跟feature map当前的点有关(当然通过h会间接地跟上一时刻的输入有关系),但在pixelRNN里面,这些门都由卷积产生,因此会有上下文依赖关系,个人感觉也更加合理。另外这里多了一个content gate (g)。如下面的公式,i表示的行号,KSS,Kis都是卷积核

3.1.3 Diagonal BiLSTM
可能已经有人已经发现了Row LSTM存在pixelCNN类似的问题。就算pixelCNN加了显式的LSTM上下是依赖,它的依赖区域还是个漏斗形状,没有把所有的信息囊括进来,所以作者又提了Diagnoal BiLSTM这么一种架构,如下图,它的显式依赖关系就是我们所需要的最完美的情况。
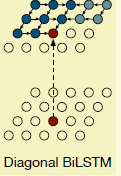
怎么做到的呢,如下图,右图中的白线我也看不懂,不用纠结。意思就是对于一个feature map,我们把每一行向右移动i格(起始行为0),第0行移动0格,第1行移动1格,然后LSTM中Kss是个1*2的列卷积,就是当前的点(x,y)跟(x,y-1),(x-1,y)两个有关系,也就是左图的意思,然后将feature map左右翻转,再做一个LSTM构成BiLSTM。当然在flip的过程中,如果只是简单的叠加,那么当前的点的生成会依赖于当前行右边还未生成的点,所有在做完反向LSTM的时候,会把整个反向LSTM的输出向下移动一行,再跟正向的进行叠加。

总结一下呢,本文主要有3个tricks,
1 有门路控制的CNN
2 两种架构消除盲点
3 深度网络使用残差结构(这个本文就不提了)
但是它的本质还是序列化的生成像素,导致速度比较慢,另外生成的图片没有GAN清晰。
大家也可以看看知乎这个问答,比较了一下GAN和pixelRNN的优缺点[9],有几张图片,可能比较直观
3.2 Variational Autoencoders(VAE )
下一篇介绍
参考文献
[1]Goodfellow I. NIPS 2016 Tutorial: GenerativeAdversarial Networks[J]. arXiv preprint arXiv:1701.00160, 2016.
[2]Ng A Y, Jordan M I. On discriminative vs.generative classifiers: A comparison of logistic regression and naive bayes[J].Advances in neural information processing systems, 2002, 2: 841-848.
[4] Zhu J Y, Krähenbühl P, Shechtman E, et al.Generative visual manipulation on the natural image manifold[C]//EuropeanConference on Computer Vision. Springer International Publishing, 2016:597-613.
[5]Oord A, Kalchbrenner N, Kavukcuoglu K. Pixelrecurrent neural networks[J]. arXiv preprint arXiv:1601.06759, 2016.
[6]https://en.wikipedia.org/wiki/Chain_rule_(probability)
[7] Luo W, Li Y, Urtasun R, et al. Understanding the Effective Receptive Field in Deep Convolutional Neural Networks[C]//Advances inNeural Information Processing Systems. 2016: 4898-4906.
[8] http://blog.csdn.net/peaceinmind/article/details/50848128
[9]https://www.zhihu.com/question/54414709














 1897
1897











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









