







矩阵乘法的常数优化
philipsweng
虽然说作为键盘科学家,我们更应该关心程序的时间复杂度。但是一个写的不好的程序可能在实际运行会跟时间复杂度更差的程序差不了多少。我们我们也应该注意程序的常数优化。
对于矩阵乘法来讲。我们实际上可以比较这两种打法。
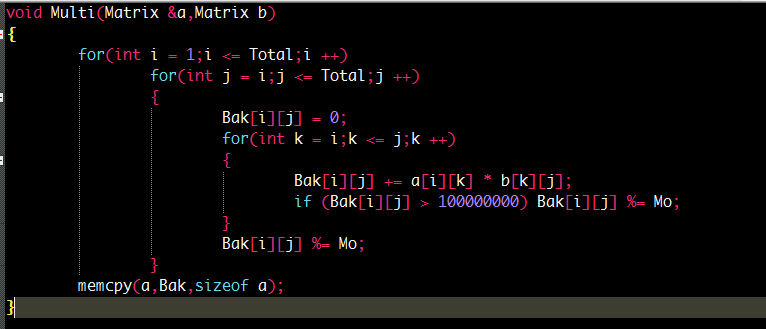
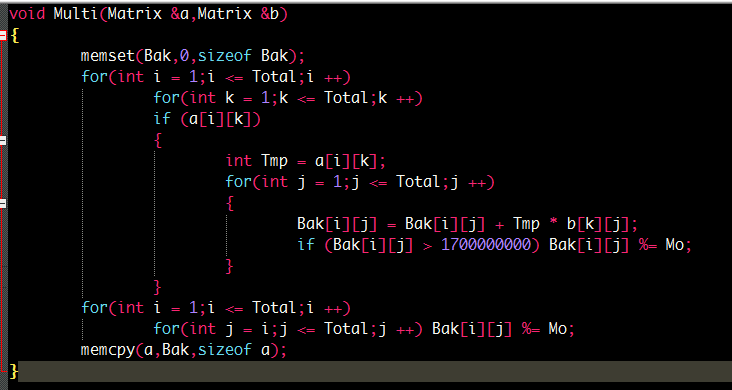
实际上第二种打法在绝大多数情况下效率约为第一种的两倍。
这是为什么???
注意到第二个程序的k放在了第二层。
C[i][j] = a[i][k] * b[k][j]
那么我们枚举的顺序就使得a[i]数据顺序枚举以及b[k]顺序枚举。
那么我们数组的寻址速度会增加许多。
然后对于取模操作,我们并不需要每次都取模,因为取模太缓慢。我们可以界定一个范围再取模(慎用。容易溢出)














 4979
4979











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









