







一、Recall(查全率)与Precision(查准率)
在信息检索和自然语言处理中经常会使用这些参数,下面简单介绍如下:
我们先看下面这张图来加深对概念的理解,然后再具体分析。其中,用P代表Precision,R代表Recall
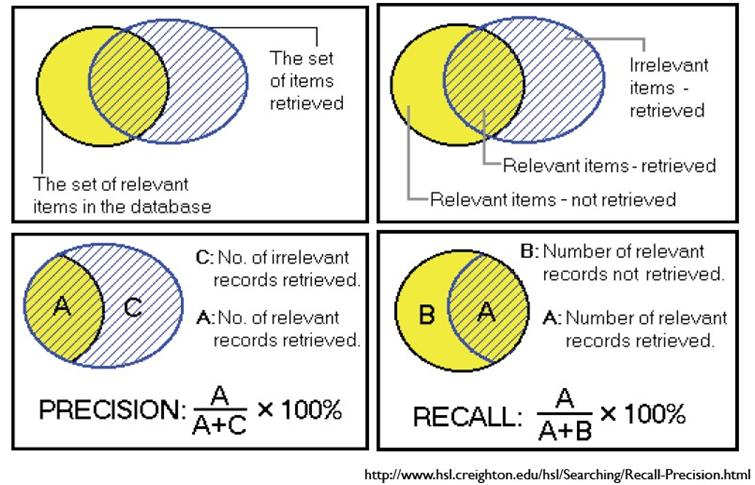
一般来说,Precision 就是检索出来的条目中(比如:文档、网页等)有多少是准确的,Recall就是所有准确的条目有多少被检索出来了。
下面这张表介绍了True Positive,False Negative等常见的概念,P和R也往往和它们联系起来。
| Relevant | NonRelevant | |
| Retrieved | true positives (tp) | false positives(fp) |
| Not Retrieved | false negatives(fn) | true negatives (tn) |
那么,
我们当然希望检索的结果P越高越好,R也越高越好,但事实上这两者在某些情况下是矛盾的。比如极端情况下,我们只搜出了一个结果,且是准确的,那么P就是100%,但是R就很低;而如果我们把所有结果都返回,那么必然R是100%,但是P很低。
因此在不同的场合中需要自己判断希望P比较高还是R比较高。如果是做实验研究,可以绘制Precision-Recall曲线来帮助分析。
note by watkins:
下面截取了一个P-R曲线做个展示。
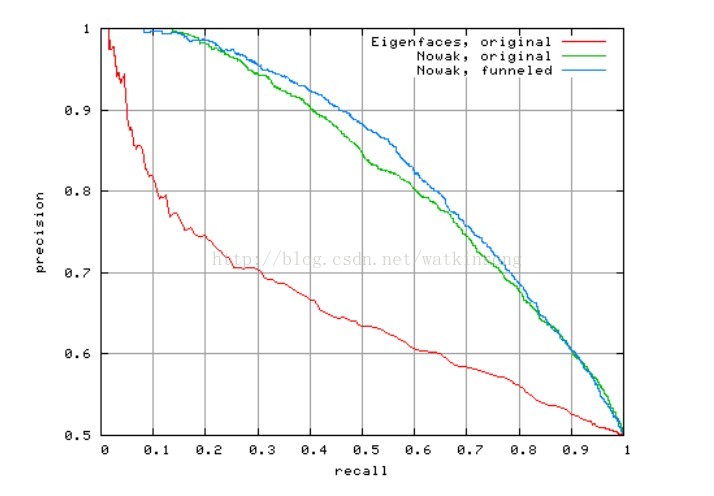
Precision和Recall是成反比关系的,所以给出实验结果时一般都是给出一个Precision-Recall图。例如当Recall等于0,5时的Precision图。
进一步补充:
在判断检索结果好坏时,查全率(Recall ratio)与查准率(Precision ratio)是两个最常用的指标。它们表示系统的“过滤能力”,即让相关文献“通过”,“阻止”无关文献。
查全率与查准率的定义如下:
R(查全率)=(检出的相关文献数量/检索系统中相关文献总量)* 100%;
P(查准率)=(检出的相关文献数量/检出的文献总量)* 100%
——《文献检索与利用》—花芳
例如:在一次检索中,共检出文献100篇,经过专家判定,其中与提问相关的文献为60篇,其余的40篇为误检文献,那么按照上述公式,本次检索的查准率P就等于(60/100)×100%即60%。假如检索系统中还有90篇相关文献,由于各种原因而未被检出(漏检),那么按照上述公式,本次检索的查全率就等于(60/60+90)×100%即40%。
可见,利用上述公式,对每一次信息检索,都可计算出其查准率和查全率,对检索效率作出定量化的评价。
但是,如果进一步分析,就会发现查准率的计算没有问题,而查全率的计算存在明显的问题。那就是怎样知道漏检文献的数量。
对于小型的试验系统,在进行检索效率评价时,只要把系统中所有的文献都浏览一遍,就能准确地获得漏检文献的数量。然而,在实际运行的检索系统中,由于系统文献总量通常数以百万计,在评价检索效率时,根本不可能把浏览系统中所有的文献,因此,也就无法知道漏检文献数量。
所以,在实际的检索评价中,对于漏检文献数量,一般采用近似的估计值。获得漏检文献数量估计值的方法有两种:其一,利用其他的同类检索系统,进行相同的检索,然后通过对命中结果的分析和比较,推断哪些文献被漏检;其二,利用原有的检索系统,放大检索范围进行查找,然后对命中结果进行分析,看是否有原先未被检出的相关文献,从而得到漏检文献的近似值。
.查准率与查全率之间的关系
利用查准率和查全率指标,可以对每一次检索进行检索效率的评价,为检索的改进调整提供依据。利用这两个量化指标,也可以对信息检索系统的性能水平进行评价。
要评价信息检索系统的性能水平,就必须在一个检索系统中进行多次检索。每进行一次检索,都计算其查准率和查全率,并以此作为坐标值,在平面坐标图上标示出来。通过大量的检索,就可以得到检索系统的性能曲线。
———《文献检索与利用》陈老师
二、AR(Average Recall,平均查全率)与ANMRR(Average Normalized Modified Retrieval Rate,平均归一化调整的检索秩)
RR
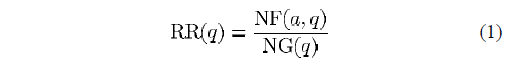
其中
NG(q) 数据集中与q主观相似的图像个数
NF(a,q) 在检索到的前a个结果中,与q相似的图像的个数
RR(q) :Recall
我们使用NQ个查询请求来测试该系统,则有
ARR
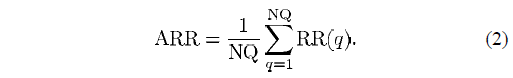
由于检索结果中主观正确图片的排序在评价检索性能中同样起到很重要的作用,我们还需要考虑排序的影响(根据我的理解,意思是当产生一次检索结果时,其实只是对数据库中的数据的一种排序,我们只需要取前K个(K的计算方式后文已给出),然后看看里面网到了多少个正确的),这时我们设置Rank(k)表示查询q中第kth个主观正确结果的排序(依我看来,意思是,对于一次查询q,我们只取前K个,然后其中有正确的项则看它是排名第几,Rank(k)的值即为几,而那些也是符合要求的本来应该查到的,但是排名却K名以后的,则统一取1.5K)。并且引入截断参数K (Relevant ranks) >= NG。关于如何选择K,有的文献直接给出了下面这个方法,就是选择K = min{ 4xNG(q), 2 x GTM } 其中GTM 表示所有查询请求中最大的主观相似图像个数,也就是最大的NG
这时我们得出了一个更优的排序函数来代替Rank(k)
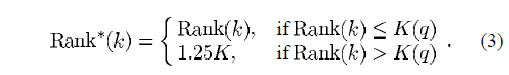
结合(3) 我们可以得出 Average Rank (AVR,平均检索秩)
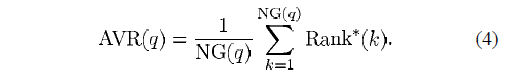
由于在一个数据集中NG(q)是不同的,而且变化的幅度很大,为了减少NG(q)对评价函数的影响,可以使用下面的这个函数来代替(4)
MRR (Modified Retrieval Rank,修正后的检索秩)
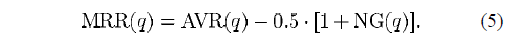
然后归一化一下,这是由于MMR的上限仍然受到NG的影响。
NMRR (Normalized Modified Retrieval Rank,归一化修正后的检索秩)
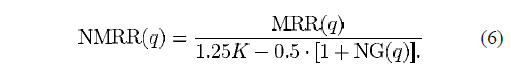
下一个公式当然是求平均值:
ANMRR (Average Normalized Modified Retrieval Rank,平均归一化修正后的检索秩)
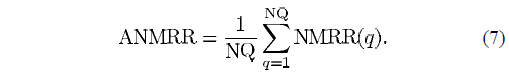
好了,介绍完毕,如果想要看更具体的解释,可以参看[1]。
-------------------------------------------华丽分割-----------------------------------------------
最后,说评判标准不能不提一下数据集的问题。数据集不同往往会对检索算法的准确度起到很大的影响。换句话说,现在的大多算法都是针对数据集的,换一个数据集后检索效果会差很多。最近已经有大牛在CVPR2011上就数据集的问题进行了讨论,这篇文章我还没看,但是在网上找到了有人写的关于这篇文章的介绍和心得,有兴趣的人可以去这里了解下(该作者很会卖萌) http://www.cvchina.info/2011/06/23/cvpr-nb-paper/
同样,这个问题在实际项目中更是明显。例如,在我做过的一个针对商品形状检索的需求中,曾经发现一些看似有很好检索效果的算法其实并不像实验中那么好。因为在实验中大多采用的是一些轮廓很清楚正确的图形,而在真实项目中,即使是在简单背景下,我们也很难对所有商品都获得很好轮廓的。
有时想想,图像检索这个领域真是没法去搞研究,连如何测试算法性能都是一个悬而未决的问题。在我看来,我们还不如直接在实际项目中去检验,针对不同的应用背景所作出的结果往往更加真实更有说服力。
-------------------------------------------------------------------------------------
Reference:
[1] Manjunath, B. S., Ohm, J.-R., Vasudevan, V. V., and Yamada, A. Color and texture descriptors. IEEE Trans. Circ. Syst. Video Technol. 11, 6, 703--715, 2001
[2] R. Datta, D. Joshi, J. Li and J.Z. Wang, Image Retrieval: Ideas, Influences, and Trends of the New Age, ACM Computing Surveys, vol. 40, no. 2, pp. 1-60, 2008.
进一步补充:
AR(Average Recall, 平均查全率), ANMRR(Average Normalized Modified Retrieval Rate, 平均归一化调整后的检索秩)
















 1601
1601











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









