









目标网站为http://www.ccgp-hubei.gov.cn,经检查HTML代码发现这个网页有一个iframe,iframe里面的内容才是网站的真正有用的内容,所以第一步是要先找到真正的URL。

以http://www.ccgp-hubei.gov.cn/fnoticeAction!listFNotice.action为例,这个网址的主要结构是一个分页的列表,有上页、下页等等。查看这两个按钮的HTML Element可以看到这是一个js的函数:
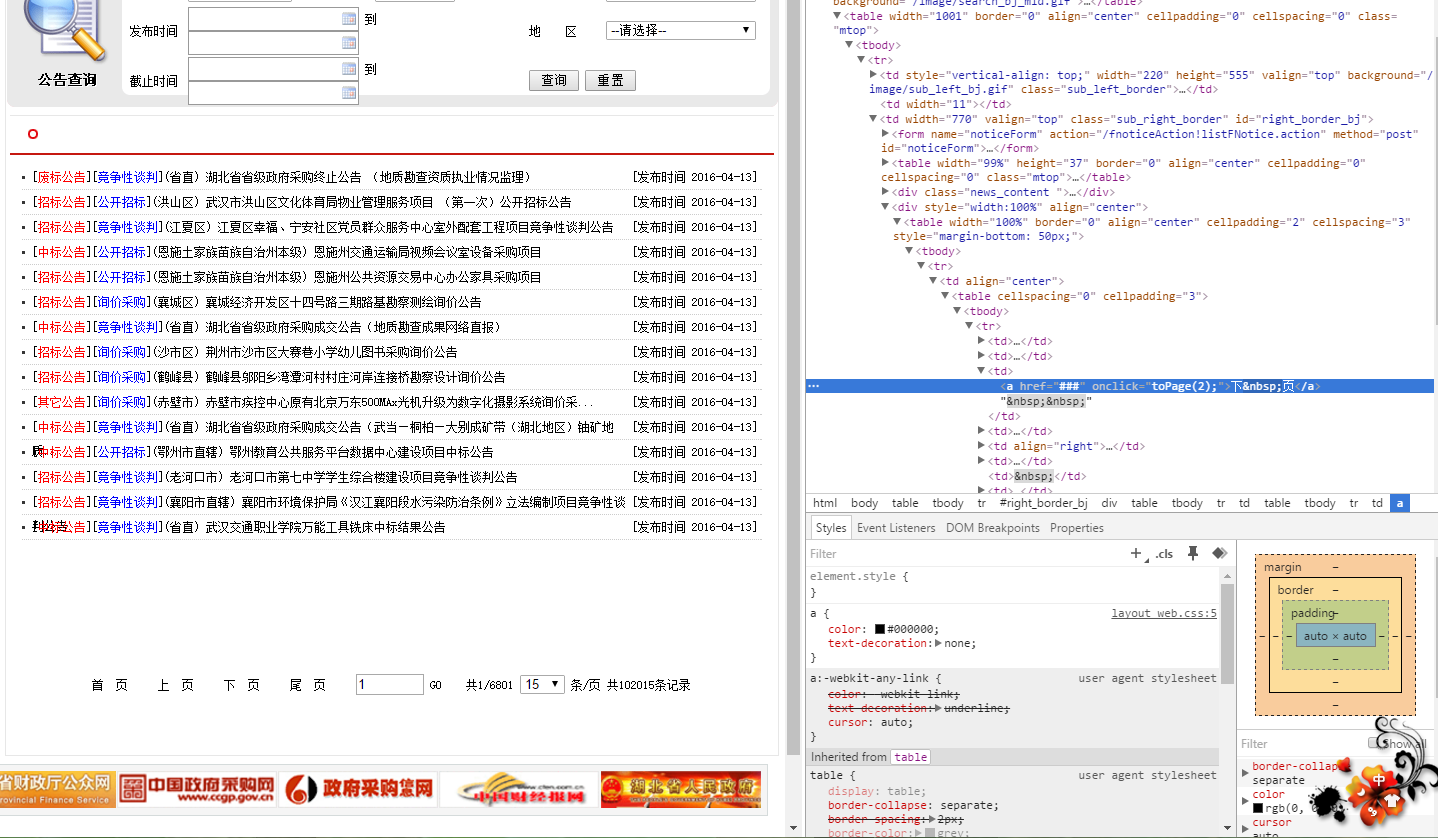
一开始的时候我一直在想,既然这是js函数,那我就用ScrapyJS + Splash的组合来解决,但是经过试验发现出现了一个问题。就是在Splash脚本中,可以修改document.title = "hello"之类的东西,但是调用了js函数转到另一个链接之后,返回的仍然是最开始时候的HTML代码,无论是用splash:html()还是document.body.innetHTML都不行。不知道到底是没有运行js函数成功,还是Splash本身的问题,在网上查找了一下,发现遇到这种问题的人很多,但是没有一个可行的方案,最后GitHub上某大神告诉我Splash在开发splash:mouse_click()函数,让我静静等待。
无奈之下,我换了种思路,开启F12,点击“下页”按钮,看看浏览器倒底做了什么,如图所示:
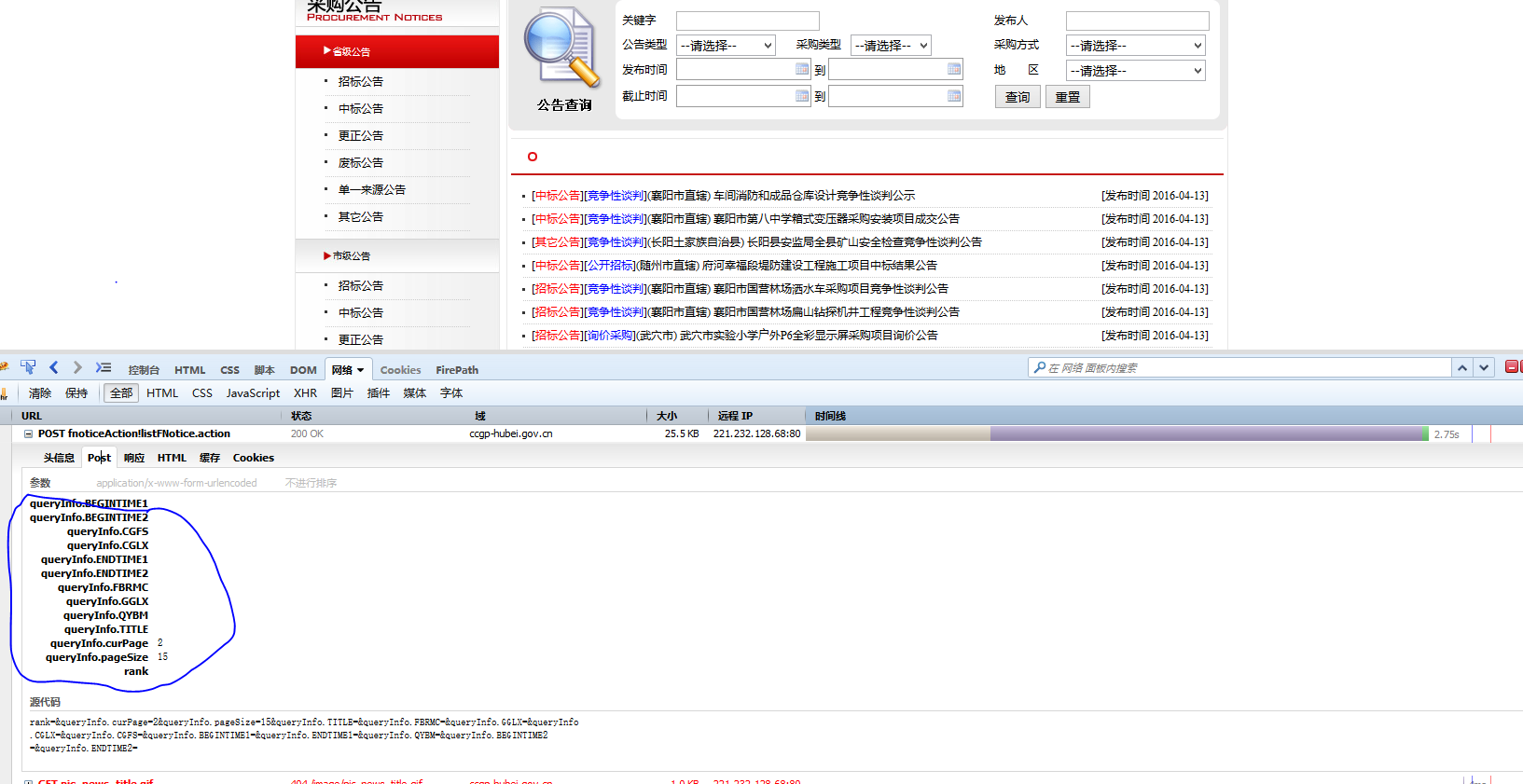
这就量浏览器POST的数据,这下尝试一下直接向服务器发送这些数据:
# -*- coding: utf-8 -*-
from scrapy.spiders import Spider
from scrapy.http import FormRequest
from scrapy.shell import inspect_response
class ThirdSpider(Spider):
name = 'ThirdSpider'
download_delay = 0
start_urls = [
'http://www.ccgp-hubei.gov.cn/fnoticeAction!listFNotice.action'
]
def parse(self, response):
formdata = {"queryInfo.BEGINTIME1": "", "queryInfo.BEGINTIME2": "",
"queryInfo.CGFS": "", "queryInfo.CGLX": "", "queryInfo.ENDTIME1": "",
"queryInfo.ENDTIME2": "", "queryInfo.FBRMC": "", "queryInfo.GGLX": "",
"queryInfo.QYBM": "", "queryInfo.TITLE": "", "queryInfo.curPage": "2",
"queryInfo.pageSize": "15", "rank": ""}
yield FormRequest.from_response(response, formdata=formdata, callback=self.parse_item)
def parse_item(self, response):
inspect_response(response, self)
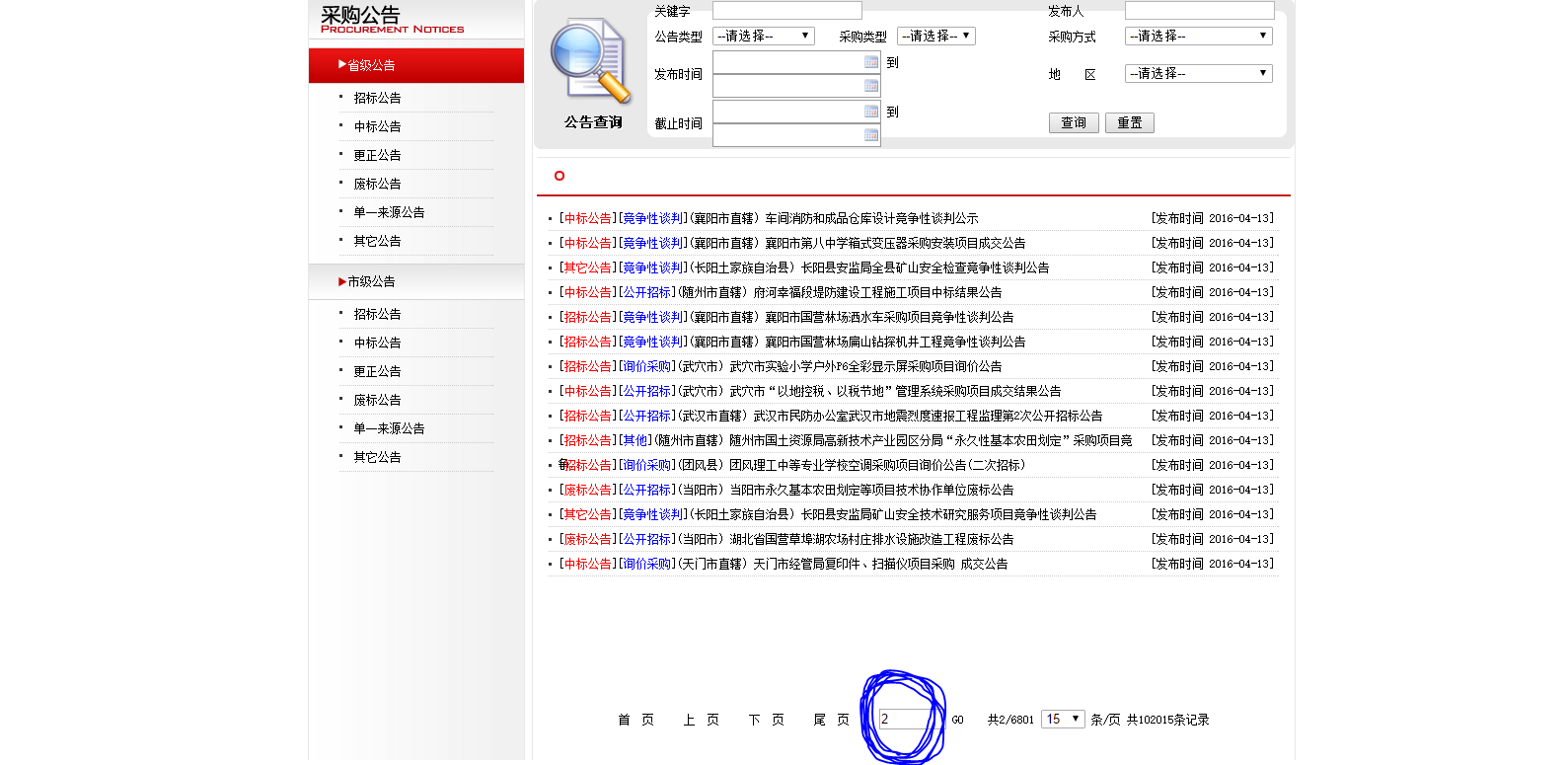
结果如下所示,可以看到页码果然已经转到了第二页,至此问题结束。














 1227
1227











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









