







【阿里集团卜居深度解析】卷积神经网络的硬件加速
from: https://zhuanlan.zhihu.com/p/21430333前言
在计算机发展和互联网渗透下,世界上的数据规模呈爆发式增长,普通人越来越容易获取这些数据,人工智能也实现了从早期的人工特征工程到现在能够自动从海量数据中学习的华丽转变,计算机视觉、语音识别和自然语言处理等应用也取得众多突破。这其中最流行的一类技术称为深度学习,曾在工业界引起了不小的轰动。
一.卷积神经网络
卷积神经网络缩写为CNN,最早受神经科学研究的启发。经过长达20多年的演变,CNN在计算机视觉、AI领域越来越突出,著名的在围棋对抗中以 4 : 1 大比分优势战胜李世石的 AlphaGo 就采用了 CNN + 蒙特卡洛搜索树算法。
一个典型CNN由两部分组成:特征提取器 + 分类器。特征提取器用于过滤输入图像,产生表示图像不同特征的特征图。这些特征可能包括拐角,线,圆弧等,对位置和形变不敏感。特征提取器的输出是包含这些特征的低维向量。该向量送入分类器(通常基于传统的人工神经网络),得到输入属于某个类别的可能性。下图展示了一个真实 CNN 模型架构【6】。
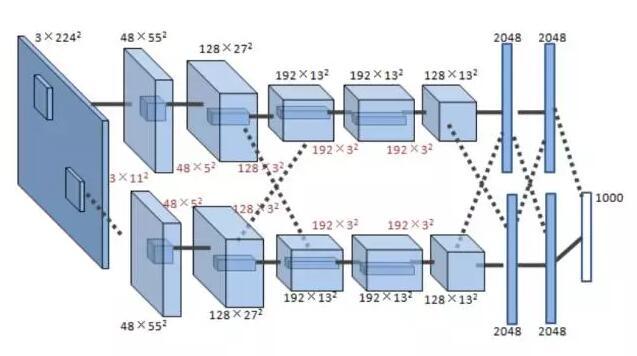
该CNN包括8层,前5层为卷积层,第6~8层为全连接层。输入层为3通道224 x 224输入图像(由原始三通道256 x 256 RGB图像缩放得到),输出1000维向量表示该图像属于1000个类别的概率密度分布。
一个典型CNN包括多个计算层,其中特征提取器包括若干个卷积层和(可选的)下采样层。
卷积层以N个特征图作为输入,每个输入特征图被一个K * K的核卷积,产生一个输出特征图的一个像素。滑动窗的间隔为S,一般小于K。总共产生M个输出特征图。卷积层的 C 代码如下: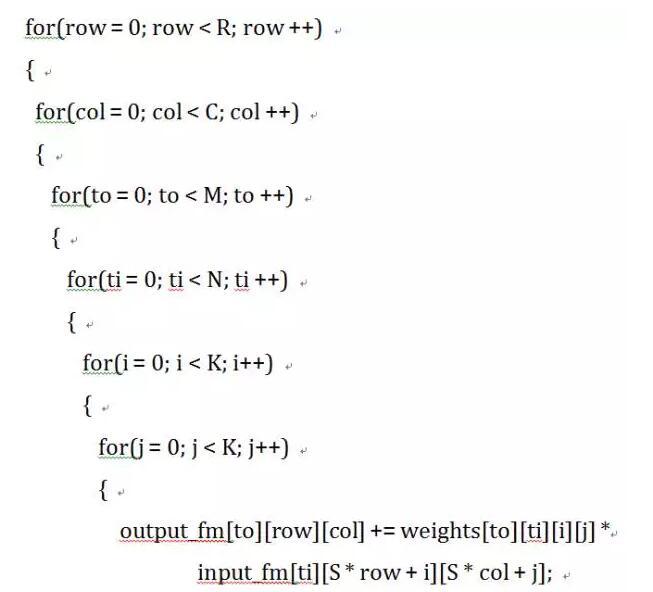

需要说明,上述6层循环实现只是为了便于理解,不是最优的算法。从该实现也可以得出卷积层一次前向传播的计算量为(R x C x M x N x K x K)次乘加。
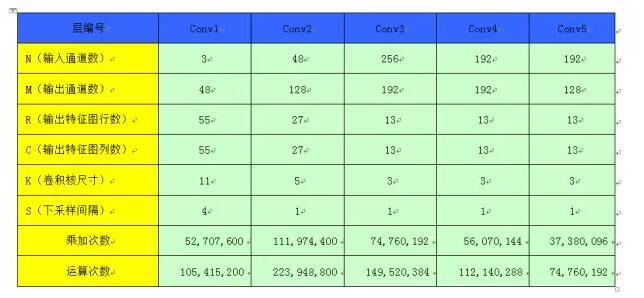
论文【7】证明卷积层会占据超过90%的总计算时间,所以本文我们关注卷积层硬件加速。
下表记录了 AlexNet 模型的各个卷积层参数配置和计算量情况
 二.硬件平台
二.硬件平台
最近在多层卷积神经网络结构上取得的突破让识别任务(如大量图片分类和自动语音识别)准确率大幅提升。这些多层神经网络变得越来越大、越来越复杂,需要大量计算资源来训练和评估。然而这些需求发生在目前这样一个尴尬的时刻,商业处理器性能增长日趋缓慢,亟需新硬件平台加速。
NVIDIA乘这一波深度学习爆发之势大力推进了基于 GPU 的加速方案,包括新处理器架构(Kepler、Maxwell、Pascal)、高效的加速库(cuBLAS、cuDNN)、灵活直观的训练系统(DIGITS)。当前深度学习系统已经大量使用 GPU 集群作为处理平台。
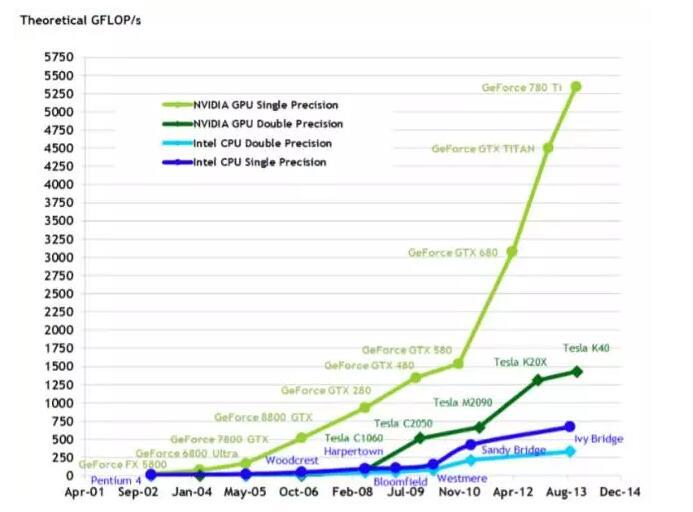
从上图看出,GPU 的计算能力发展速度远远超过了同时期的CPU,一些并行计算任务在 GPU 上可以获得显著加速。
使用 FPGA 也逐渐成为一种替代方案。由于 FPGA 架构灵活,研究者能够发挥模型级别优化,这是在固定架构如 GPU 上不具备的优势。FPGA 提供每瓦高性能,对于应用科学家大规模基于服务器的部署或资源受限的嵌入式应用非常有吸引力。以下为 FPGA 加速器件随时间变化情况。
1)低密度 FPGA(DSP 单元数目 < 500 )2009年【2】,单颗 FPGA 计算能力: < 100 GOPS。
使用了两种不同平台:
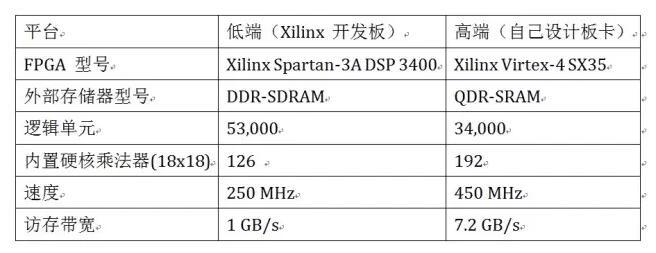
2)SoC 平台(DSP 单元数目 < 1000)
2013年【9】。
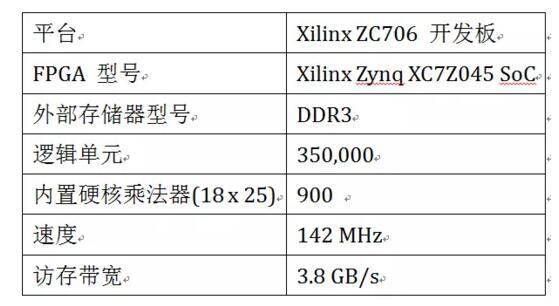
3)中密度 FPGA(DSP 数目 1500~3000)
2015年【3】【4】,单颗 FPGA 计算能力:< 1 TFLOPS。
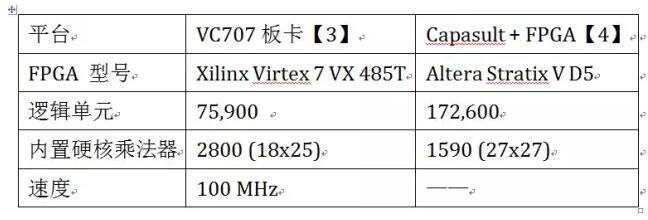
4)高密度 FPGA(DSP 数目 5000~10000)
2017年(TBD),单颗 FPGA 计算能力:接近 10 TFLOPS,下图是Stratix 10 中的变精度DSP。
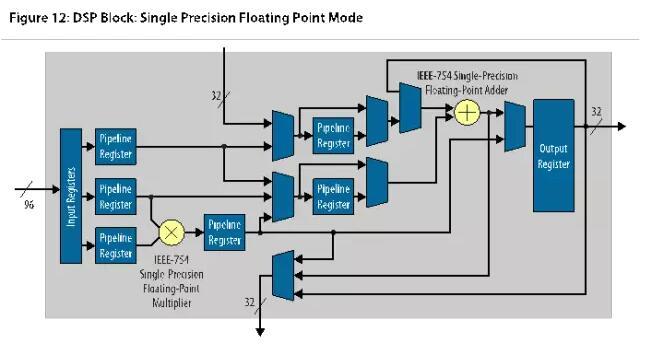 Stratix 10 中每个变精度DSP 硬核可以独立配置为定点模式或兼容 IEEE-754 的浮点模式。上图为浮点模式,每个 DSP 硬核都包括一个单精度浮点乘法器和一个单精度浮点加法器,可以实现浮点加法、浮点乘法、浮点乘加、浮点乘累加等基本计算,非常适合 CNN 加速。
Stratix 10 中每个变精度DSP 硬核可以独立配置为定点模式或兼容 IEEE-754 的浮点模式。上图为浮点模式,每个 DSP 硬核都包括一个单精度浮点乘法器和一个单精度浮点加法器,可以实现浮点加法、浮点乘法、浮点乘加、浮点乘累加等基本计算,非常适合 CNN 加速。
作为一种经典有监督学习算法,CNN使用前馈处理用于识别,反馈用于训练。
在工业实践中,很多应用设计者离线训练CNN,然后用训练好的CNN实现实时任务。因此,前馈计算速度是比较重要的。本文关注用基于FPGA的加速器设计前馈计算加速。下面是几个方案。
1)面向卷积核的并行流水线卷积器【2】
Yann LeCun 2009 年的论文【2】中介绍了低端FPGA 上高效实现 ConvNets 的工作。利用了 ConvNets 内在并行性和 FPGA 上多个硬件乘累加单元。整个系统使用单个 FPGA 以及外部存储模块实现,没有其他额外单元。架构如下图所示。
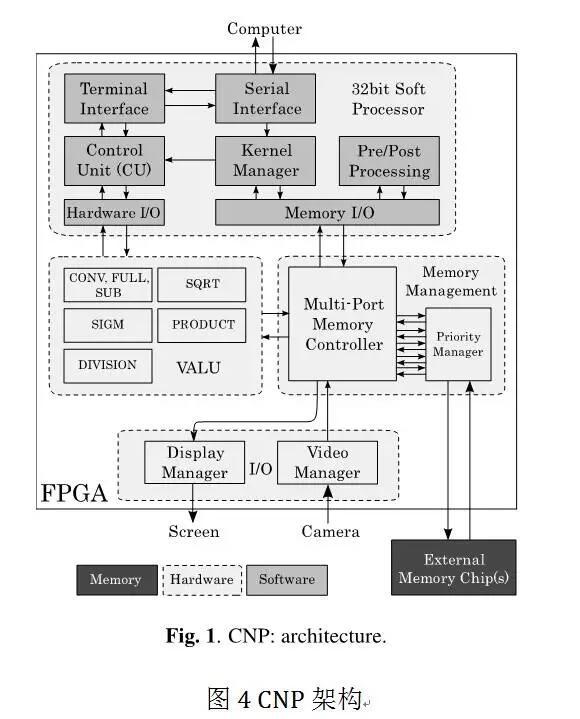
CNP 包括一个控制单元(CU, Control Unit),一个并行流水线向量算法逻辑单元(VALU, Vector Arithmetic and Logic Unit),一个 I/O 控制单元和一个存储器接口。CU 实际上是一个麻雀虽小五脏俱全的 32位软核 CPU,基于 PowerPC 架构,用来将 VALU 进行序列化操作。VALU 实现了卷积网络相关操作,包括二维卷积,空域下采样,逐点非线性函数,以及其他更通用的向量操作(平方根,除法)。VALU 包括其他指令(除法,平方根,乘法),用作图像预处理。完整视觉系统需要的其他运算可以在通用软核 CPU 上完成。
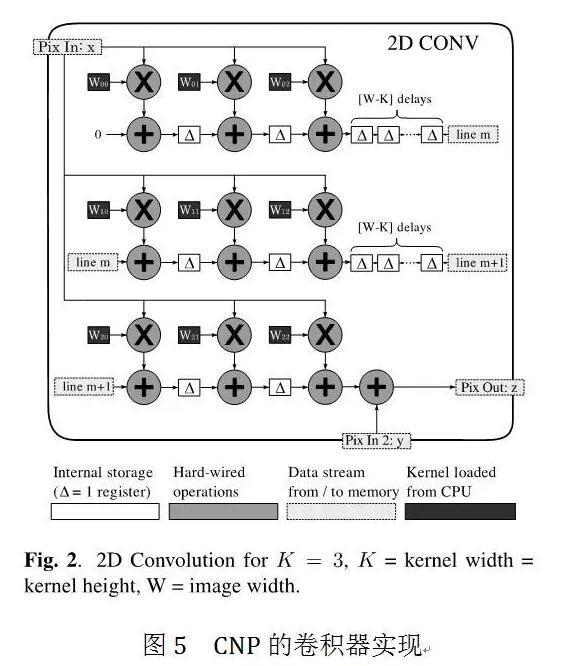
VALU 上二维卷积的实现:
二维卷积器如下图所示,增加了后累加,允许将多个卷积器组合。
 在一个时钟周期内,完成如下计算:
在一个时钟周期内,完成如下计算:
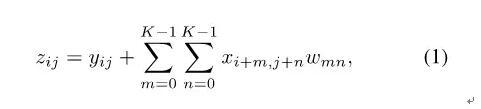
这里xij是输入图像值, wmn是K×K卷积核的值, yij是待累加值,zij是输出图像值。
输入图像值进入K个片上 FIFO,尺寸为图像宽度减去卷积核宽度。
在 FIFO 中移动这些值等价于在输入图像上移动卷积窗口。在每个时钟周期,送入一个值,输入图像窗口与卷积核进行点积并行计算。换句话说,卷积器每个时钟周期可以同时执行K^2次乘累加计算(计入加上累加临时图像 )。
于是,完整卷积运算所需时钟周期数等于输出图像值数目 + 填充 FIFO 必须的延迟(大概等于输入图像宽度乘以卷积核高度)。
所有运算中卷积核都以 16 位定点数表示。中间累加值以 48 位保存在 FIFO 中。
低端 FPGA 有126 个乘累加单元,最大实现 11 x 11 卷积核或两个 7 x 7 卷积核,相应理论最大速率为每秒 24.5 次运算(时钟为 250 MHz)。然而试验中使用了单个 7 x 7 卷积器,因为当时使用的网络不需要更大的卷积核,相应理论最大速率每秒 12 G次运算。
2)Zynq SoC嵌入式方案 nn-X【9】
在这篇文章《A 240 G-ops/s Mobile Coprocessor for Deep Neural Networks》中使用 Zynq SoC 实现了 CNN 加速器,架构如下图所示。
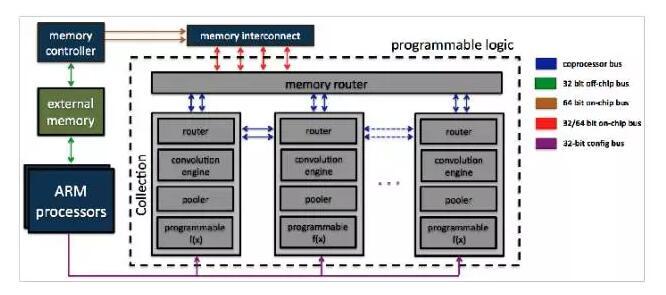
卷积器的架构没有给出,但根据文章描述,推测与方案一基本一致。所有计算都以定点格式 Q8.8 进行。该方案实现了 8 路 并行引擎,每个引擎提供 10 x 10 卷积器,等效计算能力达到每秒 227 G 次运算(乘加为两次运算)。由于使用 Q8.8 定点形式计算,每个乘加器都可以使用一个 DSP 单元实现,共需要 800 个 DSP单元(总共 900 个)。
3)方案三:SIMD 卷积引擎【3】
前面两种方案均为面向卷积核的卷积器,具有如下缺点:当卷积核尺寸变化时(如AlexNet 第一个卷积层尺寸为 11 x 11,而后面卷积核逐渐缩小为 5 x 5 和 3 x 3),不能充分发挥硬件的并行计算性能,造成大量的资源浪费。随着新型网络更多奇异的卷积核(如NIN 中的 1 x 1 卷积核、 1 x N 或 N x 1卷积核),资源浪费情况会越来越严重,甚至变为串行计算结构。方案三则采用很多算法技巧,包括将大图像分块、通道优先累加、兼顾访存和计算等,实现了 SIMD 型计算架构,不再与具体卷积核尺寸挂钩,运行时计算资源利用率更高。
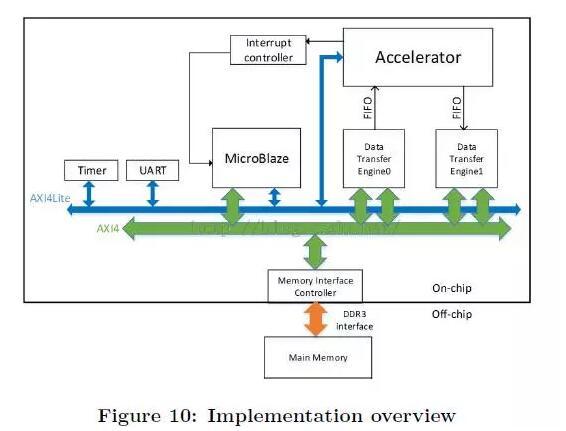
该方案下全部系统都放在了单个FPGA芯片,使用DDR3 DRAM用于外部存储。
MicroBlaze是一个RISC处理器软核,用于帮助CNN加速器启动,与主机CPU通信,以及计时。MicroBlaze和CNN加速器使用中断机制来提供精确的计时。AXI4lite总线用于传输命令,AXI4总线用于传输数据。CNN加速器作为AXI总线上一个IP。它从MicroBlaze接收命令和配置参数,与定制的数据传输引擎通过FIFO接口通信,该数据传输引擎可以获取通过AXI4总线外部存储。
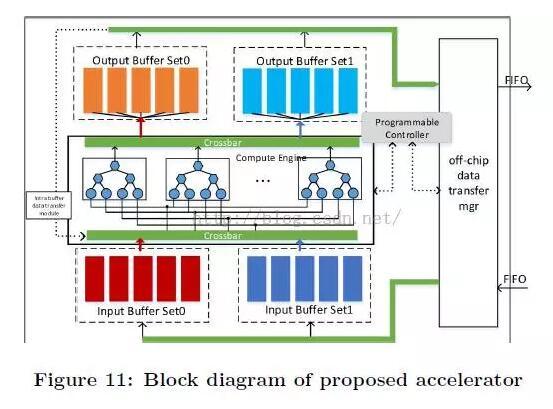
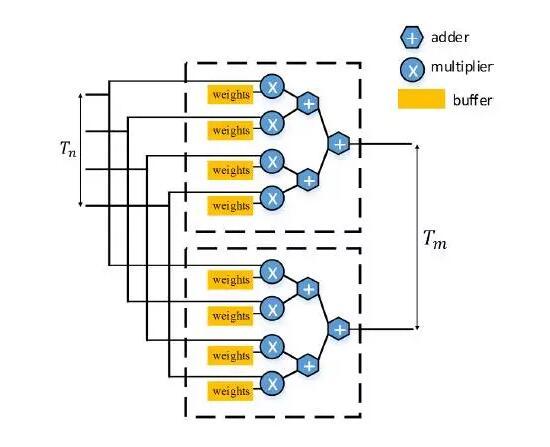 上图是SIMD 加速器实现,该计算引擎部分显示了实现的模块图。所有数值都以单精度浮点表示。每个引擎由7个乘法器和7个加法器组成,每个加法器消耗2个DSP,每个乘法器消耗3个DSP,每个引擎总共消耗35个DSP。系统一共实现了64个引擎,故消耗 64 x 35 = 2240 个 DSP 单元(FPGA 上共有 2800 个 DSP)。整个系统峰值计算能力达到 64 x 15 x 100 MHz = 96 GFLOPS,实测达到了 61.62 GFLOPS。
上图是SIMD 加速器实现,该计算引擎部分显示了实现的模块图。所有数值都以单精度浮点表示。每个引擎由7个乘法器和7个加法器组成,每个加法器消耗2个DSP,每个乘法器消耗3个DSP,每个引擎总共消耗35个DSP。系统一共实现了64个引擎,故消耗 64 x 35 = 2240 个 DSP 单元(FPGA 上共有 2800 个 DSP)。整个系统峰值计算能力达到 64 x 15 x 100 MHz = 96 GFLOPS,实测达到了 61.62 GFLOPS。
4)传统 CPU 服务器 + FPGA 加速板卡方案【4】
上面三种方案都是以独立 FPGA 板卡完成所有计算和控制功能。其中方案一和方案三使用软核 CPU 实现控制部分(方案一为 32 位 PowerPC 架构软核 CPU,方案三为 32 位 MicroBlaze 架构软核 CPU),而方案二使用 SoC 内嵌的硬核ARM Cortex A9 CPU 实现控制部分。三种方案缺陷比较明显:无论软核 CPU 还是硬核 CPU,主频都比较低(< 1 GHz),无法适应云端服务(大规模图像识别、在线语音识别等)加速的场景,而只能用于嵌入式产品。
方案四是云端服务 FPGA 加速的方案,具有高可扩展性、高效率的特点。
2014年微软宣布了Catapult项目,成功展示了用FPGA在数据中心使Bing Ranking加速了近2倍。利用这个基础,微软研究院开发了高吞吐CNN FPGA加速器,在很低的服务器功耗下获得了优异性能。下图给出了用于高效计算卷积层前向传播的CNN FPGA加速器高层次概览。
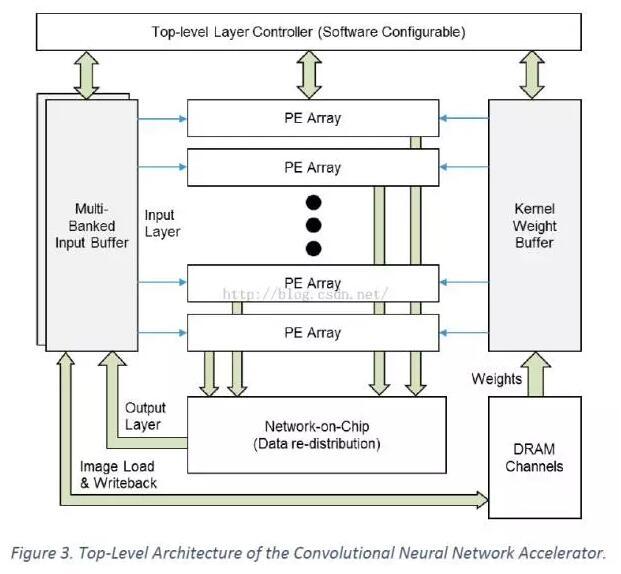 上图中高亮的加速器位于双插槽Xeon服务器,安装了一个Catapult FPGA卡,上有中等规模Stratix D5 FPGA和8GB DDR3-1333。每个FPGA卡都支持高达8GB/s带宽的PCIe 3x8,以及支持21.3GB/s带宽的本地DRAM。这样可以从服务器 CPU 获得计算负载,并在 FPGA 上完成计算,将结果返回 CPU 内存。通过 FPGA 加速 CNN 可以降低服务器功耗。
上图中高亮的加速器位于双插槽Xeon服务器,安装了一个Catapult FPGA卡,上有中等规模Stratix D5 FPGA和8GB DDR3-1333。每个FPGA卡都支持高达8GB/s带宽的PCIe 3x8,以及支持21.3GB/s带宽的本地DRAM。这样可以从服务器 CPU 获得计算负载,并在 FPGA 上完成计算,将结果返回 CPU 内存。通过 FPGA 加速 CNN 可以降低服务器功耗。
该方案并没有给出具体实现细节,只透露了关键特征如下:
(1)软件可配置的引擎,支持多层运行时配置(无需硬件重编程);
(2)高效数据缓冲体制和片上分发网络,将片外访存降至最低;
(3)处理单元(PE)构成的空间分布阵列,可很容易扩展到上千个单元;
在正常模式下,CNN加速器可以同时获取输入图像并连续处理多个卷积层。在初始阶段,输入图像像素从本地DRAM流入片上,存储到多个bank输入缓冲区。之后,数据流入多个PE阵列,实现3D卷积步骤中的独立点乘操作。顶层控制器完成序列化、寻址、分发数据到每个PE阵列。最终,累加结果发送到特定片上网络,将计算输出循环送入输入缓冲区用于下一轮的计算(虽然前图中没有显示,但存在额外的逻辑处理pooling和ReLU操作)。
更多硬件描述可参考Catapult论文【10】。
四.性能对比通过几篇论文的结果【2】【3】【4】【9】我们来量化本文四种硬件加速方案。
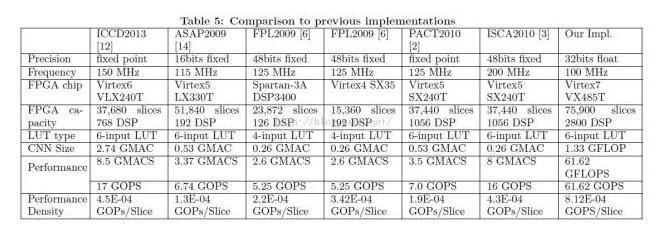
该结果为文献【3】提供,其中 FPL 2009 为本文文献【2】的结果。
方案一、方案二无法直接对比 AlexNet 性能,只能通过每秒计算能力对比:5.25 GOPS vs 227 GOPS。
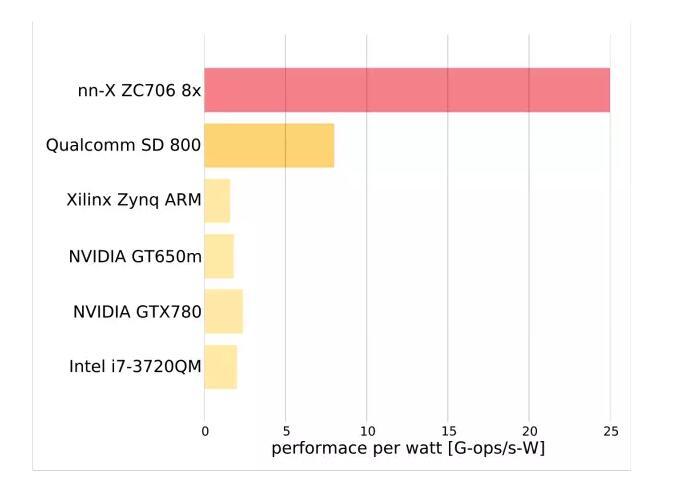 该结果为文献【9】提供,给出了每瓦性能对比情况,看到 FPGA 能效比高于 GPU、CPU 平台。
该结果为文献【9】提供,给出了每瓦性能对比情况,看到 FPGA 能效比高于 GPU、CPU 平台。

该结果为文献【4】提供,其中 Best prior CNN on Virtex 7 485T 为本文【3】的结果。
本文方案三和方案四均实现了 AlexNet 前向计算过程,性能分别为 46 images/s 和 134 images/s。同时看到 FPGA 每瓦性能相比 GPU 具有很大优势。
一些商业加速方案如AuvizDNN【11】也提供了针对 AlexNet 的处理性能:
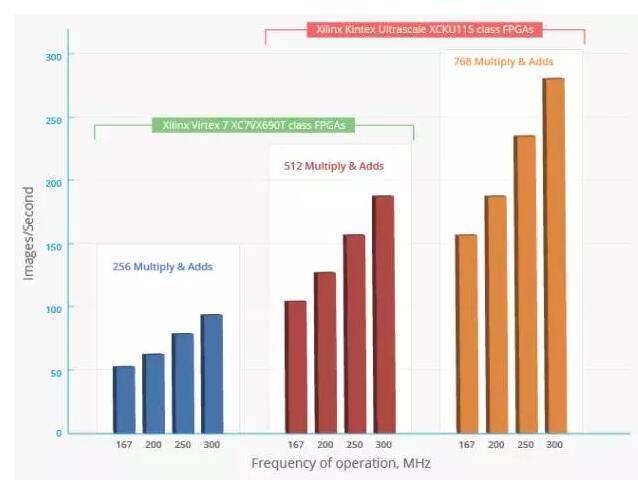
可以预见,随着 FPGA 集成度、主频进一步提高,在 CNN 加速能力上会逐渐赶超 GPU, 成为深度学习下一个爆发期的助推剂。
五. 阿里云高性能利器
阿里云 HPC 服务是于 2015 年 10月推出的面向高性能计算和深度学习的平台,目前已有大量计算密集型应用案例,涵盖语音识别、图像分类和检索、渲染、医疗成像、气象预测、物理仿真等领域。硬件平台采用高性能 Broadwell CPU、Tesla K40/M40 GPU。正在进行中的阿里 FPGA 项目基于 Intel Xeon + FPGA 平台【12】,CPU 与 FPGA 直接封装到同一个 package,具有更低的通信延迟,可满足灵活多变的应用热点加速场景。现已经针对语音、视频数据展开大量分析和处理。
参考文献
【1】Amos, Jagath. FPGA IMPLEMENTATIONS OF NEURAL NETWORKS. Springer 2006.
【2】Yann LeCun, et al. CNP : An FPGA-based Processor for Convolutional Networks. 2009.
【3】Optimizing FPGA-based Accelerator Design for Deep Convolutional Neural Networks, 2015, ACM 978-1-4503-3315-3/15/02
【4】Accelerating Deep Convolutional Neural Networks Using Specialized Hardware, 2015.
【5】Stratix 10 Device Overview, Altera, 2015.12.
【6】 A. Krizhevsky, I. Sutskever, and G. E. Hinton. Imagenet classification with deep convolutional neural networks. NIPS 2012.
【7】 J. Cong and B. Xiao. Minimizing computation in convolutional neural networks. ICANN 2014.
【8】 http://www.xilinx.com/products/boards-and-kits/ek-v7-vc707-g.html
【9】 A 240 G-ops/s Mobile Coprocessor for Deep Neural Networks, 2013
【10】A. Putnam, et al., A Reconfigurable Fabric for Accelerating Large-Scale Datacenter Services, International Symposium on Computer Architecture, 2014
【11】http://auvizsystems.com/products/auvizdnn/
【12】http://www.eweek.com/servers/intel-begins-shipping-xeon-chips-with-fpga-accelerators.html
该文章属于“深度学习大讲堂”原创,如需要转载,请联系@果果是枚开心果.
作者简介:

卜居,真名赵永科,CSDN 博主,博客地址: http://blog.csdn.net/kkk584520,现就职于阿里云计算有限公司,从事计算机体系结构、高性能计算系统设计。对计算机视觉、深度学习具有浓厚兴趣。擅长 CPU/GPU/FPGA 的算法加速与性能优化。 原文链接:http://mp.weixin.qq.com/s?__biz=MzI1NTE4NTUwOQ==&mid=502841049&idx=1&sn=68c4af53413422a624a6a79eeda60706#rd














 6343
6343











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









