







编程是困难的,正确的使用C/C++编程尤其困难。确实,不管是C还是C++,很难看到那种良好定义并且编写规范的代码。为什么专业的程序员写出这样的代码?因为绝大部分程序员都没有深刻的理解他们所使用的语言。他们对语言的把握,有时他们知道某些东西未定义或未指定,但经常不知道为何如此。这个幻灯片,我们将研究一些小的C/C++代码片段,使用这些代码片段,我们将讨论这些伟大而充满危险的语言的基本原则,局限性,以及设计哲学。
假设你将要为你的公司招聘一名C程序言,你们公司是做嵌入式开发的,为此你要面试一些候选人。作为面试的一部分,你希望通过面试知道候选人对于C语言是否有足够深入的认识,你可以这样开始你们的谈话:
- int main ()
- {
- int a= 42;
- printf(“%d\n”,a);
- }
当你尝试去编译链接运行这段代码时候,会发生什么?
一个候选者可能会这样回答:
你必须通过#include<stdio.h>包含头文件,在程序的后面加上 return 0; 然后编译链接,运行以后将在屏幕上打印42.
没错,这个答案非常正确。
但是另一个候选者也许会抓住机会,借此展示他对C语言有更深入的认识,他会这样回答:
你可能需要#include<stdio.h>,这个头文件显示地定义了函数printf(),这个程序经过编译链接运行,会在标准输出上输出42,并且紧接着新的一行。
然后他进一步说明:
C++编译器将会拒绝这段代码,因为C++要求必须显示定义所有的函数。然而,有一些特别的C编译器会为printf()函数创建隐式定义,把这个文件编译成目标文件。再跟标准库链接的时候,它将寻找printf()函数的定义,以此来匹配隐式的定义。
因此,上面这段代码也会正常编译、链接然后运行,当然你可能会得到一些警告信息。
这位候选者乘胜追击,可能还会往下说,如果是C99,返回值被定义为给运行环境指示是否运行成功,正如C++98一样。但是对于老版本的C语言,比如说ANSI C以及K&R C,程序中的返回值将会是一些未定义的垃圾值。但是返回值通常会使用寄存器来传递,如果返回值的3,我一点都不感到惊讶,因为printf()函数的返回值是3,也就是输出到标准输出的字符个数。
说到C标准,如果你要表明你关心C语言,你应该使用 intmain (void)作为你的程序入口,因为标准就这么说的。
C语言中,使用void来指示函数声明中不需要参数。如果这样声明函数int f(),那表明f()函数可以有任意多的参数,虽然你可能打算说明函数不需要参数,但这里并非你意。如果你的意思是函数不需要参数,显式的使用void,并没有什么坏处。
- int main (void)
- {
- inta = 42;
- printf(“%d\n”,a);
- }
然后,有点炫耀的意思,这位候选人接着往下说:
如果你允许我有点点书生气,那么,这个程序也并不完全的符合C标准,因为C标准指出源代码必须要以新的一行结束。像这样:
- int main ()
- {
- inta = 42;
- printf(“%d\n”,a);
- }
同时别忘了显式的声明函数printf():
- #include <stdio.h>
- int main (void)
- {
- inta = 42;
- printf(“%d\n”,a);
- }
现在看起来有点像C程序了,对吗?
然后,在我的机器上编译、链接并运行此程序:
- $ cc–std=c89 –c foo.c
- $ ccfoo.o
- $ ./a.out
- 42
- $ echo $?
- 3
- $ cc–std=c99 –c foo.c
- $ ccfoo.o
- $ ./a.out
- 42
- $ echo $?
- 0
这两名候选者有什么区别吗?是的,没有什么特别大的区别,但是你明显对第二个候选者的答案更满意。
也许这并不是真的候选者,或许就是你的员工,呵呵。
让你的员工深入理解他们所使用的语言,对你的公司会有很大帮助吗?
让我们看看他们对于C/C++理解的有多深……
- #include <stdio.h>
- void foo(void)
- {
- int a = 3;
- ++a;
- printf("%d\n", a);
- }
- int main(void)
- {
- foo();
- foo();
- foo();
- }
这两位候选者都会是,输出三个4.然后看这段程序:
- #include <stdio.h>
- void foo(void)
- {
- static int a = 3;
- ++a;
- printf("%d\n", a);
- }
- int main(void)
- {
- foo();
- foo();
- foo();
- }
他们会说出,输出4,5,6.再看:
- #include <stdio.h>
- void foo(void)
- {
- static int a;
- ++a;
- printf("%d\n", a);
- }
- int main(void)
- {
- foo();
- foo();
- foo();
- }
第一个候选者发出疑问,a未定义,你会得到一些垃圾值?
你说:不,会输出1,2,3.
候选者:为什么?
你:因为静态变量会被初始化未0.
第二个候选者会这样来回答:
C标准说明,静态变量会被初始化为0,所以会输出1,2,3.
再看下面的代码片段:
- #include <stdio.h>
- void foo(void)
- {
- int a;
- ++a;
- printf("%d\n", a);
- }
- int main(void)
- {
- foo();
- foo();
- foo();
- }
第一个候选者:你会得到1,1,1.
你:为什么你会这样想?
候选者:因为你说他会初始化为0.
你:但这不是静态变量。
候选者:哦,那你会得到垃圾值。
第二个候选者登场了,他会这样回答:
a的值没有定义,理论上你会得到三个垃圾值。但是实践中,因为自动变量一般都会在运行栈中分配,三次调用foo函数的时候,a有可能存在同一内存空间,因此你会得到三个连续的值,如果你没有进行任何编译优化的话。
你:在我的机器上,我确实得到了1,2,3.
候选者:这一点都不奇怪。如果你运行于debug模式,运行时机制会把你的栈空间全部初始化为0.
接下来的问题,为什么静态变量会被初始化为0,而自动变量却不会被初始化?
第一个候选者显然没有考虑过这个问题。
第二个候选者这样回答:
把自动变量初始化为0的代价,将会增加函数调用的代价。C语言非常注重运行速度。
然而,把全局变量区初始化为0,仅仅在程序启动时候产生成本。这也许是这个问题的主要原因。
更精确的说,C++并不把静态变量初始化为0,他们有自己的默认值,对于原生类型(native types)来说,这意味着0。
再来看一段代码:
- #include<stdio.h>
- static int a;
- void foo(void)
- {
- ++a;
- printf("%d\n", a);
- }
- int main(void)
- {
- foo();
- foo();
- foo();
- }
第一个候选者:输出1,2,3.
你:好,为什么?
候选者:因为a是静态变量,会被初始化为0.
你:我同意……
候选者:cool…
这段代码呢:
- #include<stdio.h>
- int a;
- void foo(void)
- {
- ++a;
- printf("%d\n", a);
- }
- int main(void)
- {
- foo();
- foo();
- foo();
- }
第一个候选者:垃圾,垃圾,垃圾。
你:你为什么这么想?
候选者:难道它还会被初始化为0?
你:是的。
候选者:那他可能输出1,2,3?
你:是的。你知道这段代码跟前面那段代码的区别吗? 有static那一段。
候选者:不太确定。等等,他们的区别在于私有变量(private variables)和公有变量(public variables).
你:恩,差不多。
第二个候选者:它将打印1,2,3.变量还是静态分配,并且被初始化为0.和前面的区别:嗯。这和链接器(linker)有关。这里的变量可以被其他的编译单元访问,也就是说,链接器可以让其他的目标文件访问这个变量。但是如果加了static,那么这个变量就变成该编译单元的局部变量了,其他编译单元不可以通过链接器访问到该变量。
你:不错。接下来,将展示一些很不错的玩意。静候:)
好,接着深入理解C/C++之旅。我在翻译第一篇的时候,自己是学到不不少东西,因此打算将这整个ppt翻译完毕。
请看下面的代码片段:
- #include <stdio.h>
- void foo(void)
- {
- int a;
- printf("%d\n", a);
- }
- void bar(void)
- {
- int a = 42;
- }
- int main(void)
- {
- bar();
- foo();
- }
编译运行,期待输出什么呢?
- $ cc foo.c && ./a.out
- 42
你可以解释一下,为什么这样吗?
第一个候选者:嗯?也许编译器为了重用有一个变量名称池。比如说,在bar函数中,使用并且释放了变量a,当foo函数需要一个整型变量a的时候,它将得到和bar函数中的a的同一内存区域。如果你在bar函数中重新命名变量a,我不觉得你会得到42的输出。
你:恩。确定。。。
第二个候选者:不错,我喜欢。你是不是希望我解释一下关于执行堆栈或是活动帧(activation frames, 操作代码在内存中的存放形式,譬如在某些系统上,一个函数在内存中以这种形式存在:
ESP
形式参数
局部变量
EIP
)?
你:我想你已经证明了你理解这个问题的关键所在。但是,如果我们编译的时候,采用优化参数,或是使用别的编译器来编译,你觉得会发生什么?
候选者:如果编译优化措施参与进来,很多事情可能会发生,比如说,bar函数可能会被忽略,因为它没有产生任何作用。同时,如果foo函数会被inline,这样就没有函数调用了,那我也不感到奇怪。但是由于foo函数必须对编译器可见,所以foo函数的目标文件会被创建,以便其他的目标文件链接阶段需要链接foo函数。总之,如果我使用编译优化的话,应该会得到其他不同的值。
- $ cc -O foo.c && ./a.out
- 1606415608
候选者:垃圾值。
那么,请问,这段代码会输出什么?
- #include <stdio.h>
- void foo(void)
- {
- int a = 41;
- a= a++;
- printf("%d\n", a);
- }
- int main(void)
- {
- foo();
- }
第一个候选者:我没这样写过代码。
你:不错,好习惯。
候选者:但是我猜测答案是42.
你:为什么?
候选者:因为没有别的可能了。
你:确实,在我的机器上运行,确实得到了42.
候选者:对吧,嘿嘿。
你:但是这段代码,事实上属于未定义。
候选者:对,我告诉过你,我没这样写过代码。
第二个候选者登场:a会得到一个未定义的值。
你:我没有得到任何的警告信息,并且我得到了42.
候选者:那么你需要提高你的警告级别。在经过赋值和自增以后,a的值确实未定义,因为你违反了C/C++语言的根本原则中的一条,这条规则主要针对执行顺序(sequencing)的。C/C++规定,在一个序列操作中,对每一个变量,你仅仅可以更新一次。这里,a = a++;更新了两次,这样操作会导致a是一个未定义的值。
你:你的意思是,我会得到一个任意值?但是我确实得到了42.
候选者:确实,a可以是42,41,43,0,1099,或是任意值。你的机器得到42,我一点都不感到奇怪,这里还可以得到什么?或是编译前选择42作为一个未定义的值:)呵呵:)
那么,下面这段代码呢?
- #include <stdio.h>
- int b(void)
- {
- puts("3");
- return 3;
- }
- int c(void)
- {
- puts("4");
- return 4;
- }
- int main(void)
- {
- int a = b() + c();
- printf("%d\n", a);
- }
第一个候选者:简单,会依次打印3,4,7.
你:确实。但是也有可能是4,3,7.
候选者:啊?运算次序也是未定义?
你:准确的说,这不是未定义,而是未指定。
候选者:不管怎样,讨厌的编译器。我觉得他应该给我们警告信息。
你心里默念:警告什么?
第二个候选者:在C/C++中,运算次序是未指定的,对于具体的平台,由于优化的需要,编译器可以决定运算顺序,这又和执行顺序有关。
这段代码是符合C标准的。这段代码或是输出3,4,7或是输出4,3,7,这个取决于编译器。
你心里默念:要是我的大部分同事都像你这样理解他们所使用的语言,生活会多么美好:)
这个时候,我们会觉得第二个候选者对于C语言的理解,明显深刻于第一个候选者。如果你回答以上问题,你停留在什么阶段?:)
那么,试着看看第二个候选者的潜能?看看他到底有多了解C/C++
可以考察一下相关的知识:
声明和定义;
调用约定和活动帧;
序点;
内存模型;
优化;
不同C标准之间的区别;
这里,我们先分享序点以及不同C标准之间的区别相关的知识。
考虑以下这段代码,将会得到什么输出?
- 1.
- int a = 41;
- a++;
- printf("%d\n", a);
- 答案:42
- 2.
- int a = 41;
- a++ & printf("%d\n", a);
- 答案:未定义
- 3.
- int a = 41;
- a++ && printf("%d\n", a);
- 答案:42
- 4. int a = 41;
- if (a++ < 42) printf("%d\n",a);
- 答案:42
- 5.
- int a = 41;
- a = a++;
- printf("%d\n", a);
- 答案:未定义
到底什么时候,C/C++语言会有副作用?
序点:
什么是序点?
简而言之,序点就是这么一个位置,在它之前所有的副作用已经发生,在它之后的所有副作用仍未开始,而两个序点之间所有的表达式或者代码执行的顺序是未定义的!
序点规则1:
在前一个序点和后一个序点之前,也就是两个序点之间,一个值最多只能被写一次;
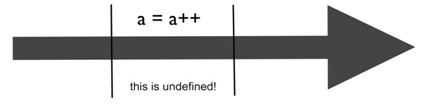
这里,在两个序点之间,a被写了两次,因此,这种行为属于未定义。
序点规则2:
进一步说,先前的值应该是只读的,以便决定要存储什么值。
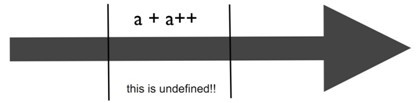
很多开发者会觉得C语言有很多序点,事实上,C语言的序点非常少。这会给编译器更大的优化空间。
接下来看看,各种C标准之间的差别:

现在让我们回到开始那两位候选者。
下面这段代码,会输出什么?
- #include <stdio.h>
- struct X
- {
- int a;
- char b;
- int c;
- };
- int main(void)
- {
- printf("%d\n", sizeof(int));
- printf("%d\n", sizeof(char));
- printf("%d\n", sizeof(struct X));
- }
第一个候选者:它将打印出4,1,12.
你:确实,在我的机器上得到了这个结果。
候选者:当然。因为sizeof返回字节数,在32位机器上,C语言的int类型是32位,或是4个字节。char类型是一个字节长度。在struct中,本例会以4字节来对齐。
你:好。
你心里默念:do you want another ice cream?(不知道有什么特别情绪)
第二个候选者:恩。首先,先完善一下代码。sizeof的返回值类型是site_t,并不总是与int类型一样。因此,printf中的输出格式%d,不是一个很好的说明符。
你:好。那么,应该使用什么格式说明符?
候选者:这有点复杂。site_t是一个无符号整型数,在32位机器上,它通常是一个无符号的int类型的数,但是在64位机器上,它通常是一个无符号的long类型的数。然而,在C99中,针对site_t类型,指定了一个新的说明符,所以,%zu会是一个不多的选择。
你:好。那我们先完善这个说明符的bug。你接着回答这个问题吧。
- #include <stdio.h>
- struct X
- {
- int a;
- char b;
- int c;
- };
- int main(void)
- {
- printf("%zu\n", sizeof(int));
- printf("%zu\n", sizeof(char));
- printf("%zu\n", sizeof(struct X));
- }
候选者:这取决与平台,以及编译时的选项。唯一可以确定的是,sizeof(char)是1.你要假设在64位机器上运行吗?
你:是的。我有一台64位的机器,运行在32位兼容模式下。
候选者:那么由于字节对齐的原因,我觉得答案应该是4,1,12.当然,这也取决于你的编译选项参数,它可能是4,1,9.如果你在使用gcc编译的时候,加上-fpack-struct,来明确要求编译器压缩struct的话。
你:在我的机器上确实得到了4,1,12。为什么是12呢?
候选者:工作在字节不对齐的情况下,代价非常昂贵。因此编译器会优化数据的存放,使得每一个数据域都以字边界开始存放。struct的存放也会考虑字节对齐的情况。
你:为什么工作在字节不对齐的情况下,代价会很昂贵?
候选者:大多数处理器的指令集都在从内存到cpu拷贝一个字长的数据方面做了优化。如果你需要改变一个横跨字边界的值,你需要读取两个字,屏蔽掉其他值,然后改变再写回。可能慢了10不止。记住,C语言很注意运行速度。
你:如果我得struct上加一个char d,会怎么样?
候选者:如果你把char d加在struct的后面,我预计sizeof(struct X)会是16.因为,如果你得到一个长度为13字节的结构体,貌似不是一个很有效的长度。但是,如果你把char d加在char b的后面,那么12会是一个更为合理的答案。
你:为什么编译器不重排结构体中的数据顺序,以便更好的优化内存使用和运行速度?
候选者:确实有一些语言这样做了,但是C/C++没有这样做。
你:如果我在结构体的后面加上char *d,会怎么样?
候选者:你刚才说你的运行时环境是64位,因此一个指针的长度的8个字节。也许struct的长度是20?但是另一种可能是,64位的指针需要在在效率上对齐,因此,代码可能会输出4,1,24?
你:不错。我不关心在我的机器上会得到什么结果,但是我喜欢你的观点以及洞察力J
(未完待续)
第二位候选者表现不错,那么,相比大多数程序员,他还有什么潜力没有被挖掘呢?
可以从以下几个角度去考察:
有关平台的问题—32位与64位的编程经验;
内存对齐;
CPU以及内存优化;
C语言的精髓;
接下来,主要分享一下以下相关内容:
内存模型;
优化;
C语言之精髓;
内存模型:
静态存储区(static storage):如果一个对象的标识符被声明为具有内部链接或是外部链接,或是存储类型说明符是static,那么这个对象具有静态生存期。这个对象的生命周期是整个程序的运行周期。
PS:内部链接,也就是编译单元内可见,是需要使用static来修饰的,连接程序不可见;外部链接,是指别的编译单元可见,也就是链接程序可见。我这里还不太清楚为什么需要三种情况来说明。
- int* immortal(void)
- {
- static int storage = 42;
- return &storage;
- }
自动存储区(automatic storage):如果一个对象没有被指明是内部链接还是外部链接,并且也没有static修饰,那么,这个对象具有自动生存期,也称之为本地生存期。一般使用auto说明符来修饰,只在块内的变量声明中允许使用,这样是默认的情况,因此,很少看到auto说明符。简单地说,自动存储区的变量,在一对{}之间有效。
- int* zombie(void)
- {
- auto int storage = 42;
- return &storage;
- }
分配的存储区域(allocated storage):调用calloc函数,malloc函数,realloc函数分配的内存,称之为分配的存储区域。他们的作用域(生命周期会是更好的术语吗?)在分配和释放之间。
- int* finite(void)
- {
- int* ptr = malloc(sizeof(int*));
- *ptr = 42;
- return ptr;
- }
优化相关:
一般来说,编译的时候,你都应该打开优化选项。强制编译器更努力的去发现更多的潜在的问题。

上面,同样地代码,打开优化选项的编译器得到了警告信息:a 没有初始化。
C语言的精髓:
C语言的精髓体现在很多方面,但其本质在于一种社区情感(communitysentiment),这种社区情感建立在C语言的基本原则之上。
C语言原理简介:
1、 相信程序员;
2、 保持语言简单精炼;
3、 对每一种操作,仅提供一种方法;(译者注:?)
4、 尽可能的快,但不保证兼容性;
5、 保持概念上的简单;
6、 不阻止程序员做他们需要做的事。
现在来考察一下我们的候选者关于C++的知识:)
你:1到10分,你觉得你对C++的理解可以打几分?
第一个候选者:我觉得我可以打8到9分。
第二个候选者:4分,最多也就5分了。我还需要多加学习C++。
这时,C++之父Bjarne Stroustrup在远方传来声音:我觉得我可以打7分。(OH,MY GOD!!)
那么,下面的代码段,会输出什么?
- #include <iostream>
- struct X
- {
- int a;
- char b;
- int c;
- };
- int main(void)
- {
- std::cout << sizeof(X) << std::endl;
- }
第二个候选者:这个结构体是一个朴素的结构体(POD:plain old data),C++标准保证在使用POD的时候,和C语言没有任何区别。因此,在你的机器上(64位机器,运行在32位兼容模式下),我觉得会输出12.
顺便说一下,使用func(void)而不是用func()显得有点诡异,因为C++中,void是默认情况,这个相对于C语言的默认是任意多的参数,是不一样的。这个规则同样适用于main函数。当然,这不会带来什么伤害。但这样的代码,看起来就像是顽固的C程序员在痛苦的学习C++的时候所写的。下面的代码,看起来更像C++:
- #include <iostream>
- struct X
- {
- int a;
- char b;
- int c;
- };
- int main()
- {
- std::cout << sizeof(X) << std::endl;
- }
第一个候选者:这个程序会打印12.
你:好。如果我添加一个成员函数,会怎么样?比如:
- #include <iostream>
- struct X
- {
- int a;
- char b;
- int c;
- void set_value(int v) { a = v; }
- };
- int main()
- {
- std::cout << sizeof(X) << std::endl;
- }
第一个候选者:啊?C++中可以这样做吗?我觉得你应该使用类(class)。
你:C++中,class和struct有什么区别?
候选者:在一个class中,你可以有成员函数,但是我不认为在struct中可以拥有成员函数。莫非可以?难道是默认的访问权限不同?(Is it the default visibility that is different?)
不管怎样,现在程序会输出16.因为,会有一个指针指向这个成员函数。
你:真的?如果我多增加两个函数呢?比如:
- #include <iostream>
- struct X
- {
- int a;
- char b;
- int c;
- void set_value(int v) { a = v; }
- int get_value() { return a; }
- void increase_value() { a++; }
- };
- int main()
- {
- std::cout << sizeof(X) << std::endl;
- }
第一个候选者:我觉得对打印24,多了两个指针?
你:在我的机器上,打印的值比24小。
候选者:啊!对了,当然,这个struct有一个函数指针的表,因此他仅仅需要一个指向这个表的指针!我确实对此有一个很深的理解,我差点忘记了,呵呵。
你:事实上,在我的机器上,这段代码输出了12.
候选者心里犯嘀咕:哦?可能是某些诡异的优化措施在捣鬼,可能是因为这些函数永远不会被调用。
你对第二个候选者说:你怎么想的?
第二个候选者:在你的机器上?我觉得还是12?
你:好,为什么?
候选者:因为以这种方式来增加成员函数,不会增加struct的所占内存的大小。对象对他的函数一无所知,反过来,是函数知道他具体属于哪一个对象。如果你把这写成C语言的形式,就会变得明朗起来了。
你:你是指这样的?
- struct X
- {
- int a;
- char b;
- int c;
- };
- void set_value(struct X* this, int v) { this->a = v; }
- int get_value(struct X* this) { return this->a; }
- void increase_value(struct X* this) { this->a++; }
第二个候选者:恩。就想这样的。现在很明显很看出,类似这样的函数是不会增加类型和对象的内存大小的。
你:那么现在呢?
- #include <iostream>
- struct X
- {
- int a;
- char b;
- int c;
- virtual void set_value(int v) { a = v; }
- int get_value() { return a; }
- void increase_value() { a++; }
- };
- int main()
- {
- std::cout << sizeof(X) << std::endl;
- }
//注意改变:第一个成员函数变成了虚函数。
第二个候选者:类型所占用的内存大小很有可能会增加。C++标准没有详细说明虚类(virtual class)和重载(overriding)具体如何实现。但是一般都是维护一个虚函数表,因此你需要一个指针指向这个虚函数表。所以,这种情况下会增加8字节。这个程序是输出20吗?
你:我运行这段程序的时候,得到了24.
候选者:别担心。极有可能是某些额外的填充,以便对齐指针类型(之前说的内存对齐问题)。
你:不错。再改一下代码。
- #include <iostream>
- struct X
- {
- int a;
- char b;
- int c;
- virtual void set_value(int v) { a = v; }
- virtual int get_value() { return a; }
- virtual void increase_value() { a++; }
- };
- int main()
- {
- std::cout << sizeof(X) << std::endl;
- }
现在会发生什么?
第二个候选者:依旧打印24.每一个类,只有一个虚函数表指针的。
你:恩。什么是虚函数表?
候选者:在C++中,一般使用虚函数表技术来支持多态性。它基本上就是函数调用的跳转表(jump table),依靠虚函数表,在继承体系中,你可以实现函数的重载。
让我们来看看另一段代码:
- #include "B.hpp"
- class A {
- public:
- A(int sz) { sz_ = sz; v = new B[sz_]; }
- ~A() { delete v; }
- //...
- private:
- //...
- B* v;
- int sz_;
- };
看看这段代码。假设我是一名资深的C++程序员,现在要加入你的团队。我向你提交了这么个代码段。请从学术的层面,尽可能详细轻柔的给我讲解这段代码可能存在的陷阱,尽可能的跟我说说一些C++的处理事情的方式。
第一个候选者:这是一段比较差的代码。这是你的代码?首先,不要使用两个空格来表示缩进。还有class A后面的大括号要另起一行。sz_?我从来没见过如此命名的。你应该参照GoF标准_sz或且微软标准m_sz来命名。(GoF标准?)
你:还有呢?
候选者:恩?你是不是觉得在释放一个数组对象的时候,应该使用delete []来取代delete?说真的,我的经验告诉我,没必要。现代的编译器可以很好的处理这个事情。
你:好?有考虑过C++的“rule of three“原则吗?你需要支持或是不允许复制这一类对象吗?
PS:
(来自维奇百科http://en.wikipedia.org/wiki/Rule_of_three_(C%2B%2B_programming))
The rule of three (also known asthe Law of The Big Three or The Big Three) is a rule of thumb in C++ that claimsthat if a class defines one of the following itshould probably explicitly define all three:
§ destructor
§ copy constructor
§ assignment operator
也就是说,在C++中,如果需要显式定义析构函数、拷贝构造函数、赋值操作符中的一个,那么通常也会需要显式定义余下的两个。
第一个候选者:恩。无所谓了。听都没听说过tree-rule。当然,如果用户要拷贝这一类对象的话,会出现问题。但是,这也许就是C++的本质,给程序员无穷尽的噩梦。
顺便说一下,我想你应该知道哎C++中所有的析构函数都应该定义为virtual函数。我在一些书上看到过这个原则,这主要是为了防止在析构子类对象时候出现内存泄露。
你心里嘀咕:或是类似的玩意。Another ice cream perhaps?(我还是没搞明白这到底哪门情感)
令人愉悦的第二个候选者登场了:)
候选者:哦,我该从何说起呢?先关注一些比较重要的东西吧。
首先是析构函数。如果你使用了操作符new[],那么你就应该使用操作符delete[]进行析构。使用操作符delete[]的话,在数组中的每一个对象的析构函数被调用以后,所占用的内存会被释放。例如,如果像上面的代码那样写的话,B类的构造函数会被执行sz次,但是析构函数仅仅被调用1次。这个时候,如果B类的构造函数动态分配了内存,那么就是造成内存泄漏。
接下类,会谈到“rule of three”。如果你需要析构函数,那么你可能要么实现要么显式禁止拷贝构造函数和赋值操作符。由编译器生成的这两者中任何一个,很大可能不能正常工作。
还有一个小问题,但是也很重要。通常使用成员初始化列表来初始化一个对象。在上面的例子中,还体现不出来这样做的重要性。但是当成员对象比较复杂的时候,相比让对象隐式地使用默认值来初始化成员,然后在进行赋值操作来说,使用初始化列表显式初始化成员更为合理。
先把代码修改一下:)然后再进一步阐述问题。
你改善了一下代码,如下:
- #include "B.hpp"
- class A
- {
- public:
- A(int sz) { sz_ = sz; v = new B[sz_]; }
- ~A() { delete[] v; }
- //...
- private:
- A(const A&);
- A& operator=(const A&);
- //...
- B* v;
- int sz_;
- };
这个时候,这位候选者(第二个)说:好多了。
你进一步改进,如下:
- #include "B.hpp"
- class A
- {
- public:
- A(int sz) { sz_ = sz; v = new B[sz_]; }
- virtual ~A() { delete[] v; }
- //...
- private:
- A(const A&);
- A& operator=(const A&);
- //...
- B* v;
- int sz_;
- };
第二位候选者忙说道:别着急,耐心点。
接着他说:在这样的一个类中,定义一个virtual的析构函数,有什么意义?这里没有虚函数,因此,如果以此作为基类,派生出一个类,有点不可理喻。我知道是有一些程序员把非虚类作为基类来设计继承体系,但是我真的觉得他们误解了面向对象技术的一个关键点。我建议你析构函数的virtual说明符去掉。virtual这个关键字,用在析构函数上的时候,他有这么个作用:指示这个class是否被设计成一个基类。存在virtual,那么表明这个class应该作为一个基类,那么这个class应该是一个virtual class。
还是改一下初始化列表的问题吧:)
于是代码被你修改为如下:
- #include "B.hpp"
- class A
- {
- public:
- A(int sz):sz_(sz), v(new B[sz_]) { }
- ~A() { delete[] v; }
- //...
- private:
- A(const A&);
- A& operator=(const A&);
- //...
- B* v;
- int sz_;
- };
第二个候选者说:恩,有了初始化列表。但是,你有没有注意到由此有产生了新的问题?
你编译的时候使用了-Wall选项吗?你应该使用-Wextra、-pedantic还有-Weffc++选项。如果没有警告出现,你可能没有注意到这里发生的错误。但是如果你提高了警告级别,你会发现问题不少。
一个不错的经验法则是:总是按照成员被定义的顺序来书写初始化列表,也就是说,成员按照自己被定义的顺序来呗初始化。在这个例子中,当v(new B[sz_])执行的时候,sz_还没有被定义。然后,sz_被初始化为sz。
事实上,C++代码中,类似的事情太常见了。
你于是把代码修改为:
- #include "B.hpp"
- class A
- {
- public:
- A(int sz):v(new B[sz]), sz_(sz) { }
- ~A() { delete[] v; }
- //...
- private:
- A(const A&);
- A& operator=(const A&);
- //...
- B* v;
- int sz_;
- };
第二个候选者:现在好多了。还有什么需要改进的吗?接下来我会提到一些小问题。。。
在C++代码中,看到一个光秃秃的指针,不是一个好的迹象。很多好的C++程序员都会尽可能的避免这样使用指针。当然,例子中的v看起来有点像STL中的vector,或且差不多类似于此的东西。
对于你的私有变量,你貌似使用了一些不同的命名约定。在此,我的看法是,只要这些变量是私有的,你爱怎么命名就怎么命名。你可以使得你的变量全部以_作为后缀,或且遵循微软命名规范,m_作为前缀。但是,请你不要使用_作为前缀来命名你的变量,以免和C语言保留的命名规范、Posix以及编译器的命名规则相混淆:)
(未完待续)
总结一下第三讲,我们可以知道,相对于第一位候选者,第二位候选者在以下几个方面有更深的认识:
1、 C与C++的联系;
2、 多态方面的技术;
3、 如何正确的初始化一个对象;
4、 Rule of three;
5、 操作符new[]与操作符delete[]方面的知识;
6、 常用的命名约定。
接下来,我们将分享一下几个方面的知识:
1、 对象的生命周期;
2、 Rule of three;
3、 虚函数表。
先来看,恰当地进行对象初始化。赋值与初始化是不一样的。来看这段代码的输出:
- struct A
- {
- A() { puts("A()"); }
- A(int v) { puts("A(int)"); }
- ~A() { puts("~A()"); }
- };
- struct X
- {
- X(int v) { a = v; }
- X(long v):a(v) { }
- A a;
- };
- int main()
- {
- puts("bad style");
- {
- X slow(int(2));
- }
- puts("good style");
- {
- X fast(long(2));
- }
- }
代码输出为:
- bad style
- A()
- A(int)
- ~A()
- ~A()
- good style
- A(int)
- ~A()
再看看对象的生命周期:
C++的一个基本原理是:对象消亡时候需要采取的操作,正好是对象创建时候所采取操作的逆操作。
看下面的代码:
- struct A
- {
- A() { puts("A()"); }
- ~A() { puts("~A()"); }
- };
- struct B
- {
- B() { puts("B()"); }
- ~B() { puts("~B()"); }
- };
- struct C
- {
- A a;
- B b;
- };
- int main()
- {
- C obj;
- }
程序的输出是:
- A()
- B()
- ~B()
- ~A()
再看:
- struct A
- {
- A():id(count++)
- {
- printf("A(%d)\n", id);
- }
- ~A()
- {
- printf("~A(%d)\n", id);
- }
- int id;
- static int count;
- };
- //原文是没有这句的,不过根据C++规范,static数据成员必须在类定义体外定义。
- //谢谢yuxq100指出。
- int A::count = 0;
- int main()
- {
- A array[4];
- }
程序输出:
- A(0)
- A(1)
- A(2)
- A(3)
- ~A(3)
- ~A(2)
- ~A(1)
- ~A(0)
仔细看着张图,也会有所收获:
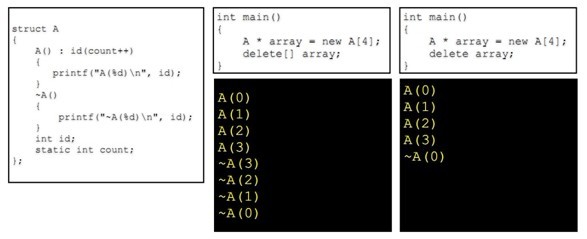
接下来看看:the rule of three:
If a class defines a copy constructor, acopy assignment operator, or a destructor, then it should define all three.
如果一个类定义了拷贝构造函数、赋值操作符、析构函数中的一个,那么通常需要全部定义这仨函数。
如图示:

接下类看看虚函数表:
看一下这段代码,虚函数表的结构大概如何呢?
- struct base
- {
- virtual void f();
- virtual void g();
- int a,b;
- };
- struct derived:base
- {
- virtual void g();
- virtual void h();
- int c;
- };
- void poly(base* ptr)
- {
- ptr->f();
- ptr->g();
- }
- int main()
- {
- poly(&base());
- poly(&derived());
- }
虚函数表结构如何呢?看图:
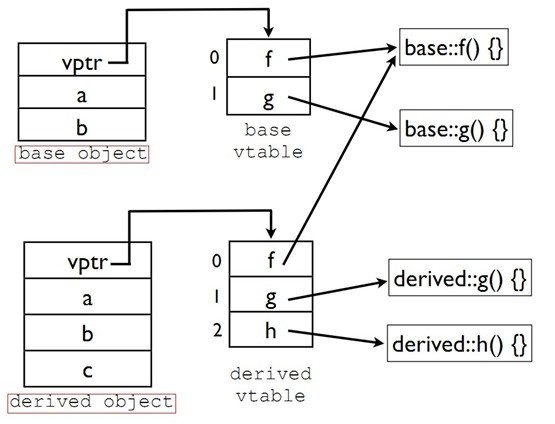
简单说明:派生类没有重载f函数,它继承了基类的f函数,因此,派生类的虚函数表的f函数指向基类的f函数。但是,因为派生类重载了g函数,因此,其虚函数表中的g指向自身的g函数。
那么这段代码呢?
- struct base
- {
- void f();
- virtual void g();
- int a,b;
- };
- struct derived:base
- {
- virtual void g();
- virtual void h();
- int c;
- };
- void poly(base* ptr)
- {
- ptr->f();
- ptr->g();
- }
- int main()
- {
- poly(&base());
- poly(&derived());
- }
基类的f函数不是虚函数了,这个时候的虚函数表结构又如何呢?
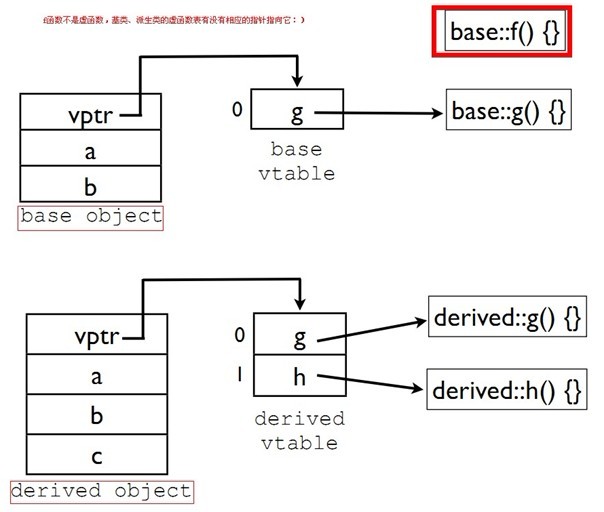
越多的同事对他们所使用的语言有深入的认识,这对你有什么好处吗?我们不建议(也不实际)要求公司里所有的C/C++程序员都深入理解C/C++。但是你确实需要绝大部分的程序员真的在意他们的专业度,他们需要求知若渴,不断努力,争取不断的加深对语言本身的理解。正所谓:stay hungry,stay foolish:)
现在回过头了看着这两名开发者,也就是我们之前所一直说的候选者。
亲,你觉得这两名开发者之间最大的差别在哪?
关于语言的现有知识吗? 不是!!
是他们对于学习的态度!!
你最后一次上编程方面的课程是什么时候?
第一个候选者这样回答:你什么意思?我在大学里学习编程,现在我通过实践来学习。你想知道什么?
你:那么,你现在在阅读哪些书?
候选者:书?哦,我不需要书。在我需要的时候,我会在网上查询手册。
你:你会跟你的同事谈论编程方面的东西吗?
候选者:我觉得没有必要!!我比他们强多了,从他们身上学不到任何玩意!!
你貌似对C/C++了解的更多,怎么做到的?
第二个候选者:我每天都会学习一些新东西,我真的乐在其中:)
我偶尔也会在stackoverflow.com、comp.lang.c还有comp.lang.c++跟进一些讨论。
我还参加了一个当地的C/C++用户组,我们定期会举行一些讨论会,交流心得。
我看了很多的书,很多很多。你知道吗?James Grenning刚刚写了一本很不错的书:《Test-Driven Development in C》,很值得一看:)
[PS:貌似是:Test-DrivenDevelopment for Embedded C]
我偶尔会被允许拜访WG14W以及G21。
[PS:
ISO WG14:ISO C委员会,具体指JTC1/SC22/WG14 C语言技术工作小组,通常简写为WG14。 ISO WG21:ISO C++委员会,具体指JTC1/SC22/WG21 C++技术工作小组,通常简写成WG21。
此人很牛逼呀:)]
我还是ACCU的会员,这里的人对于编程都有专业精神。我订阅了Overload,CVu及accu的一些综述文章。
[PS:移步看看ACCU的网站,确实应该去看看:
ACCU is an organisation of programmers whocare about professionalism in programming and are dedicated to raising thestandard of programming.
]
候选者接着说:无论何时只要有有机会,我都会参加C/C++课程,倒不是因为跟老师能学到什么东西,而是因为通过和其他同学的讨论,能扩展我的知识面。
但也许最好的知识来源于密切地配合我的同事们工作,与他们交流,分享自己所知的同时,从他们身上学到更多的知识。
(我表示从第二个候选者那学到了很多东西:)
最后,概述:
l 编译器和链接器(连接程序)
l 声明和定义
l 活动帧
l 内存段
l 内存对齐
l 序点
l 求值顺序
l 未定义和未指定
l 优化
l 关于C++的一些玩意
l 对象的恰当初始化
l 对象的生命周期
l 虚函数表
l 以及一些关于专业精神和学习态度的话题
这个时候第一个候选者貌似有所领悟:
第一个候选者:啊?
你:有什么问题吗?
候选者:我真的热爱编程,但是我现在认识到我真的还远远说不上专业。对于如何更好的学习C/C++,您能给我一些建议吗?
你:首先,你必须认识到编程是一件持续学习的的过程。不管你掌握了多少,总有很多知识需要你去学习。其次,你还必须认识到,专业编程最重要的一点是,你必须和你的同事亲密合作。想想体育比赛中,没有人可以做到单凭个人就能赢得比赛。
候选者:好的,我需要好好反省。。。
你:但是话说回来,养成这么个习惯,偶尔去关注一下代码所生成的汇编语句。你会发现很多有意思的东西。使用debugger,一步步的跟踪你的代码,看看内存的使用情况,同时看看处理器到底在执行什么指令。
候选者:有什么关于C/C++的书、网站、课程或是会议值得推荐吗?
你:要学习更多的现代软件的开发方式,我推荐James Grenning写的Test-Driven Development for Embedded C(貌似还没有中文版)。想要更深入的学习C语言,可以参考Peter van/Der Linden的Expert C Programming(C专家编程),这本书虽然成作已经20多年了,但是书上的观点依然管用。对于C++,我推荐你从Scott Meyers的Effective C++(国内侯捷老师翻译了此书)以及Herb Sutter 和Andrei Alexandrescu的C++ coding standards(C++编程规范)。
此外,如果你有机会参加任何于此有关的课程,不要犹豫,参加!只要态度正确,你就可以从老师和其他学生那里学到很多东西。
最后,我建议加入一些C/C++的用户组织,投身于社区当中。具体来说,我非常推荐ACCU,他们很专注于C/C++编程。你知道吗?他们每年的春季都会在牛津大学举行为期一周的与此相关的会议,与会者是来自全世界专业程序员:)或许明年4月份我会在那遇见你?
候选者:谢谢:)
你:祝你好运:)
全文完。
其他参考:














 553
553











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









