







Reading Paper for Pedestrian detection 3.22-3.27
Pedestrian Detection:An Evaluation of the State of the Art
- 影响检测性能主要原因:低分辨率、重度遮挡、低尺度、False Positive Rate
- 主流dataset: INRIA, ETH, TUD-Brussels, Daimler-CB, Caltech-USA, KITTI
- 针对Caltech数据集:行人遮挡集中成几种套路;行人分布集中于图像中部一个狭长带区,导致限制检测位置和遮挡模型可适当加快检测速度
- 评价指标log-average miss rate VS FPPI(false positives per image)
- Per window和Full image性能对比
- 三种数据过滤方法:strict, post and expanded
- Bounding box 使用标准纵横比,三次插值获取, 高度依赖于“相机与行人的距离”和“实际高度”,宽度依赖于“肢体的姿势位置”
- 引入Dataset-Algorithm performance matrix评价效果 (Friedman test/Shaffer test)
- Speed up Method:检测器本身、使用近似、依赖硬件(GPU)
- 可能的研究方向:尺度、遮挡、运动特征、时间特征、上下文信息、新颖的特征、数据
The Fastest Pedestrian Detector in the West
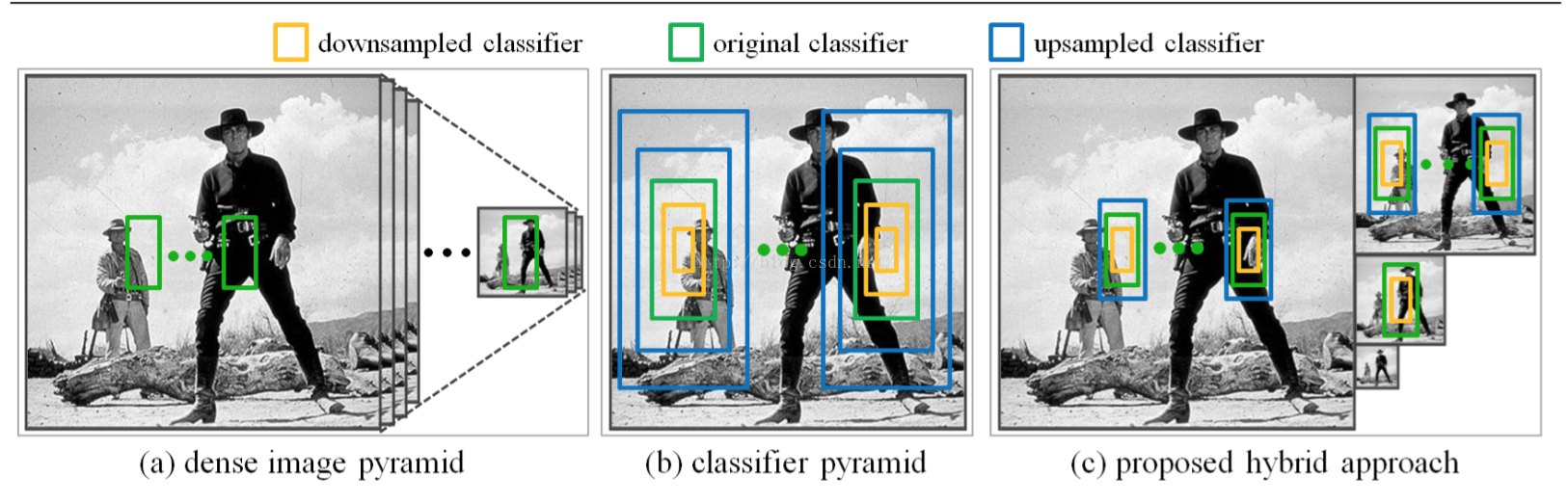
- 核心思想: For a broad family of features, including gradient histograms, the feature responses computed at a single scale can be used to approximate feature responses at nearby scales.
- 总结使用技巧:multiple scales、sparsely sampled image pyramid、a step size of an entire octave、each octave we use a classifier pyramid
Taking a Deeper Look at Pedestrians
- 比较几个应用Deep neural network处理Pedestrian detection task的例子:
ConvNet:集中处理有限的数据;同时使用来自最后一层和倒数第二层的特征
DBN-Isol:用RBMs扩展DPM来试图解决部分和遮挡问题
DBM-Mut:Account for person-to-person relations
JointDeep:联合优化的传统特征、DPM和DBM-Mut的person-to-person relations
MultiSDP:在每层中融合不同尺度的行人检测候选集的上下文信息
SDN:使用“switchable layers”自动学习low-level features和high-level parts
- 修改网络结构和参数的方面:Detection proposals,Thresholds for positive and negative samples,Model window size,Training batch,Number and size of cone filters,Number and type of layers等
- 基于 CafirNet 训练small convnet(105parameters),基于 AlexNet 训练big convnet(107parameters)
- 比较结果:On Caltech10x, we find the CifarNet performance improved to 28.4%, while the AlexNet improves to 27.1% MR;运行时间上per proposal window用时3ms,每张图少于100个检测窗,总用时每张图300ms,相比较SquaresChnFtrs每张图用时2s。
How Far are We from Solving Pedestrian Detection
- 基于 CafirNet 训练small convnet(105 parameters),基于 AlexNet 训练big convnet(107 parameters)
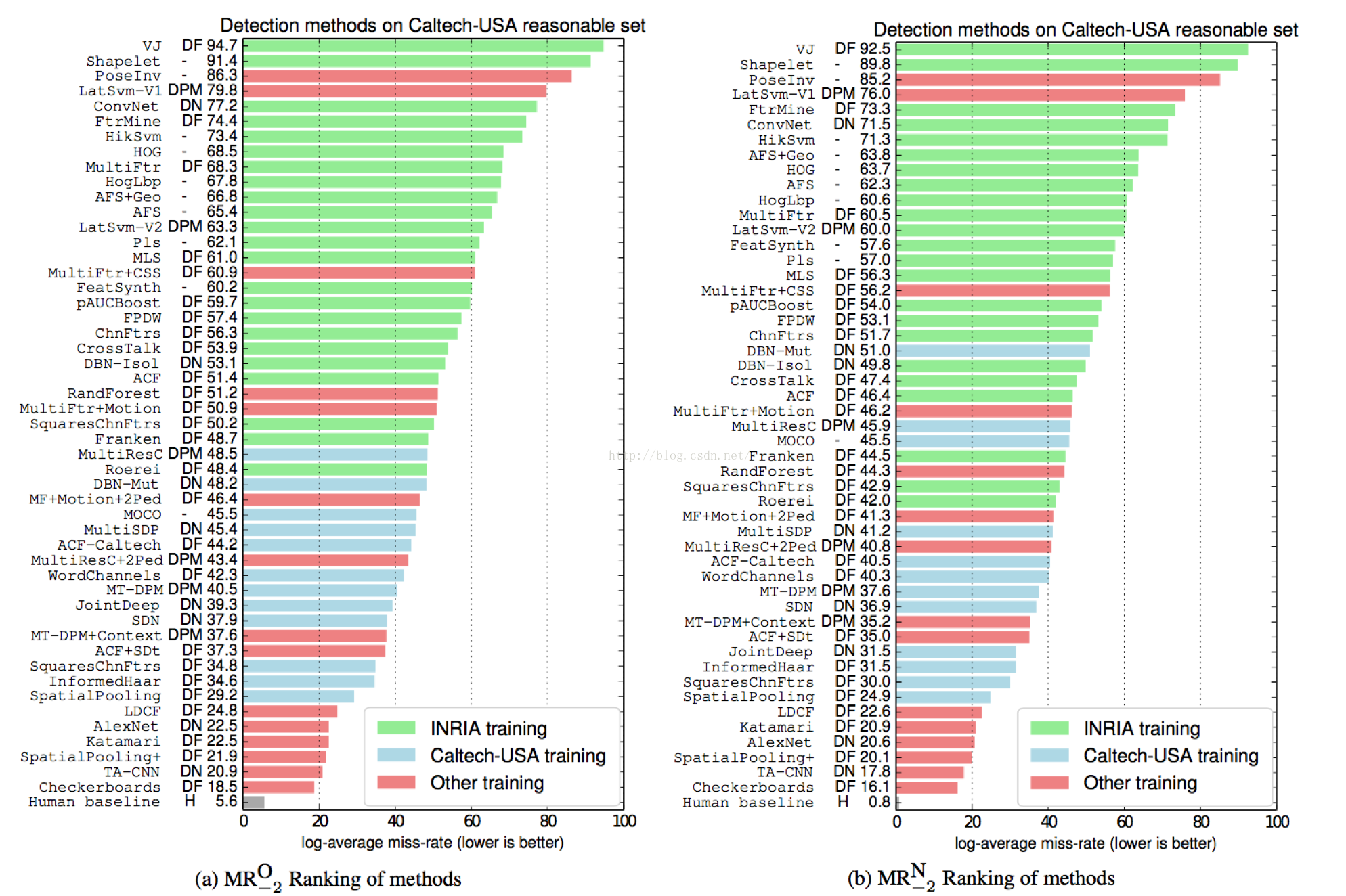
- 主要工作:给出了human baseline for the Caltech Benchmark,证实行人检测仍有十倍的提升空间,但同时出“the last 20%”更难挑战;提出了当前的state-of-the-art method和完美的单帧单眼检测器RotatedFilters,取得最佳性能;讨论了影响性能的主要因素:background-versus-foreground and localization。
- 改进了Caltech dataset的Pedestrian bounding box绘制原则:A bounding box is then automatically generated such that its centre coincides with the centre point of the manually-drawn axis.
- 分析了影响训练标注的两点:Pruning benefits 和 Alignment benefits
- 某些时候convnets会给TP样本周围的窗赋值以低分,despite their fine-tuning, the convnet score maps are “blurrier” than the proposal ones. 作者认为导致这一现象的原因是诸如AlexNet和VGG有一些结构限制如internal feature pooling。
- 基于语义标注和边界估计的方法需要pixel-accurate output;可以通过bounding box regression来弥补卷积网络空间分辨率不足的情况。
- 个人觉得分析误差来源时提到用去除训练和测试集中的false positive的方法来提升性能很扯。觉得不对者详见论文。
- 记录一些State-of-the-art(在某时刻曾是)及其算法思想,见图
- 更多实验细节和调参方法详见论文及补充材料。














 2797
2797











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









