







前几天参加了阿里暑期实习的内推面试,发现自己的数据结构算法基础特别薄弱,比如其中一个问题是中序遍历的递归与非递归算法,我平时看数据结构只知道递归算法,非递归的算法直接被问懵逼了,在思考了几十秒之后想出了用数组存放每次遍历节点的父节点,然后用for循环遍历,虽然可以实现,但是我觉得面试官听到之后估计在吐血,还有HashMap底层自己明明知道用的是散列表,在紧张之下我竟然说是数组,面完之后被舍友吐槽,所以下定决心好好把算法基础打扎实了,虽然面试的不怎么样,但是能够知道自己的数据结构基础太薄弱了还是有收获的。
这篇博文主要是研究前序遍历的递归与非递归算法,后面还会慢慢有中序和后序的递归与非递归算法。
之前看的关于数据结构的书籍,在二叉树那一章的前序遍历主要讲的是递归算法,在这里也复习一下
先初始化二叉树
public TreeNode initTree(){
TreeNode G = new TreeNode("G", null, null);
TreeNode H = new TreeNode("H", null, null);
TreeNode D = new TreeNode("D", G, H);
TreeNode B = new TreeNode("B", D, null);
TreeNode I = new TreeNode("I", null, null);
TreeNode E = new TreeNode("E", null, I);
TreeNode F = new TreeNode("F", null, null);
TreeNode C = new TreeNode("C", E, F);
TreeNode A = new TreeNode("A", B, C);
return A;
}得到如下图的二叉树

再进行二叉树的前序递归遍历
public void preOrderTraverse(TreeNode T){ //前序遍历递归算法
if(T==null){
return;
}
System.out.println(T.data); //对节点进行处理,这里用输出代替处理
preOrderTraverse(T.lchild);
preOrderTraverse(T.rchild);
}运行结果如下
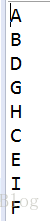
以上是前序递归遍历,代码简洁,如果对递归算法理解透彻的话,前序递归遍历很好理解,这里就不做过多阐述。虽然递归遍历简单和好理解,但是面对海量数据的时候,由于递归算法需要创建很多对象,需要占用大量内存,使得空间复杂度极大,也容易造成堆栈的溢出,因此递归算法面对海量数据时还是有非常致命的缺陷,下面探究一下前序遍历的非递归算法。
当用非递归遍历时,我们不能够像递归遍历那样调用自己的方法来访问子节点,那怎么办呢?第一个出现在脑海中的想法便是用循环是遍历每一个节点,但是当遍历到叶子节点的时候我们需要回到前面遍历之前没有遍历到的右节点,这可怎么办?当初在面试的时候因为就给了几十秒的时间有点紧张,所以想出了用数组存储每次遍历后的节点的父节点,但其实二叉树的前序遍历有个特点就是遍历到左叶子节点的时候需要回头再去遍历之前未遍历到的右节点,这个特点刚好和栈的先进后出的特点很相符,所以应该改用栈来存储未遍历到的右节点
代码如下
public void preOrderWithoutRecursion(TreeNode T){ //前序遍历非递归算法
TreeNode p;
Stack<TreeNode> stack = new Stack<TreeNode>();
stack.push(T); //先将根节点压进栈中
while(T!=null&&!stack.empty()){
p = stack.pop(); //弹出栈顶的节点赋给p
System.out.println(p.data); //用输出来代替对节点的处理
if(p.rchild!=null){
stack.push(p.rchild); //如果弹出节点的右孩子不为空则压入栈
} //注意,这里的重点是一定要先将右孩子压入栈,再将左孩子压入
if(p.lchild!=null){
stack.push(p.lchild); //如果弹出节点的左孩子不为空则压入栈
}
}
}输出结果为
与递归的算法结果一样
虽然非递归算法的代码量比递归稍多了一点,但是对于海量数据来说非递归算法的空间复杂度远低于递归算法,也不容易造成堆栈溢出。














 4126
4126











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









