






目录
之前对各个优化器理解的不是特别清晰,最近通过分析,列出一个表格来对比他们之间的异同点。
首先通过列表的方式逐个介绍每个优化器,并做出评价。然后再汇总所有优化器,进行宏观上的比较。
因为公式较多,所以我在word上先编辑好,然后截图过来。
以下文件的下载路径:深度学习优化算法介绍汇总与对比分析.rar 或 优化算法汇总与对比分析.rar。两者内容一致,前者包含pdf,excel,word, 后者仅仅包含pdf文件。
1. 逐个介绍优化器:
文中的符号表示与优化器原论文中不同,主要为了保持本综述的符号一致性。而且,个人认为,更便于接受。




其中,Adabound我还没有进行仔细分析。以下是该算法流程的放大图:

2. 不同优化器方法的宏观对比分析
2.1 在分析中的参数命名


2.2 不同优化器的列表对比分析
先表达最终结论:
所有优化器都可以看作是对最基本的SGD的优化,优化的思路主要有三个:
- a)用梯度的一阶动量代替梯度作为增量的基量,提升优化算法的速度与鲁棒性。
- b)用梯度的二阶动量或∞范数动量对学习率进行自适应化,使不同参数有不同的学习率。
- c)用增量的二阶动量代替学习率基量,取消对学习率超参数的依赖,并使学习率大小与当前参数的大小量级匹配。
具体汇总分析如下:

2.3 不同优化器的可视化对比分析
1. 不同优化器的优化速度比较。SGD最慢,Adadelta最快,动量法会走一些弯路。
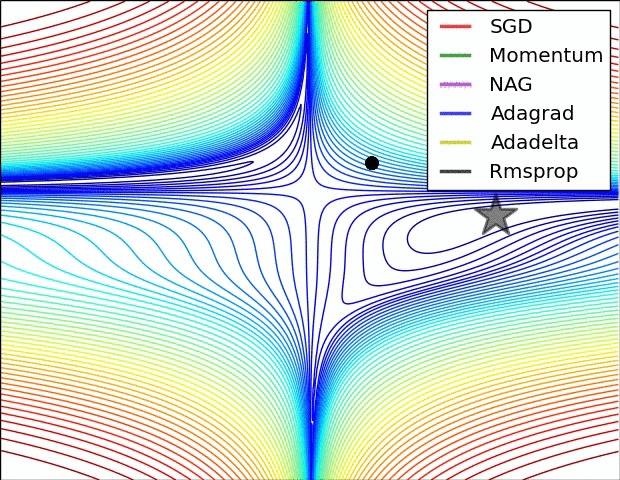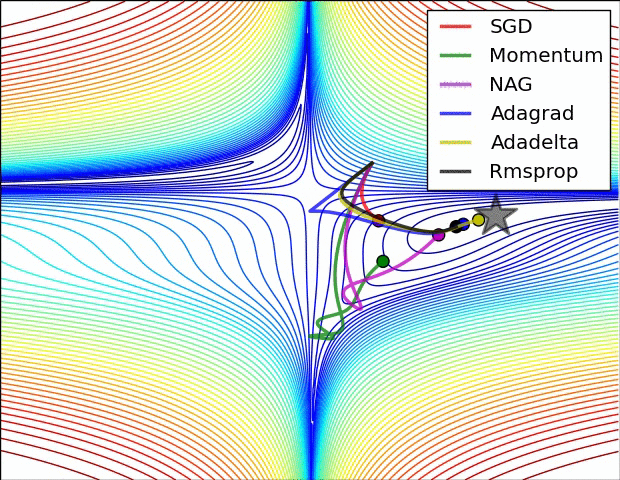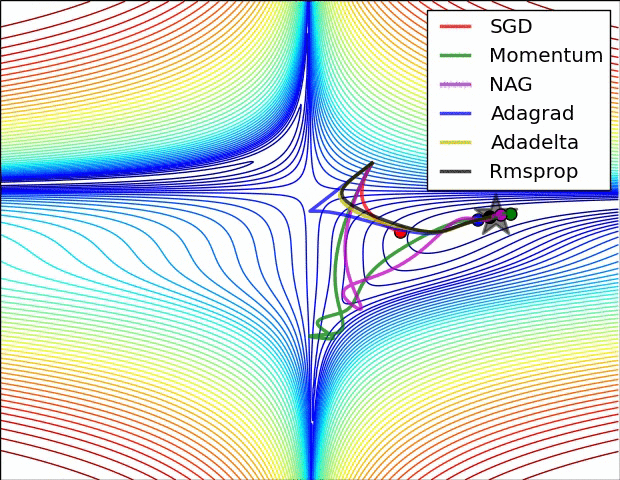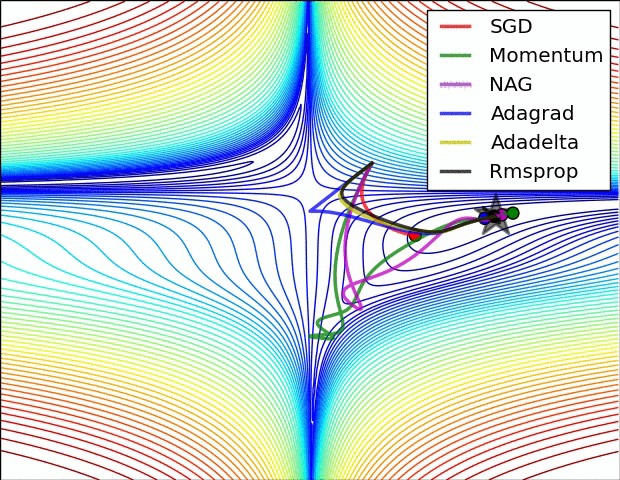
2. 遇到鞍点时不同优化器的反应。SGD会被困于鞍点,动量法会在鞍点耽误较长时间。Adadelta脱离速度最快,优化也最快。Rmsprop次之。
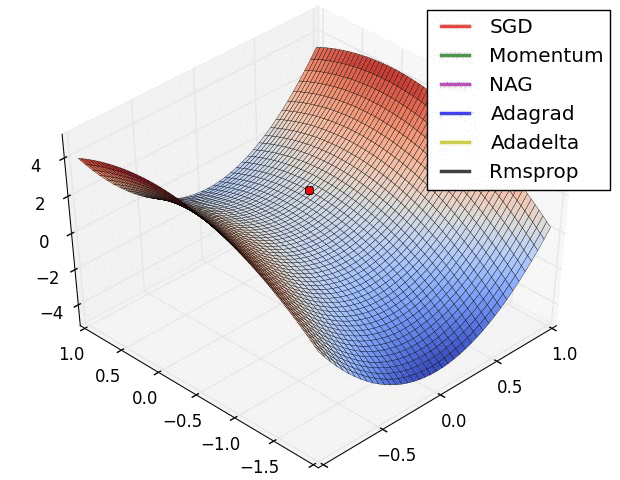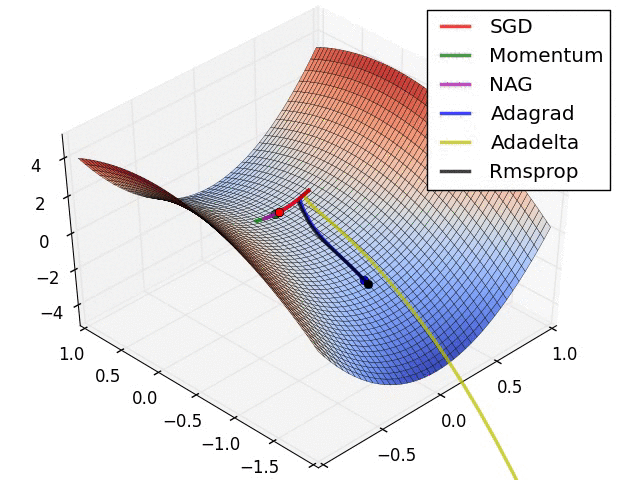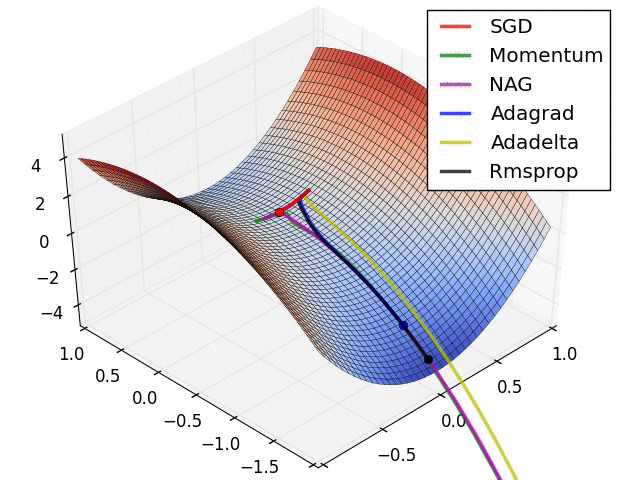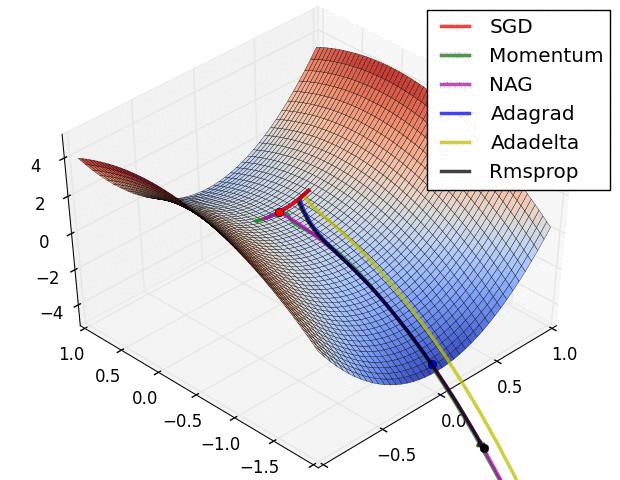
3. 动量对梯度下降的影响
















 13万+
13万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









