







 本文介绍如何利用HTML中的input标签实现文件上传功能,并详细解释了如何通过设置不同的属性来实现拍照、录制视频和录音等功能。此外,还提供了一个样例代码,展示了如何美化文件选择按钮并预览所选图片。
本文介绍如何利用HTML中的input标签实现文件上传功能,并详细解释了如何通过设置不同的属性来实现拍照、录制视频和录音等功能。此外,还提供了一个样例代码,展示了如何美化文件选择按钮并预览所选图片。
最近用MUI做了个移动端项目,设计中涉及到调用手机摄像头拍照等功能需求,然而在PLUS环境下才能直接调用,这就让人有点头疼了,后经查询资料学习了解到有一个很简单的方法就是input:file标签,不需要复杂代码操作就能实现调用拍照、相册等功能。
//capture -- 设置选择需要调用的功能
//camera -- 照相机
//camcorder -- 摄像机
//microphone -- 录音
//accept -- 直接打开系统文件目录
<input type="file" accept="image/*" capture="camera">
<input type="file" accept="video/*" capture="camcorder">
<input type="file" accept="audio/*" capture="microphone">
//input:file标签还有一个属性multiple 用来支持多选 直接呼出原生选项
<input type="file" accept="image/*" multiple>input [ type=file ] 按钮美化及上传demo
简单说就是:先将原按钮透明度opacity设为0,再外层用标签包裹,最终实现美化功能。
<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<title> <input[type=file]>上传demo </title>
<style>
.file {
position: relative;
display: inline-block;
background: #D0EEFF;
border: 1px solid #99D3F5;
border-radius: 4px;
padding: 4px 12px;
overflow: hidden;
color: #1E88C7;
text-decoration: none;
text-indent: 0;
line-height: 20px;
}
.file input {
position: absolute;
font-size: 100px;
right: 0;
top: 0;
opacity: 0;
}
.file:hover {
background: #AADFFD;
border-color: #78C3F3;
color: #004974;
text-decoration: none;
}
p.bottomTitlt{
margin: 0;
letter-spacing: 2px;
padding: 0;
}
</style>
</head>
<body>
<a href="javaScript:;" class="file">
<p class="bottomTitlt">身份证正面</p>
<img src="" alt=""/>
<input type="file" placeholder="身份证正面" >
</a>
<p class="showFileName"></p>
<script src="https://code.jquery.com/jquery-3.2.0.min.js"></script>
<script type="text/javascript">
$(".file").on("change","input[type='file']",function(){
var filePath=$(this).val();
var fr= new FileReader();
var imgObj = this.files[0];
fr.readAsDataURL(imgObj);
var obj = $(this).prev()[0];
if(filePath.indexOf("jpg")!=-1 || filePath.indexOf("JPG")!=-1 || filePath.indexOf("PNG")!=-1 || filePath.indexOf("png")!=-1){
var arr = filePath.split('\\');
var fileName = arr[arr.length-1];
$(this).parent().next().html(fileName);
fr.onload=function( ){
obj.src=this.result;
};
}else{
$(this).parent().next().html("您未上传文件,或者您上传文件类型有误!").css("color","red");
return false
}
});
</script>
</body>
</html>input[type=file]样式美化后效果图:
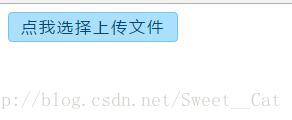
图片上传后效果图:
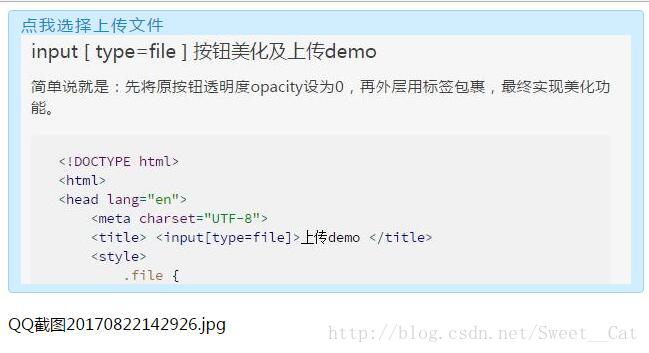

















 1612
1612

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









