










在前面的章节中我们介绍了List,也讨论了List的数据结构和操作函数。List这个东西从外表看上去挺美,但在现实中使用起来却可能很不实在。为什么?有两方面:其一,我们可以发现所有List的操作都是在内存中进行的,要求List中的所有元素都必须在操作时存在于内存里。如果必须针对大型数据集进行List操作的话就明显不切实际了。其二,List的抽象算法如折叠算法、map, flatMap等是无法中途跳出的,无论如何都一直进行到底;只有通过递归算法在才能在中途停止运算。但递归算法不够抽象,经常出现重复的代码。最要命的是递归算法会随着数据量增加堆栈内存占用(non-tail-recursive),处理大型数据集同样不实际。以上缺陷使List的应用被局限在小规模的数据集处理范围。
矛盾的是,List由于内存占用问题不适合大数据集处理,但它的计算模式又是排列数据模式必须的选择。Stream数据类型具备了List的排列数据计算模式但有不需要将全部数据搬到内存里,可以解决以上提到的大数据集处理问题。Stream的特性是通过“延后计算”(lazy evaluation)来实现的。可以想象一下可能的原理:Stream内元素读取是在具体使用时才进行的。不用说,Stream是典型的只读数据类型。既然要继承List的计算模式,那么在结构设计上是否相同呢?我们先看看Stream的结构设计:
trait Stream[+A]
case object Empty extends Stream[Nothing]
case class Cons[+A](head: () => A, tail: () => Stream[A]) extends Stream[A]
天啊,简直是活脱脱的List结构嘛。不过Stream的头元素(head)和无头尾(tail)是延后计算的(non-strict)。由于Cons不是普通函数而是一个类,不容许延后计算类参数,所以传入的是一个函数 () => ???。
以上Stream结构设计与List相同;两种状态是用子类来表示的。以下我们探索以下另外一种设计方案:
trait Stream[+A] {
def uncons: Option[(A, Stream[A])]
def isEmpty: Boolean = uncons.isEmpty
}
object Stream {
def empty[A]: Stream[A] = new Stream[A] {
def uncons = None
}
def cons[A](h: => A, t: => Stream[A]): Stream[A] = new Stream[A] {
def uncons = Some((h,t))
}
def apply[A](as: A*): Stream[A] = {
if (as.isEmpty) empty
else cons(as.head, apply(as.tail: _*))
}
}
以上的设计方案采用了结构封装形式:数据结构uncons,两种状态empty, cons都被封装在类结构里。最起码我们现在可以直接使用=> A 来表达延后计算参数了。
实际上Stream就是对一个List的描述,一个类型的声明。它的实例生成延后到了具体使用的时候,此时需要的元素已经搬入内存,成了货真价实的List了:
//tail recursive
def toList_1: List[A] = {
@annotation.tailrec
def go(s: Stream[A], acc: List[A]): List[A] = {
s.uncons match {
case None => acc
case Some((h,t)) => go(t,h :: acc)
}
}
go(this,Nil).reverse // h :: acc 产生相反顺序
}
//省去reverse
def toListFast: List[A] = {
val buf = new collection.mutable.ListBuffer[A]
@annotation.tailrec
def go(s: Stream[A]): List[A] ={
s.uncons match {
case Some((h,t)) => {
buf += h
go(t)
}
case _ => buf.toList
}
}
go(this)
}Stream(1,2.3) //> res0: ch5.stream.Stream[Double] = ch5.stream$Stream$$anon$2@1e643faf
Stream(1,2,3).toList //> res1: List[Int] = List(1, 2, 3)
Stream(1,2,3).toList_1 //> res2: List[Int] = List(1, 2, 3)
Stream(1,2,3).toListFast //> res3: List[Int] = List(1, 2, 3)
再看看Stream最基本的一些操作函数:
def take(n: Int): Stream[A] = {
if ( n == 0 ) empty
else
uncons match {
case None => empty
case Some((h,t)) => cons(h,t.take(n-1))
}
}
def drop(n: Int): Stream[A] = {
if (n == 0) this
else {
uncons match {
case Some((h,t)) => t.drop(n-1)
case _ => this
}
}
}Stream(1,2,3) take 2 //> res4: ch5.stream.Stream[Int] = ch5.stream$Stream$$anon$2@3dd3bcd
(Stream(1,2,3) take 2).toList //> res5: List[Int] = List(1, 2)
Stream(1,2,3) drop 2 //> res6: ch5.stream.Stream[Int] = ch5.stream$Stream$$anon$2@97e1986
(Stream(1,2,3) drop 2).toList //> res7: List[Int] = List(3)
不过这些操作函数的实现方式与List基本相像:
def takeWhile(f: A => Boolean): Stream[A] = {
uncons match {
case None => empty
case Some((h,t)) => if ( f(h) ) cons(h,t.takeWhile(f)) else empty
}
}
def dropWhile(f: A => Boolean): Stream[A] = {
uncons match {
case None => empty
case Some((h,t)) => if ( f(h) ) t.dropWhile(f) else t
}
}
def headOption: Option[A] = uncons match {
case Some((h,t)) => Some(h)
case _ => None
}
def tail: Stream[A] = uncons match {
case Some((h,t)) => t
case _ => empty
}
(Stream(1,2,3,4,5) takeWhile {_ < 3}).toList //> res8: List[Int] = List(1, 2)
(Stream(1,2,3,4,5) dropWhile {_ < 3}).toList //> res9: List[Int] = List(4, 5)
Stream(1,2,3,4,5).tail //> res10: ch5.stream.Stream[Int] = ch5.stream$Stream$$anon$2@337d0578
(Stream(1,2,3,4,5).tail).toList //> res11: List[Int] = List(2, 3, 4, 5)
Stream(1,2,3,4,5).headOption //> res12: Option[Int] = Some(1)
前面提到过List的折叠算法无法着中途跳出,而Stream通过“延后计算”(lazy evaluation)是可以实现提早终结计算的。我们先看看Stream的右折叠(foldRight)算法:
def foldRight[B](z: B)(op: (A, => B) => B): B = {
uncons match {
case None => z
case Some((h,t)) => op(h,t.foldRight(z)(op))
}
}
这个与List的foldRight简直一模样嘛,不同的只有op函数的第二个参数是延后计算的 => B。秘密就在这个延后计算的B上。看看下面图示:
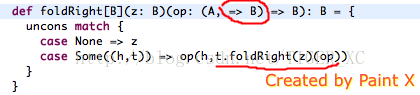
由于op的第二个参数B是延后计算的,那么t.foldRight(z)(op)这个表达式的计算就是延后的,系统可以决定先不计算这个表达式从而得到了一个中间停顿的结果。
函数exists是在碰到第一个符合条件的元素时马上终止的。我们通常使用递归算法来实现exists的这个特性。现在我们也可以用右折叠算法达到同样效果:
def exists(p: A => Boolean): Boolean = {
foldRight(false){(a,b) => p(a) || b }
}
注意:当p(a)=true时系统不再运算b,所以整个运算停了下来。
同样,用foldRight来实现forAll:
def forAll(p: A => Boolean): Boolean = {
foldRight(true){(a,b) => p(a) && b}
}
当我们遇到数据结构只能存一个元素如Option,Either时我们用map2来对接两个结构。当我们遇到能存多个元素的数据结构如List,Tree时我们就会用append来对接。Stream是一个多元素的数据结构,我们需要实现append:
//把两个Stream连接起来
def append[B >: A](b: Stream[B]): Stream[B] = {
uncons match {
case None => b
case Some((h,t)) => cons(h, t.append(b))
}
}
//append简写
def #++[B >: A](b: Stream[B]): Stream[B] = append(b)
(Stream(1,2) #++ Stream(3,4,5)).toList //> res14: List[Int] = List(1, 2, 3, 4, 5)
标准装备函数实现:
//用递归算法
def flatMap[B](f: A => Stream[B]): Stream[B] = {
uncons match {
case None => empty
case Some((h,t)) => f(h) #++ t.flatMap(f)
}
}
//用foldRight实现
def flatMap_1[B](f: A => Stream[B]): Stream[B] = {
foldRight(empty[B]){(h,t) => f(h) #++ t}
}
//用递归算法
def filter(p: A => Boolean): Stream[A] = {
uncons match {
case None => empty
case Some((h,t)) => if(p(h)) cons(h,t.filter(p)) else t.filter(p)
}
}
//用foldRight实现
def filter_1(p: A => Boolean): Stream[A] = {
foldRight(empty[A]){(h,t) => if(p(h)) cons(h,t) else t}
}(Stream(1,2,3,4,5) map {_ + 10}).toList //> res15: List[Int] = List(11, 12, 13, 14, 15)
(Stream(1,2,3,4,5) flatMap {x => Stream(x+10)}).toList
//> res16: List[Int] = List(11, 12, 13, 14, 15)
(Stream(1,2,3,4,5) flatMap_1 {x => Stream(x+10)}).toList
//> res17: List[Int] = List(11, 12, 13, 14, 15)
(Stream(1,2,3,4,5) filter {_ < 3}).toList //> res18: List[Int] = List(1, 2)
(Stream(1,2,3,4,5) filter_1 {_ < 3}).toList //> res19: List[Int] = List(1, 2)
看来都备齐了。
我们再看看List与Stream还有什么别的值得关注的区别。先从一个List操作的例子开始:
scala> List(1,2,3,4) map (_ + 10) filter (_ % 2 == 0) map (_ * 3)
List(36,42)
根据List的特性,每个操作都会立即完成,产生一个结果List,然后接着下一个操作。我们试着约化:
List(1,2,3,4) map (_ + 10) filter (_ % 2 == 0) map (_ * 3)
List(11,12,13,14) filter (_ % 2 == 0) map (_ * 3)
List(12,14) map (_ * 3)
List(36,42)实际上这个运算遍历(traverse)了List三次。一次map操作产生了中间List(11,12,13,14),二次操作filter产生了List(12,14),三次操作map产生最终结果List(36,42)。实际上我们如果把遍历这个List的方式变一下:变成每次走一个元素,连续对这个元素进行三次操作,直到走完整个List。这样我们在一个遍历过程就可以完成全部三个操作。Stream恰好是一个元素一个元素走的,因为下面的元素处于延后计算状态。我们试着用Stream来证明:
Stream(1,2,3,4).map(_ + 10).filter(_ % 2 == 0)
(11 #:: Stream(2,3,4).map(_ + 10)).filter(_ % 2 == 0)
Stream(2,3,4).map(_ + 10).filter(_ % 2 == 0)
(12 #:: Stream(3,4).map(_ + 10)).filter(_ % 2 == 0)
12 #:: Stream(3,4).map(_ + 10).filter(_ % 2 == 0)
12 #:: (13 #:: Stream(4).map(_ + 10)).filter(_ % 2 == 0)
12 #:: Stream(4).map(_ + 10).filter(_ % 2 == 0)
12 #:: (14 #:: Stream().map(_ + 10)).filter(_ % 2 == 0)
12 #:: 14 #:: Stream().map(_ + 10).filter(_ % 2 == 0)
12 #:: 14 #:: Stream()以上的#::是cons的操作符号。














 94
94











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









