







在解析接口数据和日常的数据处理中的一些操作分析:
0x00 tostring 耗时测试
常见的分以下四种:
Integer.toString
+””
解析接口返回成Integer然后tostring
String.valueOf
List<String> tempList1 = new ArrayList<String>();
List<String> tempList2 = new ArrayList<String>();
List<String> tempList3 = new ArrayList<String>();
List<String> tempList4 = new ArrayList<String>();
int num = 65536;
long time = SystemClock.currentThreadTimeMillis();
for (int i = 0; i < 50000; i++) {
tempList1.add(Integer.toString(num));
}
long newTime = SystemClock.currentThreadTimeMillis();
Log.e("consume", String.format("%s%d%s", "花费了", newTime - time, "ms"));
for (int i = 0; i < 50000; i++) {
tempList2.add(num + "");
}
Log.e("consume", String.format("%s%d%s", "花费了", SystemClock.currentThreadTimeMillis() - newTime, "ms"));
newTime = SystemClock.currentThreadTimeMillis();
for (int i = 0; i < 50000; i++) {
tempList3.add(new Integer(num).toString());
}
Log.e("consume", String.format("%s%d%s", "花费了", SystemClock.currentThreadTimeMillis() - newTime, "ms"));
newTime = SystemClock.currentThreadTimeMillis();
for (int i = 0; i < 50000; i++) {
tempList4.add(String.valueOf(num));
}
Log.e("consume", String.format("%s%d%s", "花费了", SystemClock.currentThreadTimeMillis() - newTime, "ms"));从上到下3次测试结果:
08-29 10:39:28.852 23071-23071/com.tk.test E/consume: 花费了69ms
08-29 10:39:28.962 23071-23071/com.tk.test E/consume: 花费了106ms
08-29 10:39:29.042 23071-23071/com.tk.test E/consume: 花费了76ms
08-29 10:39:29.112 23071-23071/com.tk.test E/consume: 花费了56ms
08-29 10:39:34.672 23071-23071/com.tk.test E/consume: 花费了54ms
08-29 10:39:34.762 23071-23071/com.tk.test E/consume: 花费了82ms
08-29 10:39:34.842 23071-23071/com.tk.test E/consume: 花费了81ms
08-29 10:39:34.902 23071-23071/com.tk.test E/consume: 花费了57ms
08-29 10:42:02.852 23071-23071/com.tk.test E/consume: 花费了67ms
08-29 10:42:02.962 23071-23071/com.tk.test E/consume: 花费了103ms
08-29 10:42:03.052 23071-23071/com.tk.test E/consume: 花费了87ms
08-29 10:42:03.132 23071-23071/com.tk.test E/consume: 花费了58ms
分析结果:
笔者测试分析结果:
Integer.toString = String.valueOf (本质就是Integer.toString)> new Integer().toString (考虑了new 对象的耗时) > +”“
0x01 String 拼接的耗时测试
习惯用到了String.format,那么就来愉快的测试一下吧(╯°口°)╯(┴—┴
笔者常用的分以下三种:
String.format()
+拼接
StringBuilder
List<String> tempList1 = new ArrayList<String>();
List<String> tempList2 = new ArrayList<String>();
List<String> tempList3 = new ArrayList<String>();
int textI = 123456;
double textD = 123.456;
String textS = "123456";
char textC = 'a';
long textL = 123456;
boolean textB = true;
long time = SystemClock.currentThreadTimeMillis();
for (int i = 0; i < 50000; i++) {
tempList1.add(String.format("%d%f%s%c%d%b", textI, textD, textS, textC, textL, textB));
}
long newTime = SystemClock.currentThreadTimeMillis();
Log.e("consume", String.format("%s%d%s", "花费了", newTime - time, "ms"));
for (int i = 0; i < 50000; i++) {
tempList2.add(textI + textD + textS + textC + textL + textB);
}
Log.e("consume", String.format("%s%d%s", "花费了", SystemClock.currentThreadTimeMillis() - newTime, "ms"));
newTime = SystemClock.currentThreadTimeMillis();
StringBuilder sb;
for (int i = 0; i < 50000; i++) {
sb = new StringBuilder();
tempList3.add(sb.append(textI)
.append(textD)
.append(textS)
.append(textC)
.append(textL)
.append(textB).toString());
}
Log.e("consume", String.format("%s%d%s", "花费了", SystemClock.currentThreadTimeMillis() - newTime, "ms"));从上到下3次测试结果
08-29 11:03:58.492 23028-23028/com.tk.test E/consume: 花费了2574ms
08-29 11:03:58.822 23028-23028/com.tk.test E/consume: 花费了311ms
08-29 11:03:59.122 23028-23028/com.tk.test E/consume: 花费了293ms
08-29 11:05:20.742 23028-23028/com.tk.test E/consume: 花费了2539ms
08-29 11:05:21.002 23028-23028/com.tk.test E/consume: 花费了254ms
08-29 11:05:21.242 23028-23028/com.tk.test E/consume: 花费了237ms
08-29 11:05:50.112 23028-23028/com.tk.test E/consume: 花费了2535ms
08-29 11:05:50.362 23028-23028/com.tk.test E/consume: 花费了248ms
08-29 11:05:50.612 23028-23028/com.tk.test E/consume: 花费了247ms
哎呦我去,经常用的format 简直可以淘汰了嘛,但是我都用了那么久,就给它个明明白白的死法吧,通过跳转源码可以看到
public static String format(Locale locale, String format, Object... args) {
if (format == null) {
throw new NullPointerException("format == null");
}
int bufferSize = format.length() + (args == null ? 0 : args.length * 10);
Formatter f = new Formatter(new StringBuilder(bufferSize), locale);
return f.format(format, args).toString();
}敢情format 本质还是依赖与StringBuilder嘛,接着看具体实现的方法
private void doFormat(String format, Object... args) {
checkNotClosed();
FormatSpecifierParser fsp = new FormatSpecifierParser(format);
int currentObjectIndex = 0;
Object lastArgument = null;
boolean hasLastArgumentSet = false;
int length = format.length();
int i = 0;
while (i < length) {
// Find the maximal plain-text sequence...
int plainTextStart = i;
int nextPercent = format.indexOf('%', i);
int plainTextEnd = (nextPercent == -1) ? length : nextPercent;
// ...and output it.
if (plainTextEnd > plainTextStart) {
outputCharSequence(format, plainTextStart, plainTextEnd);
}
i = plainTextEnd;
// Do we have a format specifier?
if (i < length) {
FormatToken token = fsp.parseFormatToken(i + 1);
Object argument = null;
if (token.requireArgument()) {
int index = token.getArgIndex() == FormatToken.UNSET ? currentObjectIndex++ : token.getArgIndex();
argument = getArgument(args, index, fsp, lastArgument, hasLastArgumentSet);
lastArgument = argument;
hasLastArgumentSet = true;
}
CharSequence substitution = transform(token, argument);
// The substitution is null if we called Formattable.formatTo.
if (substitution != null) {
outputCharSequence(substitution, 0, substitution.length());
}
i = fsp.i;
}
}
}可以注意到
int nextPercent = format.indexOf(‘%’, i);
这行代码,通过while循环取得%出现的位置然后在解析成一个FormatToken对象,然后跳到一个符合条件必然会调用的方法
CharSequence substitution = transform(token, argument);
那么这行代码发生了什么,我们接着看
private CharSequence transform(FormatToken token, Object argument) {
this.formatToken = token;
this.arg = argument;
// There are only two format specifiers that matter: "%d" and "%s".
// Nothing else is common in the wild. We fast-path these two to
// avoid the heavyweight machinery needed to cope with flags, width,
// and precision.
if (token.isDefault()) {
switch (token.getConversionType()) {
case 's':
if (arg == null) {
return "null";
} else if (!(arg instanceof Formattable)) {
return arg.toString();
}
break;
case 'd':
boolean needLocalizedDigits = (localeData.zeroDigit != '0');
if (out instanceof StringBuilder && !needLocalizedDigits) {
if (arg instanceof Integer || arg instanceof Short || arg instanceof Byte) {
IntegralToString.appendInt((StringBuilder) out, ((Number) arg).intValue());
return null;
} else if (arg instanceof Long) {
IntegralToString.appendLong((StringBuilder) out, ((Long) arg).longValue());
return null;
}
}
if (arg instanceof Integer || arg instanceof Long || arg instanceof Short || arg instanceof Byte) {
String result = arg.toString();
return needLocalizedDigits ? localizeDigits(result) : result;
}
}
}
formatToken.checkFlags(arg);
CharSequence result;
switch (token.getConversionType()) {
case 'B': case 'b':
result = transformFromBoolean();
break;
case 'H': case 'h':
result = transformFromHashCode();
break;
case 'S': case 's':
result = transformFromString();
break;
case 'C': case 'c':
result = transformFromCharacter();
break;
case 'd': case 'o': case 'x': case 'X':
if (arg == null || arg instanceof BigInteger) {
result = transformFromBigInteger();
} else {
result = transformFromInteger();
}
break;
case 'A': case 'a': case 'E': case 'e': case 'f': case 'G': case 'g':
result = transformFromFloat();
break;
case '%':
result = transformFromPercent();
break;
case 'n':
result = System.lineSeparator();
break;
case 't': case 'T':
result = transformFromDateTime();
break;
default:
throw token.unknownFormatConversionException();
}
if (Character.isUpperCase(token.getConversionType())) {
if (result != null) {
result = result.toString().toUpperCase(locale);
}
}
return result;
}至此,String.format()我的理解就是更加可视化一些基本类型的拼接,比起StringBuilder的执行效率是鞭长莫及,相当与建立在StringBuilder上一个封装版。打个比方,就像ListVew大家都会继承BaseAdapter实现灵活的扩展而一般不经常去使用SimpleAdapter以及ArrayAdapter。
0x02 split 的疑惑
有的时候接口某些参数用的是特殊符号拼接,取值的时候解析起来数组的长度又是如何呢,为了以后少些冤枉的判断,这里也做了测试做记录
拿冒号为例子
String str1 = "test";
String str2 = "test:";
String str3 = ":test";
String str4 = "te:st";
String[] s1 = str1.split(":");
String[] s2 = str2.split(":");
String[] s3 = str3.split(":");
String[] s4 = str4.split(":");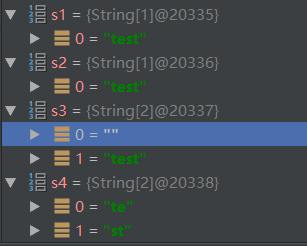
可以看到首位和末位有分割字符的时候结果长度竟然不一致(;¬_¬),当用
str2.split(“:”,2);
也就是限制长度的时候
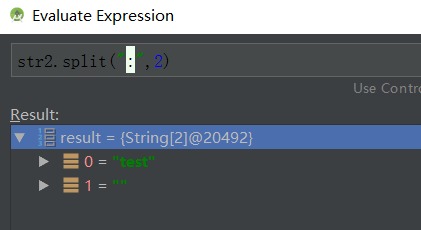

一路追踪到源码发现了这个情况
public static String[] fastSplit(String re, String input, int limit) {
// Can we do it cheaply?
int len = re.length();
if (len == 0) {
return null;
}
char ch = re.charAt(0);
if (len == 1 && METACHARACTERS.indexOf(ch) == -1) {
// We're looking for a single non-metacharacter. Easy.
} else if (len == 2 && ch == '\\') {
// We're looking for a quoted character.
// Quoted metacharacters are effectively single non-metacharacters.
ch = re.charAt(1);
if (METACHARACTERS.indexOf(ch) == -1) {
return null;
}
} else {
return null;
}
// We can do this cheaply...
// Unlike Perl, which considers the result of splitting the empty string to be the empty
// array, Java returns an array containing the empty string.
if (input.isEmpty()) {
return new String[] { "" };
}
// Count separators
int separatorCount = 0;
int begin = 0;
int end;
while (separatorCount + 1 != limit && (end = input.indexOf(ch, begin)) != -1) {
++separatorCount;
begin = end + 1;
}
int lastPartEnd = input.length();
if (limit == 0 && begin == lastPartEnd) {
// Last part is empty for limit == 0, remove all trailing empty matches.
if (separatorCount == lastPartEnd) {
// Input contains only separators.
return EmptyArray.STRING;
}
// Find the beginning of trailing separators.
do {
--begin;
} while (input.charAt(begin - 1) == ch);
// Reduce separatorCount and fix lastPartEnd.
separatorCount -= input.length() - begin;
lastPartEnd = begin;
}
// Collect the result parts.
String[] result = new String[separatorCount + 1];
begin = 0;
for (int i = 0; i != separatorCount; ++i) {
end = input.indexOf(ch, begin);
result[i] = input.substring(begin, end);
begin = end + 1;
}
// Add last part.
result[separatorCount] = input.substring(begin, lastPartEnd);
return result;
}在这个地方
while (separatorCount + 1 != limit && (end = input.indexOf(ch, begin)) != -1) {
++separatorCount;
begin = end + 1;
}当 reg 为test: 时,执行split(“:”),默认limit为0,会执行一次如上循环。
separatorCount 变成1
end 变成4
begin 变成 5
接着符合条件执行了如下方法
if (limit == 0 && begin == lastPartEnd) {
// Last part is empty for limit == 0, remove all trailing empty matches.
if (separatorCount == lastPartEnd) {
// Input contains only separators.
return EmptyArray.STRING;
}
// Find the beginning of trailing separators.
do {
--begin;
} while (input.charAt(begin - 1) == ch);
// Reduce separatorCount and fix lastPartEnd.
separatorCount -= input.length() - begin;
lastPartEnd = begin;
}begin 变成了4, 然后separatorCount 变成了0(有点迷),最后返回的result 长度等于separatorCount +1,所以返回了1位长度的result[] 也就是Test ,但是当我们传入 split(“:”,2)会怎么样呢?
while循环还是执行一次,separatorCount 还是变成了1,但是由于不满足这个条件
limit == 0 && begin == lastPartEnd
所以没有执行后续的do-while循环,separatorCount也没有发生变化,所以最后返回的result长度是2,也就是{“Test”,“”} 。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









